python爬虫之selenium库的安装及使用教程
第一步:python中安装selenium库
和其他所有Python库一样,selenium库需要安装
pip install selenium # Windows电脑安装selenium pip3 install selenium # Mac电脑安装selenium
第二步:下载谷歌浏览器驱动并合理放置
selenium的脚本可以控制所有常见浏览器,在使用之前需要安装浏览器端的驱动
注意:驱动和浏览器要版本对应
推荐使用Chrome浏览器:谷歌浏览器驱动
打开chrome浏览器,在网址栏中输入chrome://version/打开关于版本页面,根据版本信息下载相应chrome驱动

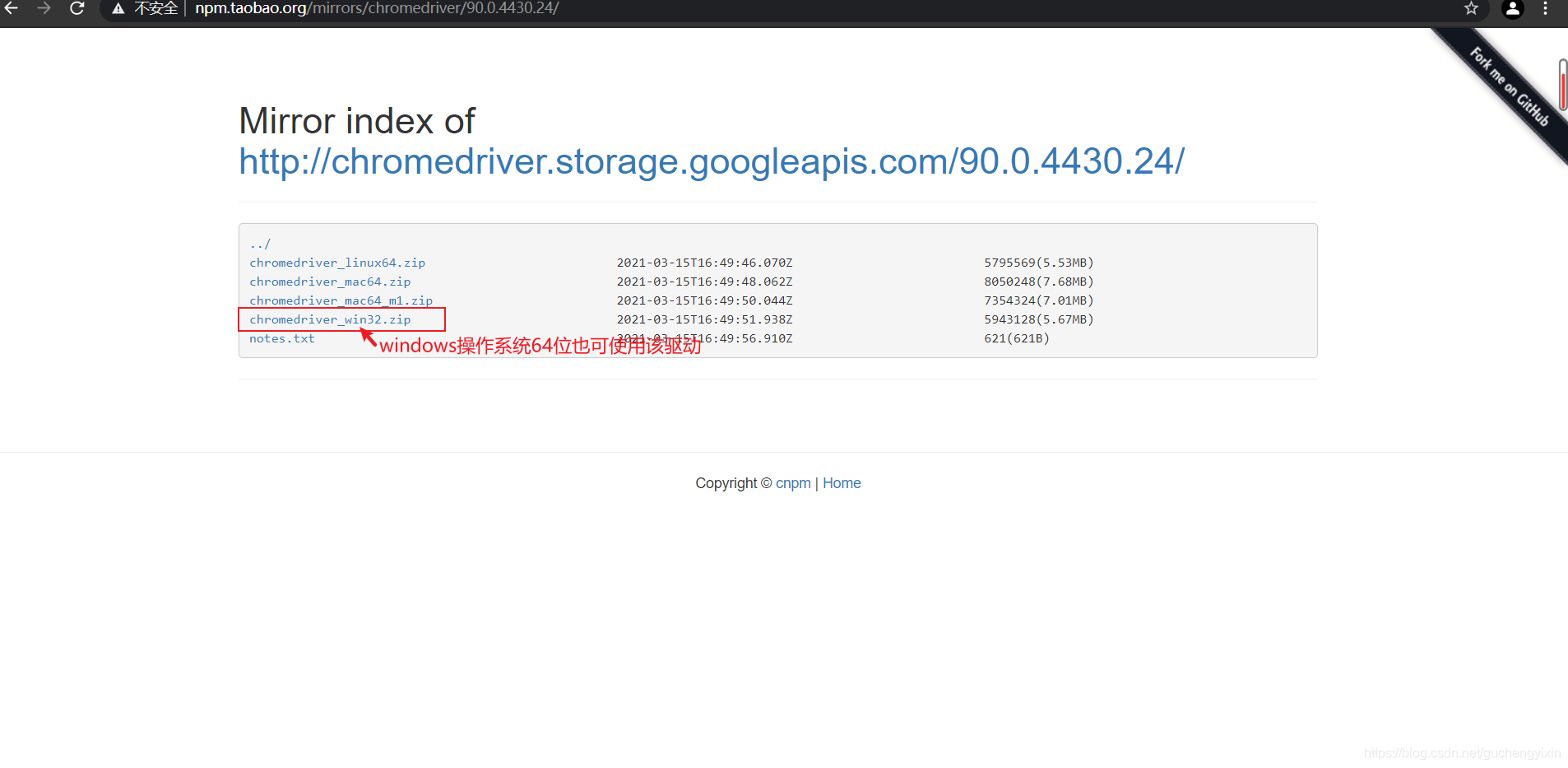
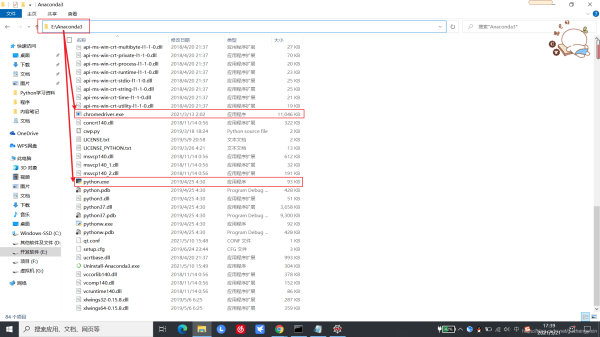
将驱动放在python的安装目录(我的python集成在Anaconda3)
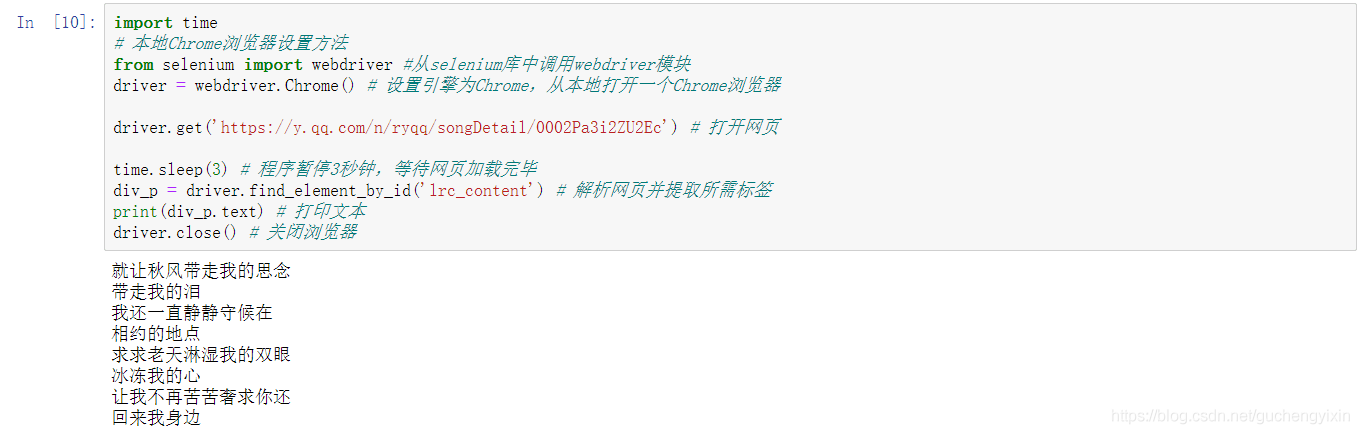
第三步:使用selenium爬取QQ音乐歌词(简单示例)
import time
# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,从本地打开一个Chrome浏览器
driver.get('https://y.qq.com/n/ryqq/songDetail/0002Pa3i2ZU2Ec') # 打开网页
time.sleep(3) # 程序暂停3秒钟,等待网页加载完毕
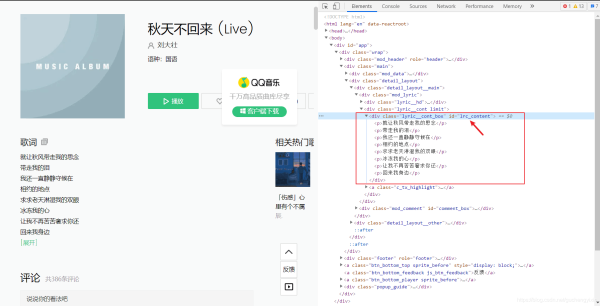
div_p = driver.find_element_by_id('lrc_content') # 解析网页并提取所需标签
print(div_p.text) # 打印文本
driver.close() # 关闭浏览器
到此这篇关于python爬虫之selenium库的安装及使用教程的文章就介绍到这了,更多相关selenium库的安装使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python中Selenium库使用教程详解
selenium介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转.输入.点击.下拉等,来拿到网页渲染之后的结果,可支持多种浏览器 中文参考文档 官网 环境安装 下载安装selenium pip install selenium -i https://mirrors.aliyun.com/pypi/simple/ 谷歌浏览器驱动程序下载地址:
-
Python中selenium库的用法详解
selenium主要是用来做自动化测试,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题. 模拟浏览器进行网页加载,当requests,urllib无法正常获取网页内容的时候 一.声明浏览器对象 注意点一,Python文件名或者包名不要命名为selenium,会导致无法导入 from selenium import webdriver #webdriver可以认为是浏览器的驱动器,要驱动浏览器必须用到webdriver,支持多种浏览器,这里以Chrome为例 browser = w
-
python中selenium库的基本使用详解
什么是selenium selenium 是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等.selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid). S
-
Python爬虫之Selenium库的使用方法
Selenium 是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等.这个工具的主要功能包括:测试与浏览器的兼容性--测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上.测试系统功能--创建回归测试检验软件功能和用户需求.支持自动录制动作和自动生成 .Net.Java.Perl等不同语言的测试
-
全网最全python库selenium自动化使用详细教程
一.安装selenium pip install Selenium 二.初始化浏览器 Chrome 是初始化谷歌浏览器 Firefox 是初始化火狐浏览器 Edge 是初始化IE浏览器 PhantomJS 是一个无界面浏览器. from selenium import webdriver driver = webdriver.Chrome() 三.设置浏览器大小 maximize_window 最大化窗口 set_window_size 自定义窗口大小 from selenium import
-

python Selenium爬取内容并存储至MySQL数据库的实现代码
前面我通过一篇文章讲述了如何爬取CSDN的博客摘要等信息.通常,在使用Selenium爬虫爬取数据后,需要存储在TXT文本中,但是这是很难进行数据处理和数据分析的.这篇文章主要讲述通过Selenium爬取我的个人博客信息,然后存储在数据库MySQL中,以便对数据进行分析,比如分析哪个时间段发表的博客多.结合WordCloud分析文章的主题.文章阅读量排名等. 这是一篇基础性的文章,希望对您有所帮助,如果文章中出现错误或不足之处,还请海涵.下一篇文章会简单讲解数据分析的过程. 一. 爬取的结果 爬
-
Python Selenium库的基本使用教程
(一)Selenium基础 入门教程:Selenium官网教程 1.Selenium简介 Selenium是一个用于测试网站的自动化测试工具,支持各种浏览器包括Chrome.Firefox.Safari等主流界面浏览器,同时也支持phantomJS无界面浏览器. 2.支持多种操作系统 如Windows.Linux.IOS.Android等. 3.安装Selenium pip install Selenium 4.安装浏览器驱动 Selenium3.x调用浏览器必须有一个webdriver驱动文件
-
python Selenium 库的使用技巧
Selenium 是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE,Mozilla Firefox,Safari,Google Chrome,Opera等.这个工具的主要功能包括:测试与浏览器的兼容性--测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上.测试系统功能--创建回归测试检验软件功能和用户需求.支持自动录制动作和自动生成 .Net.Java.Perl等不同语言的测试脚本. -- 百度百科 首先下载驱
-
python爬虫之selenium库的安装及使用教程
第一步:python中安装selenium库 和其他所有Python库一样,selenium库需要安装 pip install selenium # Windows电脑安装selenium pip3 install selenium # Mac电脑安装selenium 第二步:下载谷歌浏览器驱动并合理放置 selenium的脚本可以控制所有常见浏览器,在使用之前需要安装浏览器端的驱动 注意:驱动和浏览器要版本对应 推荐使用Chrome浏览器:谷歌浏览器驱动 打开chrome浏览器,在网址栏中输入
-
python 爬虫之selenium可视化爬虫的实现
之所以把selenium爬虫称之为可视化爬虫 主要是相较于前面所提到的几种网页解析的爬虫方式 selenium爬虫主要是模拟人的点击操作 selenium驱动浏览器并进行操作的过程是可以观察到的 就类似于你在看着别人在帮你操纵你的电脑,类似于别人远程使用你的电脑 当然了,selenium也有无界面模式 快速入门 selenium基本介绍: selenium 是一套完整的web应用程序测试系统, 包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Contro
-
Python爬虫之Selenium实现关闭浏览器
前言:WebDriver提供了两个关闭浏览器的方法,一个是前边使用quit()方法,另一个是close()方法 close():关闭当前窗口 quit():关闭所有窗口 quit()是关闭所有窗口,就不过多说了,测试一下close() from selenium import webdriver from selenium.webdriver.common.keys import Keys import time driver = webdriver.Chrome() driver.get("h
-
Python爬虫之Selenium实现窗口截图
前言:由程序去执行的操作不允许有任何误差,有些时候在测试的时候未出现问题,但是放到服务器上就会报错,而且打印的错误信息并不十分明确.这时,我在想如果在脚本执行出错的时候能对当前窗口截图保存,那么通过图片就可以非常直观地看出出错的原因.WebDriver提供了截图函数get_screenshot_as_file()来截取当前窗口. 本章中用到的关键方法如下: get_screenshot_as_file():截图 from selenium import webdriver driver = we
-
Python爬虫之Selenium设置元素等待的方法
一.显式等待 WebDriverWait类是由WebDirver 提供的等待方法.在设置时间内,默认每隔一段时间检测一次当前页面元素是否存在,如果超过设置时间检测不到则抛出异常(TimeoutException) from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from seleniu
-
Python爬虫中Selenium实现文件上传
前言:大部分的文件上传功能都是用input标签实现,这样就完全可以把它看作一个输入框,可以通过send_keys()指定文件进行上传了. 本章中用到的关键方法如下: send_keys():上传文件或者输入文本 from selenium import webdriver import time driver = webdriver.Chrome() driver.get('http://file.yiyuen.com/file/') # 定位上传按钮,添加本地文件 driver.find_el
-
Python爬虫之Selenium下拉框处理的实现
在我们浏览网页的时候经常会碰到下拉框,WebDriver提供了Select类来处理下拉框,详情请往下看: 本章中用到的关键方法如下: select_by_value():设置下拉框的值 switch_to.alert.accept():定位并接受现有警告框(详情请参考Python爬虫 - Selenium(9)警告框(弹窗)处理) click():鼠标点击事件(其他鼠标事件请参考Python爬虫 - Selenium(5)鼠标事件) move_to_element():鼠标悬停(详情请参考Pyt
-
Python爬虫之Selenium警告框(弹窗)处理
JavaScript 有三种弹窗 Alert (只有确定按钮), Confirmation (确定,取消等按钮), Prompt (有输入对话框),而且弹出的窗口是不能通过前端工具对其进行定位的,这个时候就可以通过switch_to.alert方法来定位这个弹窗,并进行一系列的操作. 本章中用到的关键方法如下: switch_to.alert:定位到警告框 text:获取警告框中的文字信息 accept():接受现有警告框(相当于确认) dismiss():解散现有警告框(相当于取消) send
-
Python爬虫之Selenium中frame/iframe表单嵌套页面
在Web应用中经常会遇到frame/iframe表单嵌套页面的应用,WebDriver只能在一个页面上对元素识别与定位,对于frame/iframe表单内嵌页面上的元素无法直接定位.这时就需要通过switch_to.frame()方法将当前定位的主体切换为frame/iframe表单的内嵌页面中. 本章中用到的关键方法如下: switch_to.frame():切换为frame/iframe表单的内嵌页面中 switch_to.parent_frame():退出内嵌页面 以ip138网站为例 f