教你怎么用python selenium实现自动化测试
一、安装selenium
打开命令控制符输入:pip install -U selenium
火狐浏览器安装firebug:www.firebug.com,调试所有网站语言,调试功能
Selenium IDE 是嵌入到Firefox 浏览器中的一个插件,实现简单的浏览器操 作的录制与回放功能,IDE 录制的脚本可以可以转换成多种语言,从而帮助我们快速的开发脚本,下载地址:https://addons.mozilla.org/en-US/firefox/addon/selenium-ide/
如何使用IDE录制脚本:点击seleniumIDE——点击录制——开始录制——录制完成后点击文件Export Test Case——python/unittest/Webdriver——保存;
二、安装python
安装的时候,推荐选择“Add exe to path”,将会自动添加Python的程序到环境变量中。然后可以在命令行输入 python -V 检测安装的Python版本。
浏览器内壳:IE、chrome、FireFox、Safari
1、webdriver:用unittest框架写自动化用例(setUp:前置条件,tearDown清场)
import unittest
from selenium import webdriver
class Ranzhi(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox() #选择火狐浏览器
def test_ranzhi(self):
pass
def tearDown(self):
self.driver.quit()#退出浏览器
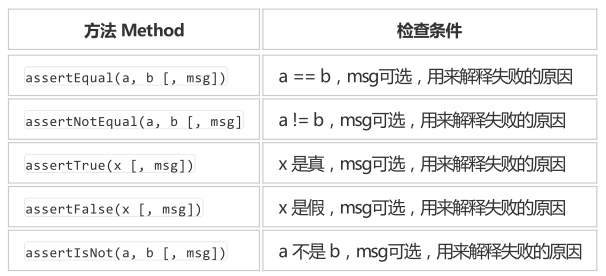
2、断言,检查跳转的网页是否和实际一致
断言网址时需注意是否为伪静态(PATH_INFO)或者GET,前者采用路径传参数(sys/user-creat.html),后者通过字符查询传参数(sys/index.php?m=user&f=index)
当采用不同方式校验网址会发现变化。
self.assertEqual("http://localhost:8080/ranzhi/www/s/index.php?m=index&f=index",
self.driver.current_url, "登录跳转失败")
3、定位元素,在html里面,元素具有各种各样的属性。我们可以通过这样唯一区别其他元素的属性来定位到这个元素.
WebDriver提供了一系列的元素定位方法。常见的有以下几种:id,name,link text,partial link text,xpath,css seletor,class,tag.
self.driver.find_element_by_xpath('//*[@id="s-menu-superadmin"]/button').click()
self.driver.find_element_by_id('account').send_keys('admin')
self.driver.find_element_by_link_text(u'退出').click()
定位元素需注意的问题:
a.时间不够,采用两种方式(self.implicitly_wait(30),sleep(2))
b.函数嵌套(<iframe></iframe>)
# 进入嵌套
self.driver.switch_to.frame('iframe-superadmin')
#退出嵌套
self.driver.switch_to.default_content()
c.flash,验证码(关闭验证码或使用万能码)
d.xpath问题:最好采用最简xpath,当xpath中出现li[10]等时需注意,有时页面定位会出现问题
4、采用CSV存数据
CSV:以纯文本形式存储表格数据(数字和文本),CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。大量程序都支持某种CSV变体,至少是作为一种可选择的输入/输出格式。
melody101,melody101,m,1,3,123456,@qq.com melody102,melody101,f,2,5,123456,@qq.com melody103,melody101,m,3,2,123456,@qq.com
import csv
# 读取CSV文件到user_list字典类型变量中
user_list = csv.reader(open("list_to_user.csv", "r"))
# 遍历整个user_list
for user in user_list:
sleep(2)
self.logn_in('admin', 'admin')
sleep(2)
# 读取一行csv,并分别赋值到user_to_add 中
user_to_add = {'account': user[0],
'realname': user[1],
'gender': user[2],
'dept': user[3],
'role': user[4],
'password': user[5],
'email': user[0] + user[6]}
self.add_user(user_to_add)
5、对下拉列表的定位采用select标签
from selenium.webdriver.support.select import Select
# 选择部门
dp =self.driver.find_element_by_id('dept')
Select(dp).select_by_index(user['dept'])
# 选择角色
Select(self.driver.find_element_by_id('role')).select_by_index(user['role'])
6、模块化代码
需要对自动化重复编写的脚本进行重构(refactor),将重复的脚本抽取出来,放到指定的代码文件中,作为共用的功能模块。使用模块化代码注意需倒入该代码。
#模块化代码后引用,需导入代码模块 from ranzhi_lib import RanzhiLib self.lib = RanzhiLib(self.driver) # 点击后台管理 self.lib.click_admin_app() sleep(2) # 点击添加用户 self.lib.click_add_user() # 添加用户 self.lib.add_user(user_to_add) sleep(1) # 退出 self.lib.logn_out() sleep(2)
7、自定义函数运行的先后顺序:完整的单元测试很少只执行一个测试用例,开发人员通常都需要编写多个测试用例才能对某一软件功能进行比较完整的测试,这些相关的测试用例称为一个测试用例集,在PyUnit中是用TestSuite类来表示,采用unittest.TestSuite()。
PyUnit使用TestRunner类作为测试用例的基本执行环境,来驱动整个单元测试过程。Python开发人员在进行单元测试时一般不直接使用TestRunner类,而是使用其子类TextTestRunner来完成测试。
# 构造测试集
suite = unittest.TestSuite()
suite.addTest(RanzhiTest("test_login"))
suite.addTest(RanzhiTest("test_ranzhi"))
# 执行测试
runner = unittest.TextTestRunner()
runner.run(suite)
以下代码为登录“然之系统”,进入添加用户,循环添加用户并检测添加成功,再退出的过程。以下程序分别为主程序,模块化程序,执行程序,CSV文件
import csv
import unittest
from time import sleep
from selenium import webdriver
# 模块化代码后引用需导入代码模块
from ranzhi_lib import RanzhiLib
class Ranzhi(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.lib = RanzhiLib(self.driver)
# 主函数
def test_ranzhi(self):
# 读取CSV文件到user_list字典类型变量中
user_list = csv.reader(open("list_to_user.csv", "r"))
# 遍历整个user_list
for user in user_list:
sleep(2)
self.lib.logn_in('admin', 'admin')
sleep(2)
# 断言
self.assertEqual("http://localhost:8080/ranzhi/www/sys/index.html",
self.driver.current_url,
'登录跳转失败')
# 读取一行csv,并分别赋值到user_to_add 中
user_to_add = {'account': user[0],
'realname': user[1],
'gender': user[2],
'dept': user[3],
'role': user[4],
'password': user[5],
'email': user[0] + user[6]}
# 点击后台管理
self.lib.click_admin_app()
# 进入嵌套
self.lib.driver.switch_to.frame('iframe-superadmin')
sleep(2)
# 点击添加用户
self.lib.click_add_user()
# 添加用户
self.lib.add_user(user_to_add)
# 退出嵌套
self.driver.switch_to.default_content()
sleep(1)
# 退出
self.lib.logn_out()
sleep(2)
# 用新账号登录
self.lib.logn_in(user_to_add['account'], user_to_add['password'])
sleep(2)
self.lib.logn_out()
sleep(2)
def tearDown(self):
self.driver.quit()
from time import sleep
from selenium.webdriver.support.select import Select
class RanzhiLib():
# 构造方法
def __init__(self, driver):
self.driver = driver
# 模块化添加用户
def add_user(self, user):
driver = self.driver
# 添加用户名
ac = driver.find_element_by_id('account')
ac.send_keys(user['account'])
# 真实姓名
rn = driver.find_element_by_id('realname')
rn.clear()
rn.send_keys(user['realname'])
# 选择性别
if user['gender'] == 'm':
driver.find_element_by_id('gender2').click()
elif user['gender'] == 'f':
driver.find_element_by_id('gender1').click()
# 选择部门
dp = driver.find_element_by_id('dept')
Select(dp).select_by_index(user['dept'])
# 选择角色
role = driver.find_element_by_id('role')
Select(role).select_by_index(user['role'])
# 输入密码
pwd1 = driver.find_element_by_id('password1')
pwd1.clear()
pwd1.send_keys(user['password'])
pwd2 = driver.find_element_by_id('password2')
pwd2.send_keys(user['password'])
# 输入邮箱
em = driver.find_element_by_id('email')
em.send_keys(user['email'])
# 点击保存
driver.find_element_by_id('submit').click()
sleep(2)
# 登录账号
def logn_in(self, name, password):
driver = self.driver
driver.get('http://localhost:8080/ranzhi/www')
sleep(2)
driver.find_element_by_id('account').clear()
driver.find_element_by_id('account').send_keys(name)
driver.find_element_by_id('password').clear()
driver.find_element_by_id('password').send_keys(password)
driver.find_element_by_id('submit').click()
sleep(2)
# 退出账号
def logn_out(self):
self.driver.find_element_by_id('start').click()
sleep(4)
self.driver.find_element_by_link_text(u'退出').click()
sleep(3)
# 点击后台管理
def click_admin_app(self):
self.driver.find_element_by_xpath('//*[@id="s-menu-superadmin"]/button').click()
sleep(1)
def click_add_user(self):
self.driver.find_element_by_xpath('//*[@id="shortcutBox"]/div/div[1]/div/a/h3').click()
sleep(3)
import unittest
from ranzhi import Ranzhi
class RanzhiTestRunner():
def run_tests(self):
suite = unittest.TestSuite()
suite.addTest(Ranzhi('test_ranzhi'))
runner = unittest.TextTestRunner()
runner.run(suite)
if __name__ == "__main__":
ranzhi_test_runner = RanzhiTestRunner()
ranzhi_test_runner.run_tests()
到此这篇关于教你怎么用python selenium实现自动化测试的文章就介绍到这了,更多相关selenium实现自动化测试内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python+Selenium自动化测试——输入,点击操作
这是我的第一个真正意思上的自动化脚本. 1.练习的测试用例为: 打开百度首页,搜索"胡歌",然后检索列表,有无"胡歌的新浪微博"这个链接 2.在写脚本之前,需要明确测试的步骤,具体到每个步骤需要做什么,既拆分测试场景,考虑好之后,再去写脚本. 此测试场景拆分如下: 1)启动Chrome浏览器 2)打开百度首页,https://www.baidu.com 3)定位搜索输入框,输入框元素XPath表达式://*[@id="kw"] 4)定位搜索提交按
-

浏览器常用基本操作之python3+selenium4自动化测试(基础篇3)
1.打开指定的网页地址 我们使用selenium进行自动化测试时,打开浏览器之后,第一步就是让浏览器访问我们指定的地址,可使用get方法实现 from selenium import webdriver driver = webdriver.Edge() driver.get('https://www.baidu.com/') # 本行用于访问指定的地址 2.获取当前页面url 我们在测试过程中,有时需要获取当前页面的url以判断是否跳转到指定页面,获取页面url的方法如下: from sele
-
Python selenium自动化测试模型图解
1.线性测试 优势:每一个脚本都是完整独立的,每一个脚本对应一个测试用例 缺点:开发成本高,会有重复操作重复脚本:维护成本也高,修改重复操作的脚本时,要逐一进行修改. 2.模块化驱动测试 把重复的操作独立成公共模块,当用例执行中需要这一模块操作时调用,这样最大限度的消除重复,提高测试用例的可维护性. 解决了线性测试的两个问题: (1)提高了开发效率 (2)简化了维护复杂性 缺点:在数据会改变的情况下,会加大编写重复的脚本(比如现在我要测试不同用户登录的场景,先是张三登录,登录完后换李四登录,然后
-
selenium+python实现基本自动化测试的示例代码
安装selenium 打开命令控制符输入:pip install -U selenium 火狐浏览器安装firebug:www.firebug.com,调试所有网站语言,调试功能 Selenium IDE 是嵌入到Firefox 浏览器中的一个插件,实现简单的浏览器操 作的录制与回放功能,IDE 录制的脚本可以可以转换成多种语言,从而帮助我们快速的开发脚本,下载地址:https://addons.mozilla.org/en-US/firefox/addon/selenium-ide/ 如何使用
-
Python3.6+selenium2.53.6自动化测试_读取excel文件的方法
环境: 编辑工具: 浏览器: 安装xlrd 安装DDT 一 分析 1 目录结构 2 导入包 二 代码 import xlrd class ExcelUtil(): def __init__(self,excelPath,sheetName="Sheet1"): self.data = xlrd.open_workbook(excelPath) self.table = self.data.sheet_by_name(sheetName) #获取第一行作为key值 self.keys =
-
Python+Selenium使用Page Object实现页面自动化测试
Page Object模式是Selenium中的一种测试设计模式,主要是将每一个页面设计为一个Class,其中包含页面中需要测试的元素(按钮,输入框,标题 等),这样在Selenium测试页面中可以通过调用页面类来获取页面元素,这样巧妙的避免了当页面元素id或者位置变化时,需要改测试页面代码的情况. 当页面元素id变化时,只需要更改测试页Class中页面的属性即可. Page Object模式是一种自动化测试设计模式,将页面定位和业务操作分开,分离测试对象(元素对象)和测试脚本(用例脚本),提高
-
python+selenium自动化框架搭建的方法步骤
环境及使用软件信息 python 3 selenium 3.13.0 xlrd 1.1.0 chromedriver HTMLTestRunner 说明: selenium/xlrd只需要再python环境下使用pip install 名称即可进行对应的安装. 安装完成后可使用pip list查看自己的安装列表信息. chromedriver:版本需和自己的chrome浏览器对应,百度下载. 作用:对chrome浏览器进行驱动. HTMLTestRunner:HTMLTestRunner是Pyt
-
使用Python+selenium实现第一个自动化测试脚本
最近在学web自动化,记录一下学习过程. 此处我选用python3.6+selenium3.0,均用最新版本,以适应未来需求. 环境:windows10,64位 一.安装python python官方下载地址:https://www.python.org/downloads/ 进入页面就有两个版本的下载选择,2.x版本和3.x版本,或者根据系统选择对应版本. 点击Windows,跳转到Windows版本页面: 点选Python3.6.0版本,进入3.6版本页面,拉到页面下方,找到files 选择
-
python3 selenium自动化测试 强大的CSS定位方法
ccs的优点:css相对xpath语法比xpath简洁,定位速度比xpath快 css的缺点:css不支持用逻辑运算符来定位,而xpath支持.css定位语法形式多样,相对xpath比较难记. css定位建议多用,这个定位方式很强大,定位速度快且准确度高.至于难记,用熟了就好了,对勤快的人来说,这不是问题. CSS_selector常用符号: # 表示id . 表示class > 表示子元素,层级 1.通过id属性定位: find_element_by_css_selector("#id的
-
selenium+python自动化测试环境搭建步骤
相对于自动化测试工具QTP来说,selenium小巧.免费,而且兼容Google.FireFox.IE多种浏览器,越来越多的人开始使用selenium进行自动化测试. 我是使用的python 2.7,下面说一下selenium+Python的自动化测试环境搭建. 安装Python环境,从python官网下载安装包 双击安装包,进行安装 可以选择python的安装目录,按步骤安装,直至完成. 在早期的版本中,需要单独安装setuptools和pip,在新的python安装包版本中已经集成了setu