pandas组内排序,并在每个分组内按序打上序号的操作
问题:
pandas组内排序,并在每个分组内按序打上序号
描述:
pandas dataframe 对dep_id组内的salary排序。希望给下面原本只有前三列的dataframe,添加上第四列。
等价于sql里的排序函数 row_number() over() 功能

假设我已经建好了仅有前三列的dataframe,数据集命名为 MyData,
解决方案如下:
MyData['sort_id'] = MyData['salary'].groupby(MyData['dep_id']).rank()
结果如下:

补充:Pandas.DataFrame实现分组、排序并且为分组插入排名
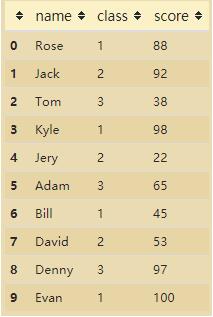
1. 示例数据(各班级学生得分)
import pandas as pd
data_dict = {"name":
["Rose", "Jack", "Tom", "Kyle", "Jery", "Adam", "Bill", "David", "Denny", "Evan"],
"class": [1, 2, 3, 1, 2, 3, 1, 2, 3, 1],
"score": [88, 92, 38, 98, 22, 65, 45, 53, 97, 100]}
df = pd.DataFrame(data=data_dict)
df
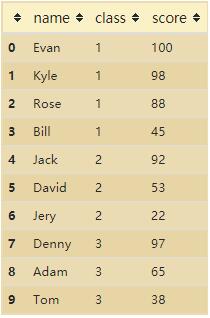
2. 按班级分组
df = df.groupby('class', sort=False)\
.apply(lambda x:x.sort_values("score", ascending=False))\
.reset_index(drop=True)
df
3. 给各分组班级增加排名列
df["rank"] = None
# 标识班级
flag = df.loc[0].values[1]
rank = 0
for i in range(len(df)):
temp = df.loc[i].values[1]
if (temp == flag).all():
# 同一班级
rank += 1
else:
# 不同班级,重新计算排名
flag = temp
rank = 1
df.loc[i, "rank"] = rank
df

以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
pandas的排序和排名的具体使用
有的时候我们可以要根据索引的大小或者值的大小对Series和DataFrame进行排名和排序. 一.排序 pandas提供了sort_index方法可以根据行或列的索引按照字典的顺序进行排序 a.Series排序 1.按索引进行排序 #定义一个Series s = Series([1,2,3],index=["a","c","b"]) #对Series的索引进行排序,默认是升序 print(s.sort_index()) ''' a 1 b 3
-
pandas groupby分组对象的组内排序解决方案
问题: 根据数据某列进行分组,选择其中另一列大小top-K的的所在行数据 解析: 求解思路很清晰,即先用groupby对数据进行分组,然后再根据分组后的某一列进行排序,选择排序结果后的top-K结果 案例: 取一下dataframe中B列各对象中C值最高所在的行 df = pd.DataFrame({"A": [2, 3, 5, 4], "B": ['a', 'b', 'b', 'a'], "C": [200801, 200902, 200704
-
pandas多层索引的创建和取值以及排序的实现
多层索引的创建 普通-多个index创建 在创建数据的时候加入一个index列表,这个index列表里面是多个索引列表 Series多层索引的创建方法 import pandas as pd s = pd.Series([1,2,3,4,5,6],index=[['张三','张三','李四','李四','王五','王五'], ['期中','期末','期中','期末','期中','期末']]) # print(s) s 张三 期中 1 期末 2 李四 期中 3
-
pandas按照列的值排序(某一列或者多列)
按照某一列排序 d = {'A': [3, 6, 6, 7, 9], 'B': [2, 5, 8, 0, 0]} df = pd.DataFrame(data=d) print('排序前:\n', df) ''' 排序前: A B 0 3 2 1 6 5 2 6 8 3 7 0 4 9 0 ''' res = df.sort_values(by='A', ascending=False) print('按照A列的值排序:\n', res) ''' 按照A列的值排序: A B 4 9 0 3 7
-
Pandas分组与排序的实现
一.pandas分组 1.分组运算过程:split->apply->combine 拆分:进行分组的根据 应用:每个分组运行的计算规则 合并:把每个分组的计算结果合并起来 2.分组函数 DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, observed=False, **kwargs by: 依据哪些列进行分组,值可以是:mapping
-

使用Pandas对数据进行筛选和排序的实现
筛选和排序是Excel中使用频率最多的功能,通过这个功能可以很方便的对数据表中的数据使用指定的条件进行筛选和计算,以获得需要的结果.在Pandas中通过.sort和.loc函数也可以实现这两 个功能..sort函数可以实现对数据表的排序操作,.loc函数可以实现对数据表的筛选操作.本篇文章将介绍如果通过Pandas的这两个函数完成Excel中的筛选和排序操作. 首选导入需要使用的Pandas库和numpy库,读取并创建数据表,将数据表命名为lc. import pandas as pd impo
-
pandas通过索引进行排序的示例
如下所示: import pandas as pd df = pd.DataFrame([1, 2, 3, 4, 5], index=[10, 52, 24, 158, 112], columns=['S']) df.sort_index(inplace=True) print df 以上这篇pandas通过索引进行排序的示例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Pandas之排序函数sort_values()的实现
一.sort_values()函数用途 pandas中的sort_values()函数原理类似于SQL中的order by,可以将数据集依照某个字段中的数据进行排序,该函数即可根据指定列数据也可根据指定行的数据排序. 二.sort_values()函数的具体参数 用法: DataFrame.sort_values(by='##',axis=0,ascending=True, inplace=False, na_position='last') 参数说明 参数 说明 by 指定列名(axis=0或
-
pandas组内排序,并在每个分组内按序打上序号的操作
问题: pandas组内排序,并在每个分组内按序打上序号 描述: pandas dataframe 对dep_id组内的salary排序.希望给下面原本只有前三列的dataframe,添加上第四列. 等价于sql里的排序函数 row_number() over() 功能 假设我已经建好了仅有前三列的dataframe,数据集命名为 MyData, 解决方案如下: MyData['sort_id'] = MyData['salary'].groupby(MyData['dep_id']).rank
-
python pandas 组内排序、单组排序、标号的实例
摘要:本文主要是讲解一下,如何进行排序.分为两种情况,不分组进行排序和组内进行排序.什么意思呢?具体来说,我举个栗子. ****注意**** 如果只是单纯想对某一列进行排序,而不进行打序号的话直接使用.sort_values就可以了.下文是关于如何把序号也打上的 ---------------------------- 我们有一个数据集如下: 我们下面想进行两种排序.先说第一种比较简单的也是很常用的,简单的对某一列进行排序然后添加一列序号. 例如,我们队comment_num这一列进行从大到小的
-
Python学习笔记之pandas索引列、过滤、分组、求和功能示例
本文实例讲述了Python学习笔记之pandas索引列.过滤.分组.求和功能.分享给大家供大家参考,具体如下: 解析html内容,保存为csv文件 //www.jb51.net/article/162401.htm 前面我们已经把519961(基金编码)这种基金的历史净值明细表html内容抓取到了本地,现在我们还是需要 解析html,取出相关的值,然后保存为csv文件以便pandas来统计分析. from bs4 import BeautifulSoup import os import csv
-
python Pandas中数据的合并与分组聚合
目录 一.字符串离散化示例 二.数据合并 2.1 join 2.2 merge 三.数据的分组和聚合 四.索引 总结 一.字符串离散化示例 对于一组电影数据,我们希望统计电影分类情况,应该如何处理数据?(每一个电影都有很多个分类) 思路:首先构造一个全为0的数组,列名为分类,如果某一条数据中分类出现过,就让0变为1 代码: # coding=utf-8 import pandas as pd from matplotlib import pyplot as plt import numpy as
-
Java分析Lambda表达式Stream流合并分组内对象数据合并
目录 前言 需求 代码实现 依赖引入 设计实体类 测试代码 前言 之前写过<Lambda使用——JDK8新特性>,现在有一个分组合并的需求正好拿来小试牛刀. 需求 数据出自许多接口数据,需要将几个接口数据根据省份id进行分组合并.举例说明: A接口返回List里面有值的的字段为:provinceId.field1.field2.field3 B接口返回List里面有值的的字段为:provinceId.field4.field5.field6 C接口返回List里面有值的的字段为:provinc
-
Python Pandas教程之series 上的转换操作
前言: 在转换操作中,我们执行各种操作,例如更改系列的数据类型,将系列更改为列表等.为了执行转换操作,我们有各种有助于转换的功能,例如.astype()等.tolist(). 代码#1: # 使用 astype 转换 series 数据类型的 Python 程序 # importing pandas module import pandas as pd # 从 url 读取 csv 文件 data = pd.read_csv("nba.csv") # 删除空值列以避免错误 data.d
-
postgreSQL中的内连接和外连接实现操作
测试数据: city表: create table city(id int,name text); insert into city values(0,'北京'),(1,'西安'),(2,'天津'),(3,'上海'),(4,'哈尔滨'),(5,'西藏') person表: create table person(id int,lastname char(20)); insert into person values(0,'Tom'),(2,'Lily'),(3,'Mary'),(5,'Coco'
-
pandas多级分组实现排序的方法
pandas有groupby分组函数和sort_values排序函数,但是如何对dataframe分组之后排序呢? In [70]: df = pd.DataFrame(((random.randint(2012, 2016), random.choice(['tech', 'art', 'office']), '%dk-%dk'%(random.randint(2,10), random.randint(10, 20)), '') for _ in xrange(10000)), column
-
pandas数值计算与排序方法
以下代码是基于python3.5.0编写的 import pandas food_info = pandas.read_csv("food_info.csv") # ---------------------特定列加减乘除------------------------- print(food_info["Iron_(mg)"]) div_1000 = food_info["Iron_(mg)"] / 1000 add_100 = food_in