Netty分布式行解码器逻辑源码解析
目录
- 行解码器LineBasedFrameDecoder
- 首先看其参数
- 我们跟到重载的decode方法中
- 我们看findEndOfLine(buffer)方法
这一小节了解下行解码器LineBasedFrameDecoder, 行解码器的功能是一个字节流, 以\r\n或者直接以\n结尾进行解码, 也就是以换行符为分隔进行解析
同样, 这个解码器也继承了ByteToMessageDecoder
行解码器LineBasedFrameDecoder
首先看其参数
//数据包的最大长度, 超过该长度会进行丢弃模式 private final int maxLength; //超出最大长度是否要抛出异常 private final boolean failFast; //最终解析的数据包是否带有换行符 private final boolean stripDelimiter; //为true说明当前解码过程为丢弃模式 private boolean discarding; //丢弃了多少字节 private int discardedBytes;
其中的丢弃模式, 我们会在源码中看到其中的含义
我们看其decode方法
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
Object decoded = decode(ctx, in);
if (decoded != null) {
out.add(decoded);
}
}
这里的decode方法和我们上一小节分析的decode方法一样, 调用重载的decode方法, 并将解码后的内容放到out集合中
我们跟到重载的decode方法中
protected Object decode(ChannelHandlerContext ctx, ByteBuf buffer) throws Exception {
//找这行的结尾
final int eol = findEndOfLine(buffer);
if (!discarding) {
if (eol >= 0) {
final ByteBuf frame;
//计算从换行符到可读字节之间的长度
final int length = eol - buffer.readerIndex();
//拿到分隔符长度, 如果是\r\n结尾, 分隔符长度为2
final int delimLength = buffer.getByte(eol) == '\r'? 2 : 1;
//如果长度大于最大长度
if (length > maxLength) {
//指向换行符之后的可读字节(这段数据完全丢弃)
buffer.readerIndex(eol + delimLength);
//传播异常事件
fail(ctx, length);
return null;
}
//如果这次解析的数据是有效的
//分隔符是否算在完整数据包里
//true为丢弃分隔符
if (stripDelimiter) {
//截取有效长度
frame = buffer.readRetainedSlice(length);
//跳过分隔符的字节
buffer.skipBytes(delimLength);
} else {
//包含分隔符
frame = buffer.readRetainedSlice(length + delimLength);
}
return frame;
} else {
//如果没找到分隔符(非丢弃模式)
//可读字节长度
final int length = buffer.readableBytes();
//如果朝超过能解析的最大长度
if (length > maxLength) {
//将当前长度标记为可丢弃的
discardedBytes = length;
//直接将读指针移动到写指针
buffer.readerIndex(buffer.writerIndex());
//标记为丢弃模式
discarding = true;
//超过最大长度抛出异常
if (failFast) {
fail(ctx, "over " + discardedBytes);
}
}
//没有超过, 则直接返回
return null;
}
} else {
//丢弃模式
if (eol >= 0) {
//找到分隔符
//当前丢弃的字节(前面已经丢弃的+现在丢弃的位置-写指针)
final int length = discardedBytes + eol - buffer.readerIndex();
//当前换行符长度为多少
final int delimLength = buffer.getByte(eol) == '\r'? 2 : 1;
//读指针直接移到换行符+换行符的长度
buffer.readerIndex(eol + delimLength);
//当前丢弃的字节为0
discardedBytes = 0;
//设置为未丢弃模式
discarding = false;
//丢弃完字节之后触发异常
if (!failFast) {
fail(ctx, length);
}
} else {
//累计已丢弃的字节个数+当前可读的长度
discardedBytes += buffer.readableBytes();
//移动
buffer.readerIndex(buffer.writerIndex());
}
return null;
}
}
final int eol = findEndOfLine(buffer)
这里是找当前行的结尾的索引值, 也就是\r\n或者是\n:

6-3-1
图中不难看出, 如果是以\n结尾的, 返回的索引值是\n的索引值, 如果是\r\n结尾的, 返回的索引值是\r的索引值
我们看findEndOfLine(buffer)方法
private static int findEndOfLine(final ByteBuf buffer) {
//找到/n这个字节
int i = buffer.forEachByte(ByteProcessor.FIND_LF);
//如果找到了, 并且前面的字符是-r, 则指向/r字节
if (i > 0 && buffer.getByte(i - 1) == '\r') {
i--;
}
return i;
}
这里通过一个forEachByte方法找\n这个字节, 如果找到了, 并且前面是\r, 则返回\r的索引, 否则返回\n的索引
回到重载的decode方法中:
if (!discarding) 判断是否为非丢弃模式, 默认是就是非丢弃模式, 所以进入if中
if (eol >= 0) 如果找到了换行符, 我们看非丢弃模式下找到换行符的相关逻辑:
final ByteBuf frame;
final int length = eol - buffer.readerIndex();
final int delimLength = buffer.getByte(eol) == '\r'? 2 : 1;
if (length > maxLength) {
buffer.readerIndex(eol + delimLength);
fail(ctx, length);
return null;
}
if (stripDelimiter) {
frame = buffer.readRetainedSlice(length);
buffer.skipBytes(delimLength);
} else {
frame = buffer.readRetainedSlice(length + delimLength);
}
return frame;
首先获得换行符到可读字节之间的长度, 然后拿到换行符的长度, 如果是\n结尾, 那么长度为1, 如果是\r结尾, 长度为2
if (length > maxLength) 带表如果长度超过最大长度, 则直接通过 readerIndex(eol + delimLength) 这种方式, 将读指针指向换行符之后的字节, 说明换行符之前的字节需要完全丢弃

6-3-2
丢弃之后通过fail方法传播异常, 并返回null
继续往下看, 走到下一步, 说明解析出来的数据长度没有超过最大长度, 说明是有效数据包
if (stripDelimiter) 表示是否要将分隔符放在完整数据包里面, 如果是true, 则说明要丢弃分隔符, 然后截取有效长度, 并跳过分隔符长度
将包含分隔符进行截取
以上就是非丢弃模式下找到换行符的相关逻辑
我们再看非丢弃模式下没有找到换行符的相关逻辑, 也就是非丢弃模式下, if (eol >= 0) 中的else块:
final int length = buffer.readableBytes();
if (length > maxLength) {
discardedBytes = length;
buffer.readerIndex(buffer.writerIndex());
discarding = true;
if (failFast) {
fail(ctx, "over " + discardedBytes);
}
}
return null;
首先通过 final int length = buffer.readableBytes() 获取所有的可读字节数
然后判断可读字节数是否超过了最大值, 如果超过最大值, 则属性discardedBytes标记为这个长度, 代表这段内容要进行丢弃
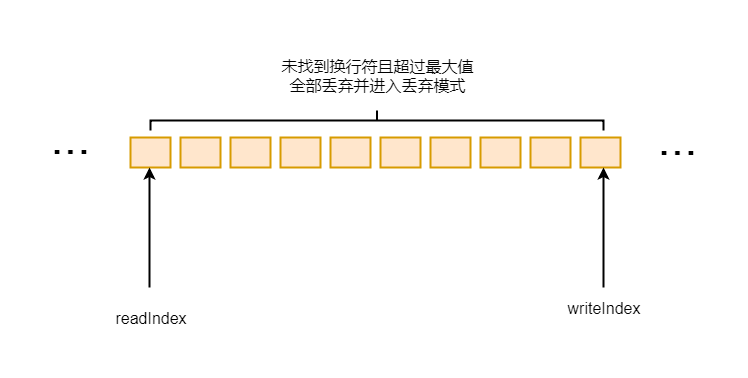
6-3-3
buffer.readerIndex(buffer.writerIndex()) 这里直接将读指针移动到写指针, 并且将discarding设置为true, 就是丢弃模式
如果可读字节没有超过最大长度, 则返回null, 表示什么都没解析出来, 等着下次解析
我们再看丢弃模式的处理逻辑, 也就是 if (!discarding) 中的else块:
首先这里也分两种情况, 根据 if (eol >= 0) 判断是否找到了分隔符, 我们首先看找到分隔符的解码逻辑:
final int length = discardedBytes + eol - buffer.readerIndex();
final int delimLength = buffer.getByte(eol) == '\r'? 2 : 1;
buffer.readerIndex(eol + delimLength);
discardedBytes = 0;
discarding = false;
if (!failFast) {
fail(ctx, length);
}
如果找到换行符, 则需要将换行符之前的数据全部丢弃掉

6-3-4
final int length = discardedBytes + eol - buffer.readerIndex()
这里获得丢弃的字节总数, 也就是之前丢弃的字节数+现在需要丢弃的字节数
然后计算换行符的长度, 如果是\n则是1, \r\n就是2
buffer.readerIndex(eol + delimLength)
这里将读指针移动到换行符之后的位置
然后将discarding设置为false, 表示当前是非丢弃状态
我们再看丢弃模式未找到换行符的情况, 也就是丢弃模式下, if (eol >= 0) 中的else块:
discardedBytes += buffer.readableBytes(); buffer.readerIndex(buffer.writerIndex());
这里做的事情非常简单, 就是累计丢弃的字节数, 并将读指针移动到写指针, 也就是将数据全部丢弃
最后在丢弃模式下, decode方法返回null, 代表本次没有解析出任何数据
以上就是行解码器的相关逻辑
以上就是Netty分布式行解码器逻辑源码解析的详细内容,更多关于Netty分布式行解码器的资料请关注我们其它相关文章!
相关推荐
-
Netty分布式ByteBuf使用的回收逻辑剖析
目录 ByteBuf回收 这里调用了release0, 跟进去 我们首先分析free方法 我们跟到cache中 回到add方法中 我们回到free方法中 前文传送门:ByteBuf使用subPage级别内存分配 ByteBuf回收 之前的章节我们提到过, 堆外内存是不受jvm垃圾回收机制控制的, 所以我们分配一块堆外内存进行ByteBuf操作时, 使用完毕要对对象进行回收, 这一小节, 就以PooledUnsafeDirectByteBuf为例讲解有关内存分配的相关逻辑 PooledUnsafe
-

Netty分布式ByteBuf使用命中缓存的分配解析
目录 分析先关逻辑之前, 首先介绍缓存对象的数据结构 我们以tiny类型为例跟到createSubPageCaches方法中 回到PoolArena的allocate方法中 我们跟到normalizeCapacity方法中 回到allocate方法中 allocateTiny是缓存分配的入口 回到acheForTiny方法中 我们简单看下Entry这个类 跟进init方法 上一小节简单分析了directArena内存分配大概流程 ,知道其先命中缓存, 如果命中不到, 则区分配一款连续内存, 这一
-
Netty分布式ByteBuf使用subPage级别内存分配剖析
目录 subPage级别内存分配 我们其中是在构造方法中初始化的, 看构造方法中其初始化代码 在构造方法中创建完毕之后, 会通过循环为其赋值 这里通过normCapacity拿到tableIdx 跟到allocate(normCapacity)方法中 我们跟到PoolSubpage的构造方法中 我们跟到addToPool(head)中 我们跟到allocate()方法中 我们继续跟进findNextAvail方法 我们回到allocate()方法中 我们跟到initBuf方法中 回到initBu
-
Netty分布式解码器读取数据不完整的逻辑剖析
目录 概述 第一节: ByteToMessageDecoder 我们看他的定义 我们看其channelRead方法 我们看cumulator属性 我们回到channRead方法中 概述 在我们上一个章节遗留过一个问题, 就是如果Server在读取客户端的数据的时候, 如果一次读取不完整, 就触发channelRead事件, 那么Netty是如何处理这类问题的, 在这一章中, 会对此做详细剖析 之前的章节我们学习过pipeline, 事件在pipeline中传递, handler可以将事件截取并对
-
Netty分布式ByteBuf使用SocketChannel读取数据过程剖析
目录 Server读取数据的流程 我们首先看NioEventLoop的processSelectedKey方法 这里会走到DefaultChannelConfig的getAllocator方法中 我们跟到static块中 回到NioByteUnsafe的read()方法中 我们跟进recvBufAllocHandle 继续看doReadBytes方法 跟到record方法中 章节总结 我们第三章分析过客户端接入的流程, 这一小节带大家剖析客户端发送数据, Server读取数据的流程: 首先温馨提
-
Netty分布式ByteBuf使用page级别的内存分配解析
目录 netty内存分配数据结构 我们看PoolArena中有关chunkList的成员变量 我们看PoolSubpage的属性 我们回到PoolArena的allocate方法 我们跟进allocateNormal 首先会从head节点往下遍历 这里直接通过构造函数创建了一个chunk 首先将参数传入的值进行赋值 我们再回到PoolArena的allocateNormal方法中 跟到allocate(normCapacity)中 我们跟到allocateNode方法中 我们跟进updatePa
-
Netty分布式行解码器逻辑源码解析
目录 行解码器LineBasedFrameDecoder 首先看其参数 我们跟到重载的decode方法中 我们看findEndOfLine(buffer)方法 这一小节了解下行解码器LineBasedFrameDecoder, 行解码器的功能是一个字节流, 以\r\n或者直接以\n结尾进行解码, 也就是以换行符为分隔进行解析 同样, 这个解码器也继承了ByteToMessageDecoder 行解码器LineBasedFrameDecoder 首先看其参数 //数据包的最大长度, 超过该长度会进
-
Nett分布式分隔符解码器逻辑源码剖析
目录 分隔符解码器 我们看其中的一个构造方法 我们跟到重载decode方法中 我们看初始化该属性的构造方法 章节总结 前文传送门:Netty分布式行解码器逻辑源码解析 分隔符解码器 基于分隔符解码器DelimiterBasedFrameDecoder, 是按照指定分隔符进行解码的解码器, 通过分隔符, 可以将二进制流拆分成完整的数据包 同样继承了ByteToMessageDecoder并重写了decode方法 我们看其中的一个构造方法 public DelimiterBasedFrameDeco
-
Netty分布式ByteBuf缓冲区分配器源码解析
目录 缓冲区分配器 以其中的分配ByteBuf的方法为例, 对其做简单的介绍 跟到directBuffer()方法中 我们回到缓冲区分配的方法 然后通过validate方法进行参数验证 缓冲区分配器 顾明思议就是分配缓冲区的工具, 在netty中, 缓冲区分配器的顶级抽象是接口ByteBufAllocator, 里面定义了有关缓冲区分配的相关api 抽象类AbstractByteBufAllocator实现了ByteBufAllocator接口, 并且实现了其大部分功能 和AbstractByt
-
Netty分布式NioEventLoop优化selector源码解析
目录 优化selector selector的创建过程 代码剖析 这里一步创建了这个优化后的数据结构 最后返回优化后的selector 优化selector selector的创建过程 在剖析selector轮询之前, 我们先讲解一下selector的创建过程 回顾之前的小节, 在创建NioEventLoop中初始化了唯一绑定的selector: NioEventLoop(NioEventLoopGroup parent, Executor executor, SelectorProvider
-
Netty分布式NioEventLoop任务队列执行源码分析
目录 执行任务队列 跟进runAllTasks方法: 我们跟进fetchFromScheduledTaskQueue()方法 回到runAllTasks(long timeoutNanos)方法中 章节小结 前文传送门:NioEventLoop处理IO事件 执行任务队列 继续回到NioEventLoop的run()方法: protected void run() { for (;;) { try { switch (selectStrategy.calculateStrategy(selectN
-
Netty启动流程注册多路复用源码解析
目录 注册多路复用 注册channel的步骤 首先看下config()方法 回到initAndRegister()方法: 跟到MultithreadEventLoopGroup的register()方法: 回顾下第二小节channel初始化的步骤: 我们继续看看register()方法: 我们重点关注register0(promise), 跟进去: 我们重点关注doRegister()这个方法 前文传送门:Netty启动流程服务端channel初始化 注册多路复用 回到上一小节的代码: fina
-
Netty分布式客户端处理接入事件handle源码解析
目录 处理接入事件创建handle 我们看其RecvByteBufAllocator接口 跟进newHandle()方法中 继续回到read()方法 我们跟进reset中 前文传送门 :客户端接入流程初始化源码分析 上一小节我们剖析完成了与channel绑定的ChannelConfig初始化相关的流程, 这一小节继续剖析客户端连接事件的处理 处理接入事件创建handle 回到上一章NioEventLoop的processSelectedKey ()方法 private void processS
-
Netty分布式ByteBuf使用的底层实现方式源码解析
目录 概述 AbstractByteBuf属性和构造方法 首先看这个类的属性和构造方法 我们看几个最简单的方法 我们重点关注第二个校验方法ensureWritable(length) 我们跟到扩容的方法里面去 最后将写指针后移length个字节 概述 熟悉Nio的小伙伴应该对jdk底层byteBuffer不会陌生, 也就是字节缓冲区, 主要用于对网络底层io进行读写, 当channel中有数据时, 将channel中的数据读取到字节缓冲区, 当要往对方写数据的时候, 将字节缓冲区的数据写到cha
-
Netty分布式ByteBuf的分类方式源码解析
目录 ByteBuf根据不同的分类方式 会有不同的分类结果 1.Pooled和Unpooled 2.基于直接内存的ByteBuf和基于堆内存的ByteBuf 3.safe和unsafe 上一小节简单介绍了AbstractByteBuf这个抽象类, 这一小节对其子类的分类做一个简单的介绍 ByteBuf根据不同的分类方式 会有不同的分类结果 我们首先看第一种分类方式 1.Pooled和Unpooled pooled是从一块内存里去取一段连续内存封装成byteBuf 具体标志是类名以Pooled开头
-
Netty组件NioEventLoopGroup创建线程执行器源码解析
目录 通过上一章的学习, 我们了解了Server启动的大致流程, 有很多组件与模块并没有细讲, 从这个章开始, 我们开始详细剖析netty的各个组件, 并结合启动流程, 将这些组件的使用场景及流程进行一个详细的说明 这一章主要学习NioEventLoop相关的知识, 何为NioEventLoop? NioEventLoop是netty的一个线程, 在上一节我们创建两个NioEventLoopGroup: EventLoopGroup bossGroup = new NioEventLoopGro