Pyhton模块和包相关知识总结
一、模块
每一个以扩展名 py 结尾额 Python 源代码文件都是一个模块模块名 同样也是一个标识符,需要符合标识符的命名规则在模块中定义的 全局变量、函数、类 都是提供给外接直接使用的工具 模块的两种导入方式
1)import 导入
import 模块名1,模块名2
或
import 模块名1 import 模块名2
导入之后
- 通过 模块名. 使用 模块提供的工具——全局变量、函数、类
使用 as 指定模块的别名
import 模块名1 as 模块别名
注意:模块别名应该 符合 大驼峰命名法
2)from…import 导入
- 如果希望从某一个模块中,导入 部分工具,就可以使用 from … import 的方式
- import 模块名 是一次性把模块中 所有工具全部导入,并且通过 模块名/别名 访问
# 从模块 导入 某一个工具 from 模块1 import 工具名
导入之后
- 不需要通过 模块名.
- 可以直接使用 模块提供的工具——全局变量、函数、类
注意:
如果 两个模块,存在同名的函数,那么后导入模块的函数,会覆盖掉先导入的函数
- 如果代码冲突,可以使用 as 关键 给其中一个模块起一个别名
from…import * (不推荐使用)
# 从模块 导入 所有工具 from 模块名1 import *
二、模块的搜索顺序
Python 的解释器在 导入模块时,会:
1.搜索 当前目录 指定模块名的文件,如果有就直接导入
2.如果没有,再搜索 系统目录
注意:在给文件起名时,不要和系统的模块文件 重名
Python 中每一个模块都有一个内置属性 __file__ 可以查看模块的 完整路径
三、使模块下方的测试代码在导入时不会执行
- 在导入文件时,文件中所有没有任何缩进的代码 都会被执行一遍
__name__属性
- __name__属性 可以做到,测试模块的代码只在测试情况下被运行,而在被导入时不会被执行
- __name__ 是 Python 的一个内置属性,记录着一个字符串
- 如果 是被其他文件导入的,__name__就是 模块名
- 如果是当前执行的程序 __name__是 __main__
示例:
# 导入模块 # 定义全局变量 # 定义类 # 定义函数 # 在代码的最下方 def main(): # ... pass # 根据 __name__判断是否执行下方代码 if __name__ == '__main__': main()
四、包
- 包是一个 包含多个模块的 特殊目录目录
- 下有一个 特殊的文件 __init__.py
- 使用 import 包名 可以一次性导入 包 中所有的模块
__init__.py
- 要在外界使用 包 中的模块,需要在 __init__.py 中指定 对外界提供的模块列表
# 从 当前目录 导入 模块列表 from . import 模块名 from . import 模块名
例如:

五、发布模块
制作发布压缩包步骤
1)创建 setup.py
setup.py 的文件
from distutils.core import setup setup(name="vvcat_package", # 包名 version="1.0", # 版本 description="用来测试", # 描述信息 long_description="用来测试如何发布压缩包", # 完整描述信息 author="vvcat", # 作者 author_email="206647497@qq.com", #作者邮箱 url="https://blog.csdn.net/qq_44989881?t=1", # 主页 py_modules=["vvcat_package.test1", "vvcat_package.test2"]) # 包中的模块
有关字典参数的详细信息,可以参阅官方网站:
https://docs.python.org/2/distutils/apiref.html


先cd到setup.py 所在的目录 ,通过 ls -l 命令 可以看到有以下几个文件

2)构建模块
python3 setup.py build

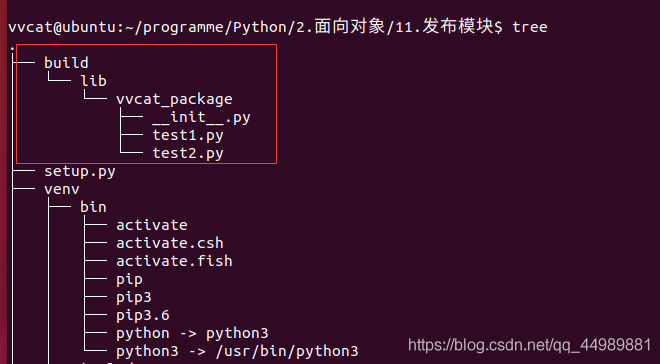
通过 tree命令可以看到当前目录结构
如果没有 tree 命令,可以通过以下操作,安装
sudo apt-get install tree
使用 tree命令 后会看到
使用 python3 setup.py build命令 生成的 build 文件夹中的内容
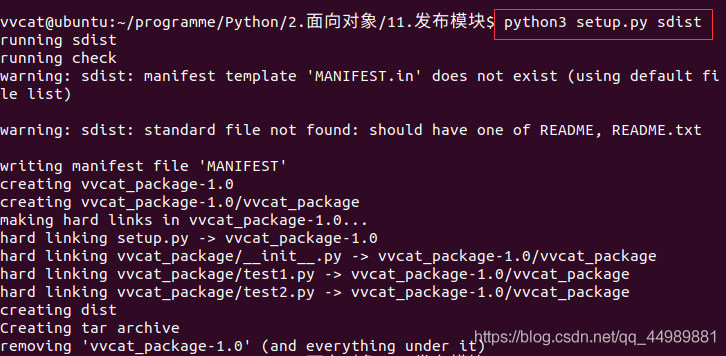
3)生成发布压缩包
python3 setup.py sdist
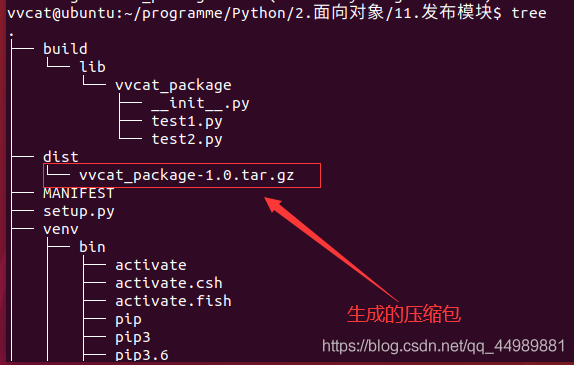
六、安装模块

tar -zxvf 包名-1.0.tar.gz sudo python3 setup.py install
使用 tar -zxvf vvcat_package-1.0.tar.gz 命令后

会出现 vvcat_package-1.0文件夹

vvcat_package-1.0文件夹中的内容

使用 cat PKG-INFO命令可以查看到 PKG-INFO文件中的内容
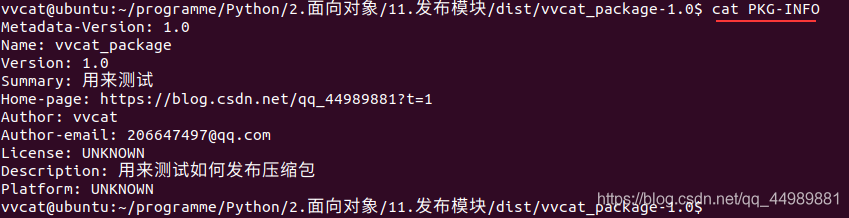
使用 sudo python3 setup.py install命令安装vvcat_package模块
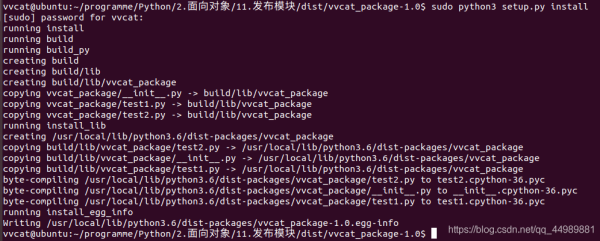
查看 vvcat_package模块安装后所在的目录,会看到以下几个文件:
vvcat_package vvcat_package-1.0.egg-info

通过 ipython3 对安装的模块进行测试


七、卸载模块
直接从安装目录下,把安装模块的目录 删除就可以
cd /usr/local/lib/python3.6/dist-package/ sudo rm -r vvcat_package*
根据以上两条命令进行如下操作:
先查看模块 安装的目录
# __file__ 用来查看模块所在的目录 vvcat_package.__file__
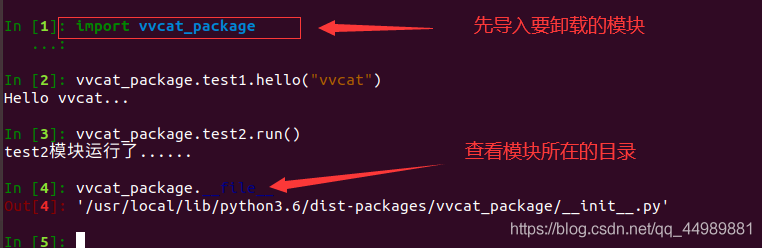
通过 cd 命令 到 dist-packages 目录下

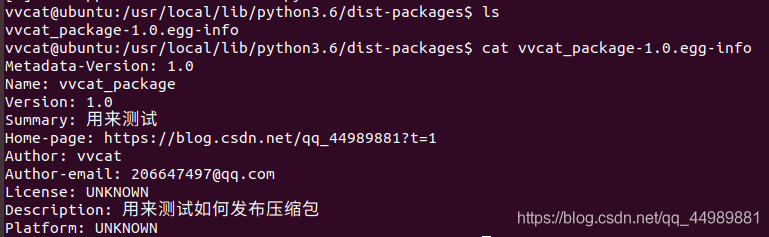
最后使用 sudo rm -r vvcat_package*命令便可以卸载掉 安装的 vvcat_package模块
以下是删除后只剩下 vvcat_package-1.0.egg-info 文件
当再次使用 ipython3 调用该模块时,会显示没有该模块。

八、pip 安装第三方模块
pip 是一个现代的,通用的 Python 包管理工具提供了对 Python 包的查找、下载、安装、卸载等功能
安装和卸载命令如下:
# 将模块安装到 Python 3.x 环境 sudo pip3 install pygame sudo pip3 uninstall pygame
在 Mac 下安装 iPython
sudo pip install ipython
在 Linux 下安装 iPython
sudo apt install ipython3
到此这篇关于Pyhton模块和包相关知识总结的文章就介绍到这了,更多相关Pyhton模块和包内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python中sys模块的介绍与实例
python版本: Python 2.7.6 1: sys是python自带模块. 利用 import 语句输入sys 模块. 当执行import sys后, python在 sys.path 变量中所列目录中寻找 sys 模块文件.然后运行这个模块的主块中的语句进行初始化,然后就可以使用模块了 . 2: sys模块常见函数 可以通过dir()方法查看模块中可用的方法. 结果如下, 很多我都没有用过, 所以只是简单介绍几个自己用过的方法. $ python Python 2.7.6 (defau
-
Python使用random模块实现掷骰子游戏的示例代码
引入内容 根据人民邮电出版社出版的<Python程序设计现代设计方法>P102习题中的第7题--掷骰子游戏,进行代码编写. 题目要求 一盘游戏中,两人轮流掷骰子5次,并将每次掷出的点数累加,5局之后,累计点数较大者获胜,点数相同则为平局.根据此规则实现掷骰子游戏,并算出50盘之后的胜利者( 50盘中嬴得盘数最多的,即最终胜利者). 审题: 共有50盘游戏.一盘游戏有5局,每一局双方各掷骰子一次,5局结束以后统计分数,分数高的一方获胜.至此,一盘游戏结束.50盘游戏结束后,赢得盘数最多的一方为最
-
Python中os模块的简单使用及重命名操作
前言 OS模块虽然基础的时候已经学过了,但是谁让本人属于那种不用立马就忘的人呢,所以在在下爬取某个不可名状的男人都喜欢的网站的时候,在遇到爬取下来的数据需要保存的时候,就需要用到OS模块了 OS模块基础回顾 先回顾一下基础 OS模块用于操作文件夹(基于我的理解) import os os.mkdir("path") # 创建该路径 然后,基础就没了,对的,我学基础OS模块的时候,就学了个这个,在当时来看,还是够用的啦 OS模块小应用 这下面就是本人在写爬虫小程序的时候用到的啦 1. 保
-
Python collections模块的使用技巧
一般来讲,python的collections是用于存储数据集合(比如列表list, 字典dict, 元组tuple和集合set)的容器.这些容器内置在Python中,可以直接使用.该collections模块提供了额外的,高性能的数据类型,可以增强你的代码,使事情变得更清洁,更容易. 让我们看一看关于集合模块最受欢迎的数据类型以及如何使用它们的教程! Counter Counter()是字典对象的子类.Counter()可接收一个可迭代遍历的对象(例如字符串.列表或元组)作为参数,并返回计数器
-

Python使用scapy模块发包收包
前言 众所周知,我们每天上网都会有很多数据包需要发送,然后处理在接受在发送,这样一个循环往复的过程 这里就显示了很多数据包的发送接收数据,那什么是包呢?下面一起看看 包( packet )是网络通信传输中的数据单位,一般称之为数据包,其主要由源地址,目标地址,净载数据组成 它包括包头和包体,包头是固定长度,包体长度不变 简单了解下包的定义,下面我们来看看发包利器 scapy 的用法吧 一.常用命令 1.ls():显示所有支持的数据包对象,可带参数也可不带,参数可以是任意具体的包 可以看出,它包含
-
python基于concurrent模块实现多线程
引言 之前也写过多线程的博客,用的是 threading ,今天来讲下 python 的另外一个自带库 concurrent .concurrent 是在 Python3.2 中引入的,只用几行代码就可以编写出线程池/进程池,并且计算型任务效率和 mutiprocessing.pool 提供的 poll 和 ThreadPoll 相比不分伯仲,而且在 IO 型任务由于引入了 Future 的概念效率要高数倍.而 threading 的话还要自己维护相关的队列防止死锁,代码的可读性也会下降,相反
-
Python爬虫基础之requestes模块
一.爬虫的流程 开始学习爬虫,我们必须了解爬虫的流程框架.在我看来爬虫的流程大概就是三步,即不论我们爬取的是什么数据,总是可以把爬虫的流程归纳总结为这三步: 1.指定 url,可以简单的理解为指定要爬取的网址 2.发送请求.requests 模块的请求一般为 get 和 post 3.将爬取的数据存储 二.requests模块的导入 因为 requests 模块属于外部库,所以需要我们自己导入库 导入的步骤: 1.右键Windows图标 2.点击"运行" 3.输入"cmd&q
-
python xlwt模块的使用解析
一.基础类介绍 1.工作簿类Workbook简介: import xlwt class Workbook(object0): ''' 工作簿类,使用xlwt创建excel文件时,首先要实例化此类的对象 ''' def __init__(self, encoding='ascii', style_compression=0): pass def add_sheet(self,sheetname, cell_overwrite_ok=False): ''' 在工作簿中创建工作表 :param she
-
python文件目录操作之os模块
一.os函数目录 1 os.access(path, mode) 检验权限模式 2 os.chdir(path) 改变当前工作目录 3 os.chflags(path, flags) 设置路径的标记为数字标记. 4 os.chmod(path, mode) 更改权限 5 os.chown(path, uid, gid) 更改文件所有者 6 os.chroot(path) 改变当前进程的根目录 7 os.close(fd) 关闭文件描述符 fd 8 os.closerange(fd_low, fd
-
Python基础之hashlib模块详解
一.hashlib简介 1.什么叫hash: hash是一种算法(不同的hash算法只是复杂度不一样)(3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法),该算法接受传入的内容,经过运算得到一串hash值 2.hash值的特点是(hash值/产品有三大特性:): 只要传入的内容一样,得到的hash值必然一样=====>要用明文传输密码文件完整性校验 不能由hash值返解成内容=======>把密码做成has
-
python常见模块与用法
一.常见内置模块 1.1什么叫做模块? import XXXX xxxxx就是模块 .py 1.2模块的分类 1.random 2.math 3.内置模块 1.3第三方的模块(需要安装) 在线安装 cmd 窗口下通过 pip install 模块名 python -m pip install 模块的名 离线安装 下载好所需要的安装包 zip ---- 解压安装包 ------setup.py--------cmd : python install setup.py 二.模块导入的问题 impor
-
在python中实现导入一个需要传参的模块
最近跑实验,遇到了一个问题: 由于实验数据集比较多,每次跑完一个数据集就需要手动更改文件路径,再将文件传到服务器,再运行实验,这样的话效率很低,必须要专门看着这个实验,啥时候跑完就手动修改运行下一个实验.我个人无法忍受这样低效率,就想能不能有什么解决的办法. 我们期望的解决办法是通过命令行传参来解决这个问题,因为接下来是需要编写shell脚本来批量运行实验,如果用输入语句的方式显得太笨拙. 在编写实验代码的时候,我将所有的参数集中到一个py文件中,这样便于后期的维护,现在的问题就是需要通过命令行