pytorch 中transforms的使用详解
目录
- transforms
- ToTensor
- transforms使用
- 为什么需要tensor数据类型呢?
- 常见的transforms
- 内置方法__call__()
- Normalize
- Resize
- Compose
transforms
按住Ctrl查看transforms的源码可以知道,transforms就是一个python文件,里面定义了很多类,每一个类都是一个工具
在结构那里,可以看到有很多的类


ToTensor
Convert a
PIL Imageornumpy.ndarrayto tensor. This transform does not support torchscript
通过ToTensor来学习transforms如何使用以及为什么使用tensor数据类型
transforms使用
transforms里面每一个类都可以看成是一个模具,我们可以用里面的模具做出一个具体的工具,如何用这个具体的工具来实现具体的功能
比如ToTensor的使用:
from torchvision import transforms from PIL import Image img_path = "data/train/ants_image/0013035.jpg" img = Image.open(img_path) tensor_trans = transforms.ToTensor()#模具(也就是这个类的对象) tensor_img = tensor_trans(img)#实现ToTensor的功能,将一个input(PIL Image)转化成tensor print(tensor_img)
为什么需要tensor数据类型呢?
在使用tensorboard里面常用的add_image时,里面的第二个参数是图片的数据类型,这个数据类型,可以是torch.Tensor, numpy.array, or string/blobname,上一篇博客用的是numpy.array,这里,其实可以直接得到tensor类型后直接用
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
img_path = "data/train/ants_image/0013035.jpg"
img = Image.open(img_path)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
writer = SummaryWriter("logs")
writer.add_image("Tensor_image", tensor_img)
writer.close()

常见的transforms

内置方法__call__()
可以发现基本上transforms里面的每一个类都有一个内置方法__call__(),这个方法和普通的方法的区别其实就是,普通方法一般是类的对象通过.的方式调用,但是call函数不需要,可以直接用对象加括号的形式调用
一个Person类,内置方法__call__和hello都有一个参数name,然后两个方法都输出name,一个通过person(“”)形式调用,一个通过person.hello(“”)调用

Normalize
Normalize a tensor image with mean and standard deviation.
这个方法进行归一化的时候,传入的参数是有两个列表一个是均值,一个是标准差,每个列表的n表示维度,是根据输入的channel数量决定的,比如我们的图片是rgb那n=3,它能将每个信道的输入进行归一化

根据公式可以知道计算的结果其实就是

代码示例:
from PIL import Image
from torchvision import transforms
img_path = "data/train/ants_image/0013035.jpg"
img = Image.open(img_path)
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer = SummaryWriter("logs")
writer.add_image("Normalize", img_norm)
writer.close()
输出:
tensor(0.3137)
tensor(-0.3725)

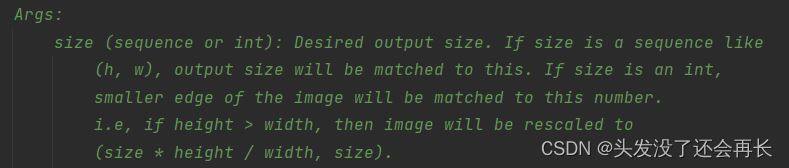
Resize
Resize the input image to the given size
参数:
可以给一个(H,W)这样的参数,改变图片的大小,也可以指定一个int,改变长和宽的比例
代码示例
print(img.size) trans_resize = transforms.Resize((512, 512)) img_resize = trans_resize(img)# 参数和返回值都是 img PIL print(img_resize)
输出结果:

变成了正方形

Compose
Composes several transforms together. This transform does not support torchscript.

可以将第一种类型转化为第二种,参数一的类型做输入,参数二的类型做输出,输入一定要对应,不然就会报错
代码示例
trans_totensor = transforms.ToTensor()
trans_resize_2 = transforms.Resize(512)
# PIL -> tensor
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2, 1)

到此这篇关于pytroch中transforms的使用详解的文章就介绍到这了,更多相关pytroch transforms的使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Pytorch使用transforms
首先,这次讲解的tansforms功能,通俗地讲,类似于在计算机视觉流程里的图像预处理部分的数据增强. transforms的原理: 说明:图片(输入)通过工具得到结果(输出),这个工具,就是transforms模板工具,(tool=transforms.ToTensor()具体工具),使用工具result=tool(图片) tansforms的调用与使用,由下图可得: 先创建一个transforms.Tensor(),使用from torchvision import transforms调包
-
Pytorch中的Tensorboard与Transforms搭配使用
这章是结合之前学习的Tensforboard与Transforms的一个练习. 直接上代码: from PIL import Image from torch.utils.tensorboard import SummaryWriter from torchvision import transforms import os root_path = "D:\\data\\basic\\Image" lable_path = "aligned" img_dir = o
-
Pytoch之torchvision.transforms图像变换实例
transforms.CenterCrop(size) 将给定的PIL.Image进行中心切割,得到给定的size,size可以是tuple,(target_height, target_width).size也可以是一个Integer,在这种情况下,切出来的图片的形状是正方形. size可以为int,也可以为float #定义中心切割 centerCrop = transforms.CenterCrop((img.size[0]/2,img.size[1]/2)) imgccrop = cen
-
pytorch中的transforms模块实例详解
pytorch中的transforms模块中包含了很多种对图像数据进行变换的函数,这些都是在我们进行图像数据读入步骤中必不可少的,下面我们讲解几种最常用的函数,详细的内容还请参考pytorch官方文档(放在文末). data_transforms = transforms.Compose([ transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms
-
初识Pytorch使用transforms的代码
首先,这次讲解的tansforms功能,通俗地讲,类似于在计算机视觉流程里的图像预处理部分的数据增强. transforms的原理: 说明:图片(输入)通过工具得到结果(输出),这个工具,就是transforms模板工具,(tool=transforms.ToTensor()具体工具),使用工具result=tool(图片) tansforms的调用与使用,由下图可得: 先创建一个transforms.Tensor(),使用from torchvision import transforms调包
-
pytorch中的transforms.ToTensor和transforms.Normalize的实现
目录 transforms.ToTensor transforms.Normalize transforms.ToTensor 最近看pytorch时,遇到了对图像数据的归一化,如下图所示: 该怎么理解这串代码呢?我们一句一句的来看,先看transforms.ToTensor(),我们可以先转到官方给的定义,如下图所示: 大概的意思就是说,transforms.ToTensor()可以将PIL和numpy格式的数据从[0,255]范围转换到[0,1] ,具体做法其实就是将原始数据除以255.另外
-
pytorch 中transforms的使用详解
目录 transforms ToTensor transforms使用 为什么需要tensor数据类型呢? 常见的transforms 内置方法__call__() Normalize Resize Compose transforms 按住Ctrl查看transforms的源码可以知道,transforms就是一个python文件,里面定义了很多类,每一个类都是一个工具在结构那里,可以看到有很多的类 ToTensor Convert a PIL Image or numpy.ndarray t
-
pytorch中的自定义数据处理详解
pytorch在数据中采用Dataset的数据保存方式,需要继承data.Dataset类,如果需要自己处理数据的话,需要实现两个基本方法. :.getitem:返回一条数据或者一个样本,obj[index] = obj.getitem(index). :.len:返回样本的数量 . len(obj) = obj.len(). Dataset 在data里,调用的时候使用 from torch.utils import data import os from PIL import Image 数
-
基于python及pytorch中乘法的使用详解
numpy中的乘法 A = np.array([[1, 2, 3], [2, 3, 4]]) B = np.array([[1, 0, 1], [2, 1, -1]]) C = np.array([[1, 0], [0, 1], [-1, 0]]) A * B : # 对应位置相乘 np.array([[ 1, 0, 3], [ 4, 3, -4]]) A.dot(B) : # 矩阵乘法 ValueError: shapes (2,3) and (2,3) not aligned: 3 (dim
-
PyTorch中permute的用法详解
permute(dims) 将tensor的维度换位. 参数:参数是一系列的整数,代表原来张量的维度.比如三维就有0,1,2这些dimension. 例: import torch import numpy as np a=np.array([[[1,2,3],[4,5,6]]]) unpermuted=torch.tensor(a) print(unpermuted.size()) # --> torch.Size([1, 2, 3]) permuted=unpermuted.permute(
-
Pytorch 中retain_graph的用法详解
用法分析 在查看SRGAN源码时有如下损失函数,其中设置了retain_graph=True,其作用是什么? ############################ # (1) Update D network: maximize D(x)-1-D(G(z)) ########################### real_img = Variable(target) if torch.cuda.is_available(): real_img = real_img.cuda() z = V
-
PyTorch中的Variable变量详解
一.了解Variable 顾名思义,Variable就是 变量 的意思.实质上也就是可以变化的量,区别于int变量,它是一种可以变化的变量,这正好就符合了反向传播,参数更新的属性. 具体来说,在pytorch中的Variable就是一个存放会变化值的地理位置,里面的值会不停发生片花,就像一个装鸡蛋的篮子,鸡蛋数会不断发生变化.那谁是里面的鸡蛋呢,自然就是pytorch中的tensor了.(也就是说,pytorch都是有tensor计算的,而tensor里面的参数都是Variable的形式).如果
-
Pytorch中.new()的作用详解
一.作用 创建一个新的Tensor,该Tensor的type和device都和原有Tensor一致,且无内容. 二.使用方法 如果随机定义一个大小的Tensor,则新的Tensor有两种创建方法,如下: inputs = torch.randn(m, n) new_inputs = inputs.new() new_inputs = torch.Tensor.new(inputs) 三.具体代码 import torch rectangle_height = 1 rectangle_width
-
pytorch中index_select()的用法详解
pytorch中index_select()的用法 index_select(input, dim, index) 功能:在指定的维度dim上选取数据,不如选取某些行,列 参数介绍 第一个参数input是要索引查找的对象 第二个参数dim是要查找的维度,因为通常情况下我们使用的都是二维张量,所以可以简单的记忆: 0代表行,1代表列 第三个参数index是你要索引的序列,它是一个tensor对象 刚开始学习pytorch,遇到了index_select(),一开始不太明白几个参数的意思,后来查了一
-
pytorch中nn.Flatten()函数详解及示例
torch.nn.Flatten(start_dim=1, end_dim=- 1) 作用:将连续的维度范围展平为张量. 经常在nn.Sequential()中出现,一般写在某个神经网络模型之后,用于对神经网络模型的输出进行处理,得到tensor类型的数据. 有俩个参数,start_dim和end_dim,分别表示开始的维度和终止的维度,默认值分别是1和-1,其中1表示第一维度,-1表示最后的维度.结合起来看意思就是从第一维度到最后一个维度全部给展平为张量.(注意:数据的维度是从0开始的,也就是
-
pytorch中的dataset用法详解
目录 1.torch.utils.data 里面的dataset使用方法 2.torchvision.datasets的使用方法 用法1:使用官方数据集 用法2:ImageFolder通用的自己数据集加载器 1.torch.utils.data 里面的dataset使用方法 当我们继承了一个 Dataset类之后,我们需要重写 len 方法,该方法提供了dataset的大小: getitem 方法, 该方法支持从 0 到 len(self)的索引 from torch.utils.data im