python里反向传播算法详解
反向传播的目的是计算成本函数C对网络中任意w或b的偏导数。一旦我们有了这些偏导数,我们将通过一些常数 α的乘积和该数量相对于成本函数的偏导数来更新网络中的权重和偏差。这是流行的梯度下降算法。而偏导数给出了最大上升的方向。因此,关于反向传播算法,我们继续查看下文。
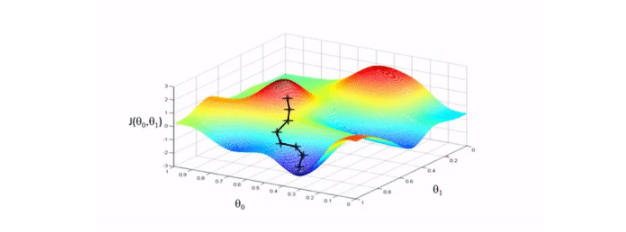
我们向相反的方向迈出了一小步——最大下降的方向,也就是将我们带到成本函数的局部最小值的方向。
图示演示:
反向传播算法中Sigmoid函数代码演示:
# 实现 sigmoid 函数 return 1 / (1 + np.exp(-x)) def sigmoid_derivative(x): # sigmoid 导数的计算 return sigmoid(x)*(1-sigmoid(x))
反向传播算法中ReLU 函数导数函数代码演示:
def relu_derivative(x): # ReLU 函数的导数 d = np.array(x, copy=True) # 用于保存梯度的张量 d[x < 0] = 0 # 元素为负的导数为 0 d[x >= 0] = 1 # 元素为正的导数为 1 return d
实例扩展:
BP反向传播算法Python简单实现
import numpy as np
# "pd" 偏导
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoidDerivationx(y):
return y * (1 - y)
if __name__ == "__main__":
#初始化
bias = [0.35, 0.60]
weight = [0.15, 0.2, 0.25, 0.3, 0.4, 0.45, 0.5, 0.55]
output_layer_weights = [0.4, 0.45, 0.5, 0.55]
i1 = 0.05
i2 = 0.10
target1 = 0.01
target2 = 0.99
alpha = 0.5 #学习速率
numIter = 10000 #迭代次数
for i in range(numIter):
#正向传播
neth1 = i1*weight[1-1] + i2*weight[2-1] + bias[0]
neth2 = i1*weight[3-1] + i2*weight[4-1] + bias[0]
outh1 = sigmoid(neth1)
outh2 = sigmoid(neth2)
neto1 = outh1*weight[5-1] + outh2*weight[6-1] + bias[1]
neto2 = outh2*weight[7-1] + outh2*weight[8-1] + bias[1]
outo1 = sigmoid(neto1)
outo2 = sigmoid(neto2)
print(str(i) + ", target1 : " + str(target1-outo1) + ", target2 : " + str(target2-outo2))
if i == numIter-1:
print("lastst result : " + str(outo1) + " " + str(outo2))
#反向传播
#计算w5-w8(输出层权重)的误差
pdEOuto1 = - (target1 - outo1)
pdOuto1Neto1 = sigmoidDerivationx(outo1)
pdNeto1W5 = outh1
pdEW5 = pdEOuto1 * pdOuto1Neto1 * pdNeto1W5
pdNeto1W6 = outh2
pdEW6 = pdEOuto1 * pdOuto1Neto1 * pdNeto1W6
pdEOuto2 = - (target2 - outo2)
pdOuto2Neto2 = sigmoidDerivationx(outo2)
pdNeto1W7 = outh1
pdEW7 = pdEOuto2 * pdOuto2Neto2 * pdNeto1W7
pdNeto1W8 = outh2
pdEW8 = pdEOuto2 * pdOuto2Neto2 * pdNeto1W8
# 计算w1-w4(输出层权重)的误差
pdEOuto1 = - (target1 - outo1) #之前算过
pdEOuto2 = - (target2 - outo2) #之前算过
pdOuto1Neto1 = sigmoidDerivationx(outo1) #之前算过
pdOuto2Neto2 = sigmoidDerivationx(outo2) #之前算过
pdNeto1Outh1 = weight[5-1]
pdNeto2Outh2 = weight[7-1]
pdEOuth1 = pdEOuto1 * pdOuto1Neto1 * pdNeto1Outh1 + pdEOuto2 * pdOuto2Neto2 * pdNeto1Outh1
pdOuth1Neth1 = sigmoidDerivationx(outh1)
pdNeth1W1 = i1
pdNeth1W2 = i2
pdEW1 = pdEOuth1 * pdOuth1Neth1 * pdNeth1W1
pdEW2 = pdEOuth1 * pdOuth1Neth1 * pdNeth1W2
pdNeto1Outh2 = weight[6-1]
pdNeto2Outh2 = weight[8-1]
pdOuth2Neth2 = sigmoidDerivationx(outh2)
pdNeth2W3 = i1
pdNeth2W4 = i2
pdEOuth2 = pdEOuto1 * pdOuto1Neto1 * pdNeto1Outh2 + pdEOuto2 * pdOuto2Neto2 * pdNeto2Outh2
pdEW3 = pdEOuth2 * pdOuth2Neth2 * pdNeth2W3
pdEW4 = pdEOuth2 * pdOuth2Neth2 * pdNeth2W4
#权重更新
weight[1-1] = weight[1-1] - alpha * pdEW1
weight[2-1] = weight[2-1] - alpha * pdEW2
weight[3-1] = weight[3-1] - alpha * pdEW3
weight[4-1] = weight[4-1] - alpha * pdEW4
weight[5-1] = weight[5-1] - alpha * pdEW5
weight[6-1] = weight[6-1] - alpha * pdEW6
weight[7-1] = weight[7-1] - alpha * pdEW7
weight[8-1] = weight[8-1] - alpha * pdEW8
# print(weight[1-1])
# print(weight[2-1])
# print(weight[3-1])
# print(weight[4-1])
# print(weight[5-1])
# print(weight[6-1])
# print(weight[7-1])
# print(weight[8-1])
到此这篇关于python里反向传播算法详解的文章就介绍到这了,更多相关python里反向传播算法是什么内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python实现的人工神经网络算法示例【基于反向传播算法】
本文实例讲述了Python实现的人工神经网络算法.分享给大家供大家参考,具体如下: 注意:本程序使用Python3编写,额外需要安装numpy工具包用于矩阵运算,未测试python2是否可以运行. 本程序实现了<机器学习>书中所述的反向传播算法训练人工神经网络,理论部分请参考我的读书笔记. 在本程序中,目标函数是由一个输入x和两个输出y组成, x是在范围[-3.14, 3.14]之间随机生成的实数,而两个y值分别对应 y1 = sin(x),y2 = 1. 随机生成一万份训练样例,经过网络的学
-
python里反向传播算法详解
反向传播的目的是计算成本函数C对网络中任意w或b的偏导数.一旦我们有了这些偏导数,我们将通过一些常数 α的乘积和该数量相对于成本函数的偏导数来更新网络中的权重和偏差.这是流行的梯度下降算法.而偏导数给出了最大上升的方向.因此,关于反向传播算法,我们继续查看下文. 我们向相反的方向迈出了一小步--最大下降的方向,也就是将我们带到成本函数的局部最小值的方向. 图示演示: 反向传播算法中Sigmoid函数代码演示: # 实现 sigmoid 函数 return 1 / (1 + np.exp(-x))
-

Python实现聚类K-means算法详解
目录 手动实现 sklearn库中的KMeans K-means(K均值)算法是最简单的一种聚类算法,它期望最小化平方误差 注:为避免运行时间过长,通常设置一个最大运行轮数或最小调整幅度阈值,若到达最大轮数或调整幅度小于阈值,则停止运行. 下面我们用python来实现一下K-means算法:我们先尝试手动实现这个算法,再用sklearn库中的KMeans类来实现.数据我们采用<机器学习>的西瓜数据(P202表9.1): # 下面的内容保存在 melons.txt 中 # 第一列为西瓜的密度:第
-
python查找与排序算法详解(示图+代码)
目录 查找 二分查找 线性查找 排序 插入排序 快速排序 选择排序 冒泡排序 归并排序 堆排序 计数排序 希尔排序 拓扑排序 总结 查找 二分查找 二分搜索是一种在有序数组中查找某一特定元素的搜索算法.搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束:如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较.如果在某一步骤数组为空,则代表找不到.这种搜索算法每一次比较都使搜索范围缩小一半. # 返回 x 在 ar
-
python实现感知器算法详解
在1943年,沃伦麦卡洛可与沃尔特皮茨提出了第一个脑神经元的抽象模型,简称麦卡洛可-皮茨神经元(McCullock-Pitts neuron)简称MCP,大脑神经元的结构如下图.麦卡洛可和皮茨将神经细胞描述为一个具备二进制输出的逻辑门.树突接收多个输入信号,当输入信号累加超过一定的值(阈值),就会产生一个输出信号.弗兰克罗森布拉特基于MCP神经元提出了第一个感知器学习算法,同时它还提出了一个自学习算法,此算法可以通过对输入信号和输出信号的学习,自动的获取到权重系数,通过输入信号与权重系数的乘积来
-
Python实现的快速排序算法详解
本文实例讲述了Python实现的快速排序算法.分享给大家供大家参考,具体如下: 快速排序基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列. 如序列[6,8,1,4,3,9],选择6作为基准数.从右向左扫描,寻找比基准数小的数字为3,交换6和3的位置,[3,8,1,4,6,9],接着从左向右扫描,寻找比基准数大的数字为8,交换6和8的位置
-
python列表与列表算法详解
目录 1. 序列类型定义 2. 列表的基础知识 2.1 列表定义 2.2 列表基本操作 总结 1. 序列类型定义 序列是具有先后关系的一组元素 序列是一维元素向量,元素类型可以不同 类似数学运算序列:S0,S1,-,S(n-1) 元素间由序号引导,通过下表访问序列的特定元素 序列是一个基类类型 序列处理函数及方法 序列类型通用函数和方法 2. 列表的基础知识 2.1 列表定义 列表(list):是可变的序列型数据,也是一种可以存储各种数据类型的集合,用中括号([ ])表示列表的开始和结束,列表中
-
python列表与列表算法详解(2)
目录 2. 案例[三酷猫冒泡法排序] 3. 案例[三酷猫二分法查找] 总结 1. 案例[三酷猫列表记账] 操作需求: (1)用列表对象记录三酷猫每天钓鱼的种类和数量 (2)统计三酷猫所钓水产品的总数量和预计收获金额 (3)打印财务报表一张. #三酷猫列表记账 nums = 0 #统计数量变量 amount = 0 #统计金额数量 i = 0 #循环控制变量 fish_record = ['1月1日','鲫鱼',18,10.5,'1月1日','鲤鱼',8,6.2,'1月1日','鲢鱼',7,4.7
-
python实现决策树C4.5算法详解(在ID3基础上改进)
一.概论 C4.5主要是在ID3的基础上改进,ID3选择(属性)树节点是选择信息增益值最大的属性作为节点.而C4.5引入了新概念"信息增益率",C4.5是选择信息增益率最大的属性作为树节点. 二.信息增益 以上公式是求信息增益率(ID3的知识点) 三.信息增益率 信息增益率是在求出信息增益值在除以. 例如下面公式为求属性为"outlook"的值: 四.C4.5的完整代码 from numpy import * from scipy import * from mat
-
python算法演练_One Rule 算法(详解)
这样某一个特征只有0和1两种取值,数据集有三个类别.当取0的时候,假如类别A有20个这样的个体,类别B有60个这样的个体,类别C有20个这样的个体.所以,这个特征为0时,最有可能的是类别B,但是,还是有40个个体不在B类别中,所以,将这个特征为0分到类别B中的错误率是40%.然后,将所有的特征统计完,计算所有的特征错误率,再选择错误率最低的特征作为唯一的分类准则--这就是OneR. 现在用代码来实现算法. # OneR算法实现 import numpy as np from sklearn.da
-
python中实现k-means聚类算法详解
算法优缺点: 优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢 使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去. 1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好.另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚