利用Python对中国500强排行榜数据进行可视化分析
目录
- 一、前言
- 二、数据采集
- 1.开始爬取
- 获取企业列表
- 获取企业对应url
- 获取每一个企业相关数据
- 2.保存到Excel
- 三、可视化分析
- 1.省份分布
- 导入相关可视化库
- 统计数据
- 地图可视化
- 2.营业收入年增率
- 3.营业收入年减率
- 4.利润年增率
- 5.利润年减率
- 6.排名上升最快20家企业
- 7.排名下降最快20家企业
- 8.资产区间分布
- 9.市值区间分布
- 10.营业收入区间分布
- 11.利润区间分布
- 12.中国500强企业-排名前10营业收入、利润、资产、市值、股东权益
- 四、总结
一、前言
今天来跟大家分析一下2020年中国500强企业排行榜数据,从不同角度去对数据进行统计分析,可视化展示。
主要分析内容:
中国500强企业-省份分布。
中国500强企业-营业收入年增率。
中国500强企业-营业收入年减率。
中国500强企业-利润年增率。
中国500强企业-利润年减率。
中国500强企业-排名上升最快。
中国500强企业-排名下降最快。
中国500强企业-资产区间分布。
中国500强企业-市值区间分布。
中国500强企业-营业收入区间分布。
中国500强企业-利润区间分布。
中国500强企业-排名前10营业收入、利润、资产、市值、股东权益等情况。
下面开始从数据采集到数据统计分析,最后进行可视化!!!
二、数据采集

1.开始爬取
获取企业列表
url="http://www.fortunechina.com/fortune500/c/2020-07/27/content_369925.htm" res = requests.get(url,headers=headers) res.encoding = 'utf-8' text = res.text
获取企业对应url
for i in range(0,len(table_tr)):
try:
#name = i.xpath('.//td/a/text()')[0]
href = table_tr[i].xpath('.//td/a/@href')[0].replace("../../../../","http://www.fortunechina.com/")
column_list = get_detail(href)
for k in range(0,len(column_list)):
outws.cell(row=count, column=k+1, value=column_list[k])
print(count)
count = count+1
except:
pass
获取每一个企业相关数据
name = selector.xpath('//*[@class="comp-name"]/text()')[0]
r1 = selector.xpath('//*[@class="con"]/em[@class="r1"]/text()')[0]
r2 = selector.xpath('//*[@class="con"]/span/em/font[@class="ft-red"]/text()')[0]
address = selector.xpath('//*[@class="info"]/p')[0].xpath('.//text()')[0].replace(" ", "")
table_tbody_tr = selector.xpath('//*[@class="table"]/table/tr')
2.保存到Excel
outwb = openpyxl.Workbook()
outws = outwb.create_sheet(index=0)
outws.cell(row=1, column=1, value="企业名称")
outws.cell(row=1, column=2, value="2020年排名")
outws.cell(row=1, column=3, value="2019年排名")
outws.cell(row=1, column=4, value="总部地址")
outws.cell(row=1, column=5, value="营业收入")
outws.cell(row=1, column=6, value="营业收入年增减")
outws.cell(row=1, column=7, value="利润")
outws.cell(row=1, column=8, value="利润年增减")
outws.cell(row=1, column=9, value="资产")
outws.cell(row=1, column=10, value="市值")
outws.cell(row=1, column=11, value="股东权益")
outwb.save("中国500强排行榜数据.xlsx") # 保存

数据就已经保存到Excel中,下面开始进行统计分析,可视化!
三、可视化分析
1.省份分布
导入相关可视化库
from pyecharts import options as opts from pyecharts.charts import Line from pyecharts.charts import Map import pandas as pd from pyecharts import options as opts from pyecharts.globals import ThemeType from pyecharts.charts import Bar
统计数据

从excel中中取出:总部地址,然后取出前两位(省份),统计每一个省份的500强分布情况
address = pd_data['总部地址']
address = address.tolist()
address_03 = []
for i in address:
###取省份(前两位)
address_03.append(i[0:2])
data =[]
address_03_set = set(address_03) #address_03_set是另外一个列表,里面的内容是address_03里面的无重复 项
for item in address_03_set:
data.append((item,address_03.count(item)))
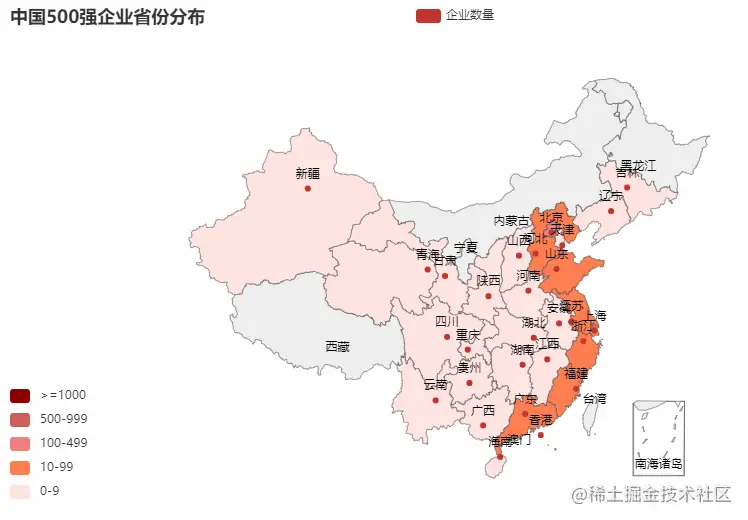
地图可视化
def map_china() -> Map:
c = (
Map()
.add(series_name="企业数量", data_pair=data, maptype="china",zoom = 1,center=[105,38])
.set_global_opts(
title_opts=opts.TitleOpts(title="中国500强企业省份分布"),
visualmap_opts=opts.VisualMapOpts(max_=9999,is_piecewise=True,
pieces=[{"max": 9, "min": 0, "label": "0-9","color":"#FFE4E1"},
{"max": 99, "min": 10, "label": "10-99","color":"#FF7F50"},
{"max": 499, "min": 100, "label": "100-499","color":"#F08080"},
{"max": 999, "min": 500, "label": "500-999","color":"#CD5C5C"},
{"max": 9999, "min": 1000, "label": ">=1000", "color":"#8B0000"}]
)
)
)
return c
2.营业收入年增率
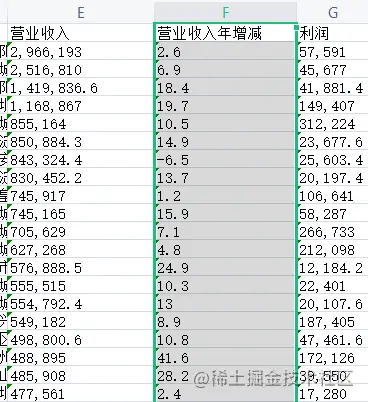
从excel中中取出:营业收入年增减,统计增加率最大的前50名和减少率(负数)最大的前50名
income_rate = pd_data['营业收入年增减']
compare_name = pd_data['企业名称']
income_rate = income_rate.tolist()
compare_name = compare_name.tolist()
m = income_rate
# 求一个list中最大的50个数,并排序
max_number = heapq.nlargest(50, m)
# 最大的2个数对应的,如果用nsmallest则是求最小的数及其索引
max_index = map(m.index, heapq.nlargest(50, m))
# max_index 直接输出来不是数,使用list()或者set()均可输出
#print(set(max_index)) ###{235, 140, 273, 148, 86}
max_index = list(set(max_index))
#ss = [m.index(j) for j in max_number]
name =[compare_name[k] for k in set(max_index)]
outwb = openpyxl.Workbook()
outws = outwb.create_sheet(index=0)

3.营业收入年减率
income_rate = income_rate.tolist() compare_name = compare_name.tolist() m = income_rate # 求一个list中最小的50个数,并排序 min_number = heapq.nsmallest(60, m) min_index = [m.index(j) for j in min_number] name =[compare_name[k] for k in set(min_index)]

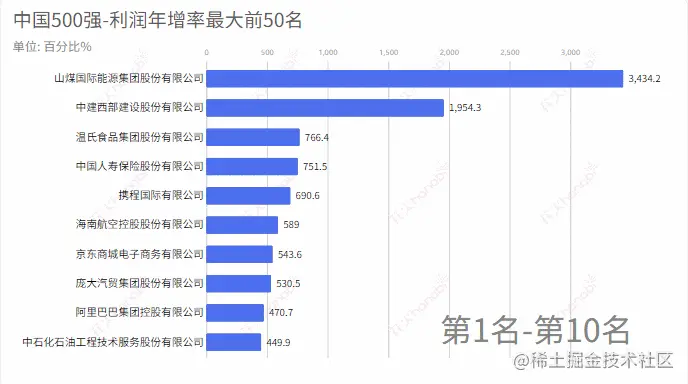
4.利润年增率

从excel中中取出:利润年增减,统计增加率最大的前50名和减少率(负数)最大的前50名
5.利润年减率

6.排名上升最快20家企业

从excel中中取出:2020年排名和2019年排名,进行对比,统计排名上升最大的前20家企业,和排名下降最大的前20家企业。
###折线图
def LinePic(x_data,y_data,name):
(
Line()
# 进行全局设置
.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=True), # 显示提示信息,默认为显示,可以不写
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
# 添加x轴的点
.add_xaxis(xaxis_data=x_data)
# 添加y轴的点
.add_yaxis(
series_name=name,
y_axis=y_data,
symbol="emptyCircle",
is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=True),
)
# 保存为一个html文件
.render(name+".html")
)

7.排名下降最快20家企业

8.资产区间分布

从excel中中取出:资产,为9000 间隔进行区间划分,并统计每一个区间的个数。
for k, g in groupby(sorted(assets_list), key=lambda x: x // 90000):
name.append(str(k * 90000) + "~" + str((k + 1) * 90000 - 1))
dict_value.append(int(len(list(g))))

9.市值区间分布

从excel中中取出:市值,为7000 间隔进行区间划分,并统计每一个区间的个数。
for k, g in groupby(sorted(assets_list), key=lambda x: x // 7000):
name.append(str(k * 7000) + "~" + str((k + 1) * 7000 - 1))
dict_value.append(int(len(list(g))))

10.营业收入区间分布

从excel中中取出:营业收入,为50000 间隔进行区间划分,并统计每一个区间的个数。
for k, g in groupby(sorted(assets_list), key=lambda x: x // 50000):
name.append(str(k * 50000) + "~" + str((k + 1) * 50000 - 1))
dict_value.append(int(len(list(g))))

11.利润区间分布

从excel中中取出:利润为5000 间隔进行区间划分,并统计每一个区间的个数。
for k, g in groupby(sorted(assets_list), key=lambda x: x//5000):
name.append(str(k*5000)+"~"+str((k+1)*5000-1))
dict_value.append(int(len(list(g))))

12.中国500强企业-排名前10营业收入、利润、资产、市值、股东权益
从excel中中取出排名前10: **营业收入、**利润、资产、市值、股东权益、
name = pd_data['企业名称'][0:11].tolist()
data_1 = pd_data['营业收入'][0:11].tolist()
data_2 = pd_data['利润'][0:11].tolist()
data_3 = pd_data['资产'][0:11].tolist()
data_4 = pd_data['市值'][0:11].tolist()
data_5 = pd_data['股东权益'][0:11].tolist()
# 链式调用
c = (
Bar(
init_opts=opts.InitOpts( # 初始配置项
theme=ThemeType.MACARONS,
animation_opts=opts.AnimationOpts(
animation_delay=1000, animation_easing="cubicOut" # 初始动画延迟和缓动效果
))
)
.add_xaxis(xaxis_data=name) # x轴
.add_yaxis(series_name="营业收入", yaxis_data=cleardata(data_1)) # y轴
.add_yaxis(series_name="利润", yaxis_data=cleardata(data_2)) # y轴
.add_yaxis(series_name="资产", yaxis_data=cleardata(data_3)) # y轴
.add_yaxis(series_name="市值", yaxis_data=cleardata(data_4)) # y轴
.add_yaxis(series_name="股东权益", yaxis_data=cleardata(data_5)) # y轴
.set_global_opts(
title_opts=opts.TitleOpts(title='', subtitle='排名前10经济情况', # 标题配置和调整位置
title_textstyle_opts=opts.TextStyleOpts(
font_family='SimHei', font_size=25, font_weight='bold', color='red',
), pos_left="90%", pos_top="10",
),
xaxis_opts=opts.AxisOpts(name='企业名称', axislabel_opts=opts.LabelOpts(rotate=20)),
# 设置x名称和Label rotate解决标签名字过长使用
yaxis_opts=opts.AxisOpts(name='单位:百万美元'),
)
.render("2020年中国500强-排名前10名经济情况.html")
)

四、总结
本文主要对以下12个方面进行统计分析,最后绘制可视化图
中国500强企业-省份分布。
中国500强企业-营业收入年增率。
中国500强企业-营业收入年减率。
中国500强企业-利润年增率。
中国500强企业-利润年减率。
中国500强企业-排名上升最快。
中国500强企业-排名下降最快。
中国500强企业-资产区间分布。
中国500强企业-市值区间分布。
中国500强企业-营业收入区间分布。
中国500强企业-利润区间分布。
中国500强企业-排名前10营业收入、利润、资产、市值、股东权益等情况。
到此这篇关于利用Python对中国500强排行榜数据进行可视化分析的文章就介绍到这了,更多相关Python数据可视化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python采集股票数据并制作可视化柱状图
目录 前言 模块使用 开发环境 代码实现步骤 代码 数据可视化 前言 嗨喽!大家好呀,这里是魔王~ 雪球,聪明的投资者都在这里 - 4300万投资者都在用的投资社区, 沪深港美全球市场实时行情,股票基金债券免费资讯,与投资高手实战交流. 模块使用 requests >>> pip install requests (数据请求 第三方模块) re # 正则表达式 去匹配提取数据 json pandas pyecharts 开发环境 Python 3.8 解释器 Pycharm 2021.2
-
Python 数据可视化超详细讲解折线图的实现
绘制简单的折线图 在使用matplotlib绘制简单的折线图之前首先需要安装matplotlib,直接在pycharm终端pip install matplotlib即可 使用matplotlib绘制简单的折线图,再对其进行定制,实现数据的可视化操作 import matplotlib.pyplot as plt # 导入pyplot模块并设置别名为plt squares = [1, 4, 9, 16, 25] plt.plot(squares) plt.show() # 打开matplotib
-
使用python把Excel中的数据在页面中可视化
目录 一. 需求 二. 安装xlrd模块 三. 用echart在html中表现 总结 一. 需求 最近我们数据可视化的老师让我们把广州历史房价中的房价数据可视化,然后给我们发了广州历史房价.xls,然后看了一下数据确实有点小多,反正复制粘贴是有点费劲的,所以就想借用python帮我把数据修改成我一键复制的模样. 二. 安装xlrd模块 pip install xlrd 通常pip都是带有的,我们在开发工具中import xlrd就可以啦. 下面是实现切割一年每个月份的方法 import xlr
-
Python数据可视化Pyecharts制作Heatmap热力图
目录 HeatMap:热力图 1.基本设置 2.热力图数据项 Demo 举例 1.基础热力图 本文介绍基于 Python3 的 Pyecharts 制作 Heatmap(热力图 时需要使用的设置参数和常用模板案例,可根据实际情况对案例中的内容进行调整即可. 使用 Pyecharts 进行数据可视化时可提供直观.交互丰富.可高度个性化定制的数据可视化图表.案例中的代码内容基于 Pyecharts 1.x 版本 . HeatMap:热力图 1.基本设置 class HeatMap( # 初始化配置项
-
python数据可视化之日期折线图画法
本文实例为大家分享了python日期折线图画法的具体代码,供大家参考,具体内容如下 引入 什么是折线图: 折线图是排列在工作表的列或行中的数据可以绘制到折线图中.折线图可以显示随时间(根据常用比例设置)而变化的连续数据,因此非常适用于显示在相等时间间隔下数据的趋势.在折线图中,类别数据沿水平轴均匀分布,所有值数据沿垂直轴均匀分布. 以上引用自 百度百科 ,简单来说一般折线图 是以时间作为 X 轴 数据 作为 Y轴,这当然不是固定的,是可以自行设置的. 话不多说~ 进入正题 第一种画法: impo
-
python数据可视化之条形图画法
什么是条形图? 条形图(bar chart)是用宽度相同的条形的高度或长短来表示数据多少的图形.条形图可以横置或纵置,纵置时也称为柱形图(column chart).此外,条形图有简单条形图.复式条形图等形式. 简单来说,条形图的宽度一般是相同的,条形的高度或长短表示数据的多少,这也就是条形图和直方图的本质区别. 第一种画法 import numpy as np from pandas import DataFrame # 由于我们的x轴上刻度值是中文 需要使用这个包 进行中文的显示 from
-
利用Python对中国500强排行榜数据进行可视化分析
目录 一.前言 二.数据采集 1.开始爬取 获取企业列表 获取企业对应url 获取每一个企业相关数据 2.保存到Excel 三.可视化分析 1.省份分布 导入相关可视化库 统计数据 地图可视化 2.营业收入年增率 3.营业收入年减率 4.利润年增率 5.利润年减率 6.排名上升最快20家企业 7.排名下降最快20家企业 8.资产区间分布 9.市值区间分布 10.营业收入区间分布 11.利润区间分布 12.中国500强企业-排名前10营业收入.利润.资产.市值.股东权益 四.总结 一.前言 今天来
-
Python爬虫获取国外大桥排行榜数据清单
目录 目标站点分析 编码时间 前言: 本例开始学习 PyQuery 解析框架,该解析对从前端转 Python 的朋友非常友好,因为它模拟的是 JQuery 操作. 正式开始前,先安装 pyquery 到本地开发环境中.命令如下:pip install pyquery ,我使用的版本为 1.4.3. 基本使用如下所示,看懂也就掌握了 5 成了,就这么简单. from pyquery import PyQuery as pq s = '<html><title>橡皮擦的PyQuery小
-
利用Python在一个文件的头部插入数据的实例
在一个文件的末尾追加数据是很常用的.在使用过程中应该都比较熟悉不会出现什么错误.但是往一个文件头部插入数据可能或多或少会碰到一些问题. 看似正确的错误代码 很多代码看似正确,但是其实都是错的.一起来看下这些代码 1.看似正确的错误代码1 with open(path, "r+") as f: f.seek(0) f.write(data) 确实是从头写了,而且有些原有数据确实在,但是数据有问题.... 因为"r+"方式写文件操作没有插入的语义,只有写文件的含义,原来
-
利用python和百度地图API实现数据地图标注的方法
如题,先上效果图: 主要分为两大步骤 使用python语句,通过百度地图API,对已知的地名抓取经纬度 使用百度地图API官网的html例程,修改数据部分,实现呈现效果 一.使用python语句,通过百度地图API,获取经纬度读取文件信息 import pandas as pd data = pd.read_excel('test_baidu.xlsx') data 图中可以看出,原始数据并没有经纬度. 2. 构建抓取经纬度函数 import json from urllib.request i
-
利用python对Excel中的特定数据提取并写入新表的方法
最近刚开始学python,正好实习工作中遇到对excel中的数据进行处理的问题,就想到利用python来解决,也恰好练手. 实际的问题是要从excel表中提取日期.邮件地址和时间,然后统计在一定时间段内某个人在某个项目上用了多少时间,最后做成一张数据透视表(这是问题的大致意思). 首先要做的就是数据提取了,excel中本身有一个text to column的功能,但是对列中规律性不好的数据处理效果很差,不能分割出想要的数据,所以我果断选择用python来完成. 要用的库一个是对excel读写处理
-
利用python绘制中国地图(含省界、河流等)
我们可以使用Basemap这个工具包来实现中国地图的绘制 首先需要加载一些包: import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.basemap import Basemap Basemap包就是气象画图的利器,现在我们就可以愉快的画图了! plt.figure(1) map=Basemap() map.drawcoastlines() plt.title(r'$World\ Map$',fontsize=2
-
利用Python多处理库处理3D数据详解
今天我们将介绍处理大量数据时非常方便的工具.我不会只告诉您可能在手册中找到的一般信息,而是分享一些我发现的小技巧,例如tqdm与 multiprocessingimap一起使用.并行处理档案.绘制和处理 3D 数据以及如何搜索如果您有点云,则用于对象网格中的类似对象. 那么我们为什么要求助于并行计算呢?如今,如果您处理任何类型的数据,您可能会面临与"大数据"相关的问题.每次我们有不适合 RAM 的数据时,我们都需要一块一块地处理它.幸运的是,现代编程语言允许我们生成在多核处理器
-
利用Python实时获取steam特惠游戏数据
目录 前言 代码部分 开发环境 先导入本次所需的模块 请求数据 获取请求的数据 解析数据 保存数据 前言 Steam是由美国电子游戏商Valve于2003年9月12日推出的数字发行平台,被认为是计算机游戏界最大的数码发行平台之一,Steam平台是全球最大的综合性数字发行平台之一.玩家可以在该平台购买.下载.讨论.上传和分享游戏和软件. 而每周的steam会开启了一轮特惠,可以让游戏打折,而玩家就会购买心仪的游戏 传说每次有大折扣,无数的玩家会去购买游戏,可以让G胖亏死 不过,由于种种原因,我总会
-
如何利用python在剪贴板上读取/写入数据
目录 读取剪贴板上的数据 将数据写入剪贴板 补充:python 剪切板写入文件,产生随机数写入剪切板 总结 读取剪贴板上的数据 先给大家介绍pandas.read_clipboard,从剪贴板读取文本并传递到Read_csv. pandas.read_clipboard(sep='\\s+', **kwargs) 其中参数sep是字段定界符,默认为’\s+’,也就是说将tab和多个空格都当成一样的分隔符. 接下来执行操作,打开表格→选中数据Ctrl+C复制→再执行以下代码 import pand
-
Python实现爬取天气数据并可视化分析
目录 核心功能设计 实现步骤 爬取数据 风向风级雷达图 温湿度相关性分析 24小时内每小时时段降水 24小时累计降雨量 今天我们分享一个小案例,获取天气数据,进行可视化分析,带你直观了解天气情况! 核心功能设计 总体来说,我们需要先对中国天气网中的天气数据进行爬取,保存为csv文件,并将这些数据进行可视化分析展示. 拆解需求,大致可以整理出我们需要分为以下几步完成: 1.通过爬虫获取中国天气网7.20-7.21的降雨数据,包括城市,风力方向,风级,降水量,相对湿度,空气质量. 2.对获取的天气数