Python数据分析之NumPy常用函数使用详解
目录
- 文件读入
- 1、保存或创建新文件
- 2、读取csv文件的函数loadtxt
- 3、常见的函数
- 4、股票的收益率等
- 5、对数收益与波动率
- 6、日期分析
- 总结
本篇我们将以分析历史股价为例,介绍怎样从文件中载入数据,以及怎样使用NumPy的基本数学和统计分析函数、学习读写文件的方法,并尝试函数式编程和NumPy线性代数运算,来学习NumPy的常用函数。
文件读入
读写文件是数据分析的一项基本技能
CSV(Comma-Separated Value,逗号分隔值)格式是一种常见的文件格式。通常,数据库的转存文件就是CSV格式的,文件中的各个字段对应于数据库表中的列。
NumPy中的 loadtxt 函数可以方便地读取CSV文件,自动切分字段,并将数据载入NumPy数组。
1、保存或创建新文件
import numpy as np
i = np.eye(3) #eye(n)函数创建n维单位矩阵
print(i)
np.savetxt('test.txt', i) #savetxt()创建并保存test.txt文件
savetxt()函数,如果有已经文件则更新,如目录中没有,则创建并保存test.txt文件
运行结果如下:
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
2、读取csv文件的函数loadtxt
1)先在保存程序的目录下创建一个名称为data.csv的文件,并设置数据如下图:
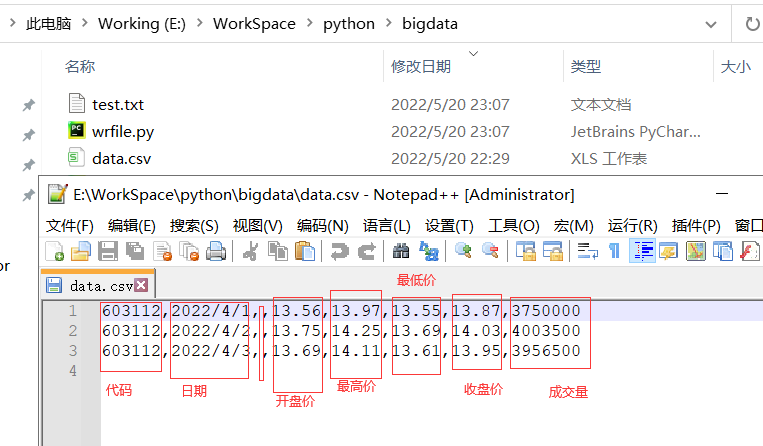
2)读取文件,如下:
c,v=np.loadtxt('data.csv', delimiter=',', usecols=(6,7), unpack=True)
usecols 的参数是一个元组,以获取第7字段至第8字段的数据,也就是上述文件中 股票的收盘价和成交量数据。 unpack 参数设置为 True ,是分拆存储不同列的数据,即分别将收盘价和成交量的数组赋值给变量c和v。
3、常见的函数
成交量加权平均、时间加权、算术平均值、中位数、方差等
import numpy as np
i = np.eye(3) #eye(n)函数创建n维单位矩阵
print(i)
np.savetxt('test.txt', i) #savetxt创建并保存test.txt文件
#读取csv文件
c,v=np.loadtxt('data.csv', delimiter=',', usecols=(6,7), unpack=True)
"""usecols 的参数为一个元组,以获取第7字段至第8字段的数据,也就是股票的收盘价和成交量数据。 unpack 参数设置为 True ,是分拆存储不同列的数据,即分别将收
盘价和成交量的数组赋值给变量c和v"""
vwap = np.average(c, weights=v) #调用了average函数,将v作为权重参数使用,
print(vwap)
print('\n')
print( np.mean(c)) #算术平均值
print('\n')
t = np.arange(len(c))
print( t )
print('\n')
twap =np.average(c, weights=t) #按时间权重
print( twap )
print('\n')
h,l=np.loadtxt('data.csv',delimiter=',', usecols=(4,5), unpack=True)
# 获取第4字段至第5字段的数据,即股票的最高价和最低价
print ( np.max(h)) #获取最大值max()
print ( np.min(l)) #获取最小值min()
print('\n')
print( np.ptp(h) ) # 用ptp()函数计算了极差,即最大值和最小值之间的差值
print( np.ptp(l) )
print('\n')
print( np.median(c)) # 中位数median()函数,即多个数据中,处于中间的数
print( np.msort(c))#msort(( ))函数对价格数组进行排序,可以验证上述中位数
#方差的计算
variance = np.var(c) #方差函数var()
print(variance)
用代码、excel进行相关计算,运行结果如下:
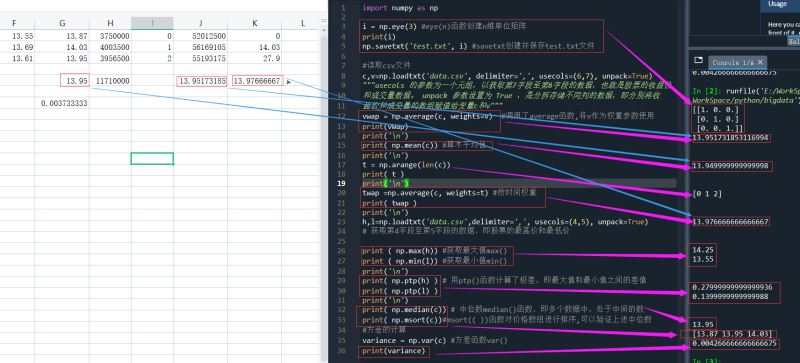
为后面计算,将data.csv中的数据多增加几行,修改如下并保存(为后面日期读写与修改,日期形式修改成如下):
603112,2022-4-1,,13.56,13.97,13.55,13.87,3750000603112,2022-4-2,,13.75,14.25,13.69,14.03,4003500603112,2022-4-3,,13.69,14.11,13.61,13.95,3956500603112,2022-4-4,,14.3,14.3,13.73,13.89,4250000603112,2022-4-5,,14.1,14.5,13.93,14,4013500603112,2022-4-6,,14.5,15.4,14.35,15.4,9056500603112,2022-4-7,,16,16.94,15.85,16.94,3750000
4、股票的收益率等
股市中最常见的就是涨幅,也就是今日收盘价相对昨日涨跌的比例,即 (今日收盘价-昨天收盘价)/昨日收盘价*100,numpy中的 diff() 函数可以返回一个由相邻数组元素的差值构成的数组,由于相邻数据相减,因此diff()数组数据较原数组少一个。
如上述修改后,有7天的收盘价,diff()计算出的结果就只有6位,
import numpy as np
#读取csv文件
c,v=np.loadtxt('data.csv', delimiter=',', usecols=(6,7), unpack=True)
#股票的简单收益率
# diff 函数可以返回一个由相邻数组元素的差值构成的数组
results = np.diff(c)
print(results)
print('\n')
results1 = np.diff(c)/c[:-1]*100 #相对前一天的涨幅
print(results1)
print('\n')
Standard_deviation =np.std(results) # 计算出标准差
print(Standard_deviation)
运行结果,代码、excel进行相比较:
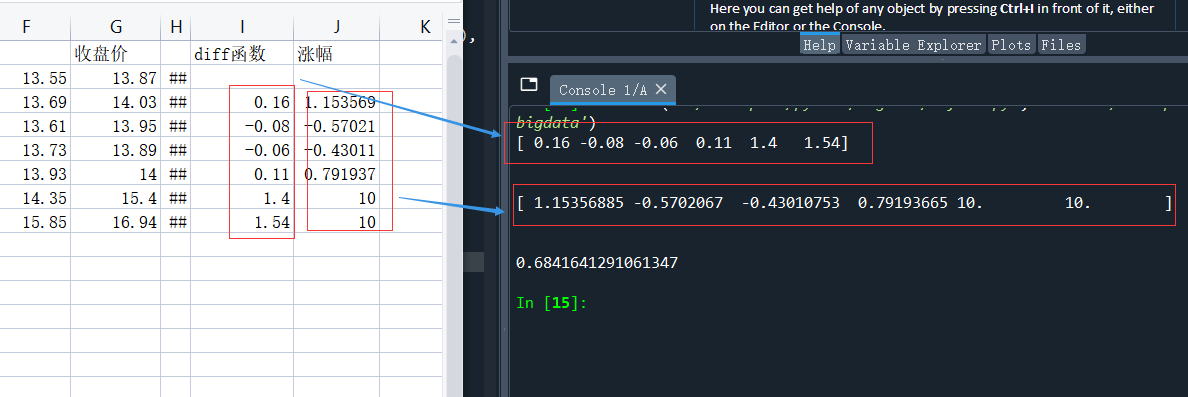
5、对数收益与波动率
1)对数收益:log 函数得到每一个收盘价的对数,再对结果使用 diff 函数即可,
logreturns = np.diff( np.log(c) ) print(logreturns)
运行结果:
[ 0.01146966 -0.00571839 -0.00431035 0.00788817 0.09531018 0.09531018]
2) where的作用
where 函数可以根据指定的条件返回所有满足条件的序列索引值,比如上述logreturns中有两个小于0的数据。
posretindices = np.where(results1 > 0)
print('Indices with positive returns1',posretindices)
运行结果:
Indices with positive returns1 (array([0, 3, 4, 5], dtype=int64),)
3)波动率:波动率=对数收益率的标准差除以其均值,再除以交易周期倒数的平方根。下面代码分别为以年、月进行统计的波动率.
annual_volatility =(np.std(logreturns)/np.mean(logreturns))/np.sqrt(1./252.)#使用浮点数才能得到正确的结果 print ( annual_volatility ) #月波动率 month_volatility =(np.std(logreturns)/np.mean(logreturns))/np.sqrt(1./12.) print ( month_volatility )
6、日期分析
处理日期总是很烦琐。NumPy是面向浮点数运算的,因此需要对日期做一些专门的处理。
通过上述代码,我们知道,修改函数np.loadtxt('data.csv', delimiter=',', usecols=(6,7), unpack=True)中的参数 usecols=(6,7)就可以读取不同的列,日期是在第2列,即下标应该为1(数列下标是从0开始的),可以重新定义新日期数列并获取后存入。
代码如下:
dates, c=np.loadtxt('data.csv', delimiter=',', usecols=(1,6), unpack=True) #读取下标为1、6的数据,分别存入到dates和c数列中。
但实际运行过程中会报错,

代码需要作如下修改:
import numpy as np
from datetime import datetime
def datestr2num(s): #定义一个函数
return datetime.strptime(s.decode('ascii'),"%Y-%m-%d").date().weekday()
#decode('ascii') 将字符串s转化为ascii码
#读取csv文件
dates,close=np.loadtxt('data.csv',delimiter=',', usecols=(1,6),converters={1:datestr2num},unpack=True)
print(dates)
运行结果:[4. 5. 6. 0. 1. 2. 3.],也是从0开始,到6结束。为了更好地说明数据,可以采用真实的数据,即从通信达软件直接下载真实的交易数据,如下图所示:
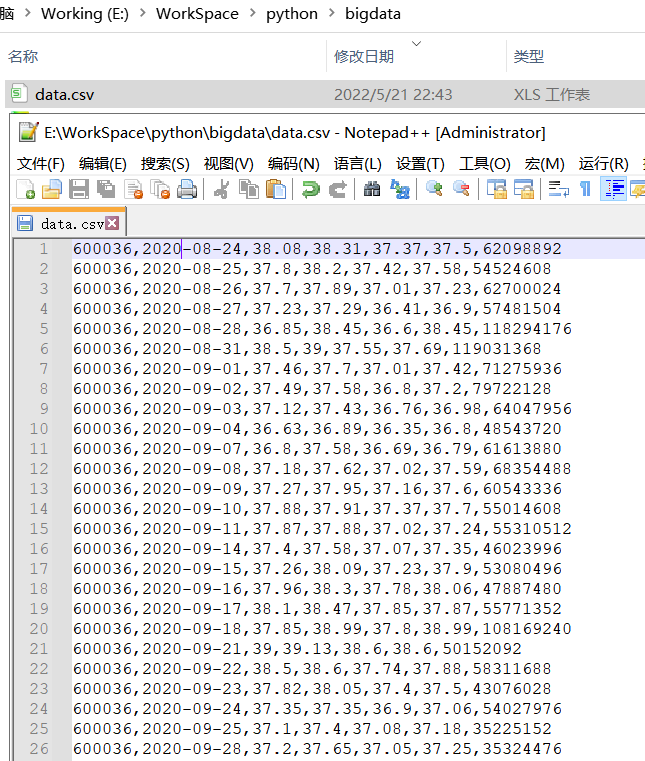
(注意:较原来少了一列空格列)
修改代码如下:
import numpy as np
from datetime import datetime
def datestr2num(s): #定义一个函数
return datetime.strptime(s.decode('ascii'),"%Y-%m-%d").date().weekday()
#decode('ascii') 将字符串s转化为ascii码
#读取csv文件
dates,c=np.loadtxt('data.csv',delimiter=',', usecols=(1,5),
converters={1:datestr2num},unpack=True)
print(dates)
print(len(dates)) #统计导出的天数
运行结果:
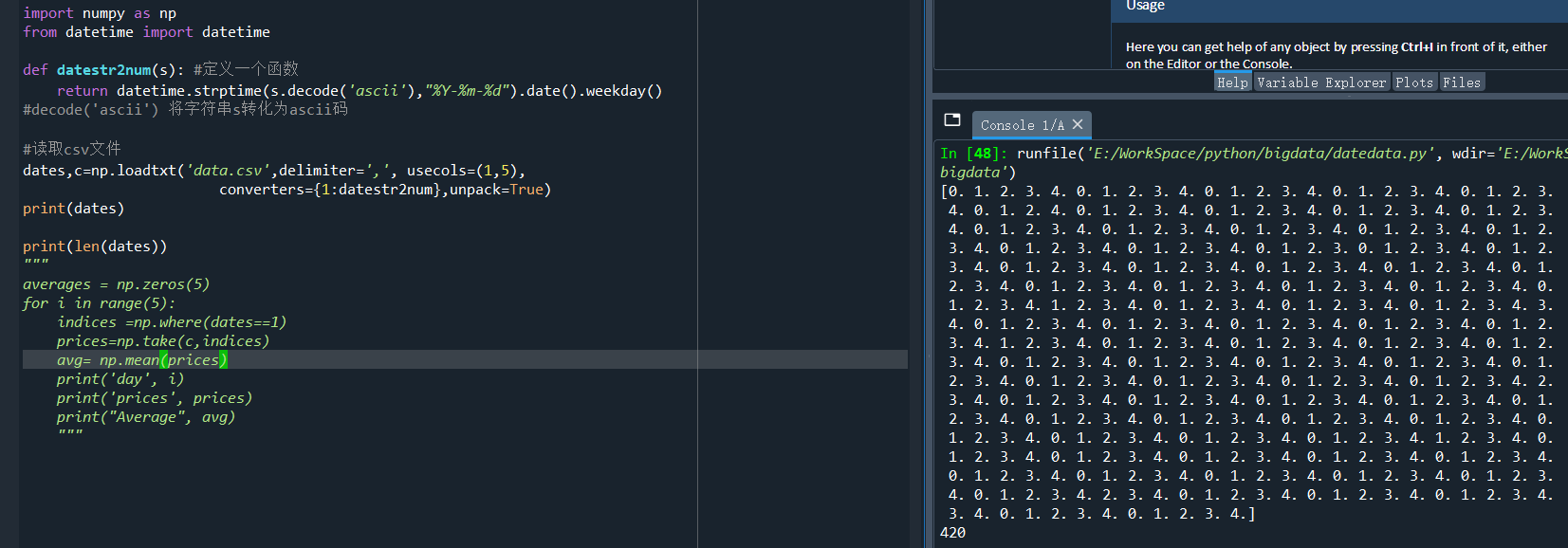
如上图,导出有420天数据。
按周一到周五,统计相关数据:
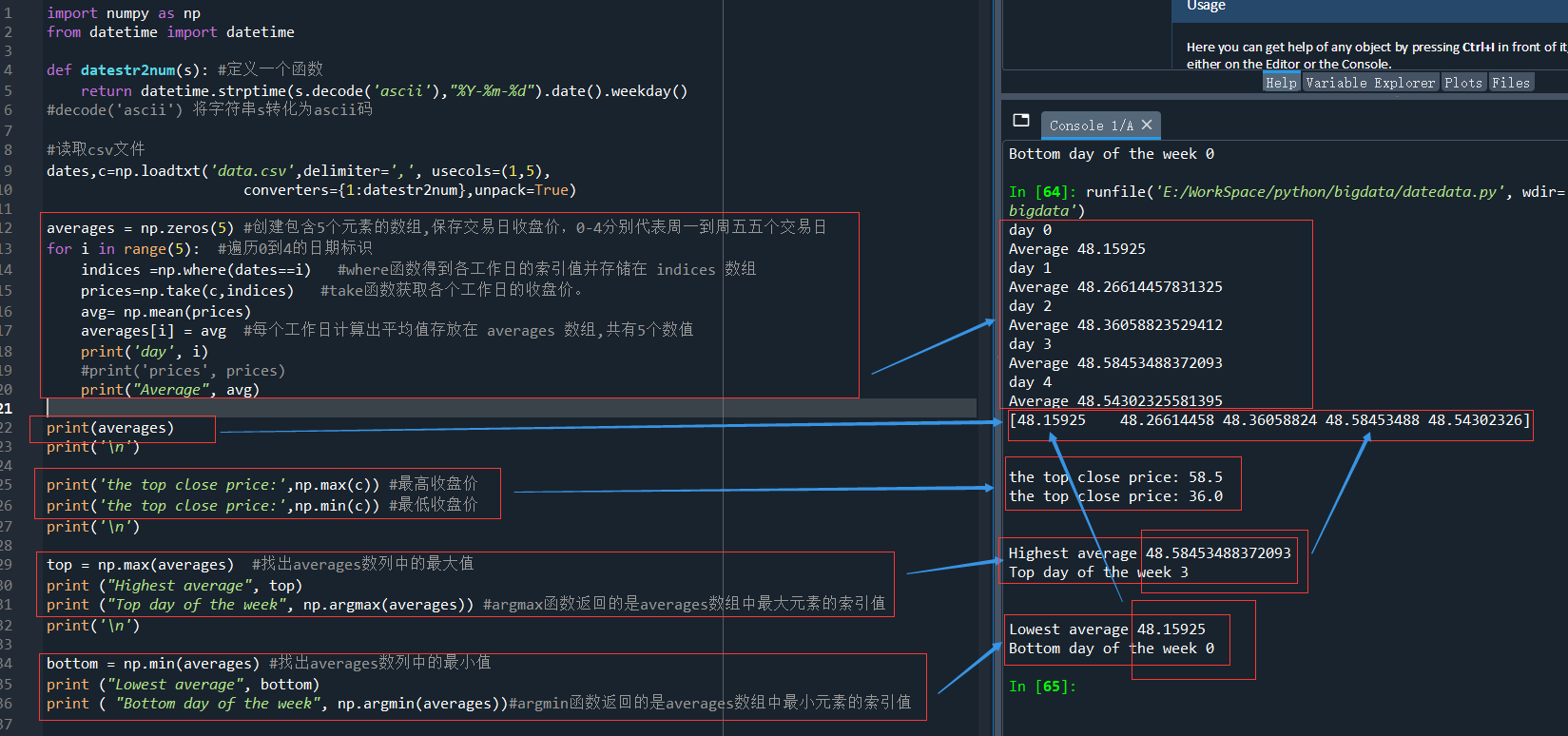
averages = np.zeros(5) #创建包含5个元素的数组,保存交易日收盘价,0-4分别代表周一到周五五个交易日
for i in range(5): #遍历0到4的日期标识
indices =np.where(dates==i) #where函数得到各工作日的索引值并存储在 indices 数组
prices=np.take(c,indices) #take函数获取各个工作日的收盘价。
avg= np.mean(prices) #每个工作日计算出平均值存放在 averages 数组
averages[i] = avg #每个工作日计算出平均值存放在 averages 数组
print('day', i)
#print('prices', prices)
print("Average", avg)
print(averages)
当然除了上述外,还可以求得420天里的最大值、最小值以及交易日平均值中最大值、最小值等,对代码进行如下修:
import numpy as np
from datetime import datetime
def datestr2num(s): #定义一个函数
return datetime.strptime(s.decode('ascii'),"%Y-%m-%d").date().weekday()
#decode('ascii') 将字符串s转化为ascii码
#读取csv文件
dates,c=np.loadtxt('data.csv',delimiter=',', usecols=(1,5),
converters={1:datestr2num},unpack=True)
averages = np.zeros(5) #创建包含5个元素的数组,保存交易日收盘价,0-4分别代表周一到周五五个交易日
for i in range(5): #遍历0到4的日期标识
indices =np.where(dates==i) #where函数得到各工作日的索引值并存储在 indices 数组
prices=np.take(c,indices) #take函数获取各个工作日的收盘价。
avg= np.mean(prices)
averages[i] = avg #每个工作日计算出平均值存放在 averages 数组,共有5个数值
print('day', i)
#print('prices', prices)
print("Average", avg)
print(averages)
print('\n')
print('the top close price:',np.max(c)) #最高收盘价
print('the low close price:',np.min(c)) #最低收盘价
print('\n')
top = np.max(averages) #找出averages数列中的最大值
print ("Highest average", top)
print ("Top day of the week", np.argmax(averages)) #argmax函数返回的是averages数组中最大元素的索引值
print('\n')
bottom = np.min(averages) #找出averages数列中的最小值
print ("Lowest average", bottom)
print ( "Bottom day of the week", np.argmin(averages))#argmin函数返回的是averages数组中最小元素的索引值
运行结果如下:
总结
本篇初步导入了真实的股票交易信息,并利用numpy常见函数对进行了初步的计算,列举了下列常用函数:
loadtxt() 函数可以方便地读取CSV文件,自动切分字段,并将数据载入NumPy数组。
savetxt()创建并保存test.txt文件
np.loadtxt('data.csv', delimiter=',', usecols=(6,7),)usecols参数用来选择读取的数列
np.average(c, weights=v) 加权平均,将v作为权重参数使用,
np.mean(c)) #算术平均值
np.max(h)) #获取最大值max()
np.min(l)) #获取最小值min()
np.ptp(h) ) 用ptp()函数计算了极值差,
np.median(c)) 中位数median()函数,即多个数据中,处于中间的数
np.msort(c))函数对价格数组进行排序,
np.var(c) 方差函数var()
np.diff(c) 函数可以返回一个由相邻数组元素的差值构成的数组
np.std(results) # 标准差
np.diff( np.log(c) )
np.where(results1 > 0) 选择
np.sqrt()#平方根sqrt(),浮点数
s.decode('ascii') 将字符串s转化为ascii码
np.take(c,indices) #take函数获取各个工作日的收盘价。
np.argmax(averages)) #argmax函数返回数组中最大元素的索引值
np.argmin(averages))#argmin函数返回数组中最小元素的索引值
以上就是Python数据分析之NumPy常用函数使用详解的详细内容,更多关于Python NumPy常用函数的资料请关注我们其它相关文章!
相关推荐
-

Python使用Numpy实现Kmeans算法的步骤详解
目录 Kmeans聚类算法介绍: 1.聚类概念: 2.Kmeans算法: 定义: 大概步骤: Kmeans距离测定方式: 3.如何确定最佳的k值(类别数): 手肘法: python实现Kmeans算法: 1.代码如下: 2.代码结果展示: 聚类可视化图: 手肘图: 运行结果: 文章参考: Kmeans聚类算法介绍: 1.聚类概念: 将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类.由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异.
-
Python数据分析 Numpy 的使用方法
目录 简介 多维数组创建 数组的数据类型 数组维度 简介 使用 Python 进行数据分析时,比较常用的库有 Numpy.Pandas.Matplotlib,本篇文章就来说一下 Numpy 的使用方法,编辑器就使用上篇文章说过的 Jupyter. Numpy 是一个Python扩展库,专门做科学计算,也是大部分 Python 科学计算库的基础,Numpy 提供了多维数组对象 ndarray,它是一系列同类型数据的集合,可以进行索引.切片.迭代等操作. 我们可以使用以下命令进行安装: pip in
-
Python numpy.power()函数使用说明
power(x, y) 函数,计算 x 的 y 次方. 示例: x 和 y 为单个数字: import numpy as np print(np.power(2, 3)) 8 分析:2 的 3 次方. x 为列表,y 为单个数字: print(np.power([2,3,4], 3)) [ 8 27 64] 分析:分别求 2, 3, 4 的 3 次方. x 为单个数字,y 为列表: print(np.power(2, [2,3,4])) [ 4 8 16] 分析:分别求 2的 2, 3, 4 次
-
Python NumPy中diag函数的使用说明
NumPy包中的内置diag函数很有意思. 假设创建一个1维数组a,和一个3*3数组b: import numpy as np a = np.arange(1, 4) b = np.arange(1, 10).reshape(3, 3) 结果如下: >>> a array([1, 2, 3]) >>> b array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) 使用diag函数,看一看结果: >>> np.diag(a) ar
-
使用Python NumPy库绘制渐变图案
目录 1. 导入模块 2. 基本绘画流程 3. 生成随机彩色图像 4. 生成渐变色图像 5. 在渐变色背景上画曲线 6. 使用颜色映射(ColorMap) 7. 展示NumPy的魅力 NumPy也可以画图吗?当然!NumPy不仅可以画,还可以画得更好.画得更快!比如下面这幅画,只需要10行代码就可以画出来.若能整明白这10行代码,就意味着叩开了NumPy的大门.请打开你的Python IDLE,跟随我的脚步,一起来体验一下交互式编程的乐趣吧,看看如何用NumPy画图,以及用NumPy可以画出什么
-
Python数据分析之Numpy库的使用详解
目录 前言
-
Python Numpy学习之索引及切片的使用方法
目录 1. 索引及切片 2. 高级索引 1. 索引及切片 数组中的元素可以通过索引以及切片的手段进行访问或者修改,和列表的切片操作一样. 下面直接使用代码进行实现,具体操作方式以及意义以代码注释为准: (1)通过下标以及内置函数进行索引切片 """ Author:XiaoMa date:2021/12/30 """ import numpy as np a = np.arange(10)#创建一个从0-9的一维数组 print(a) i = sl
-
Python数据分析之NumPy常用函数使用详解
目录 文件读入 1.保存或创建新文件 2.读取csv文件的函数loadtxt 3.常见的函数 4.股票的收益率等 5.对数收益与波动率 6.日期分析 总结 本篇我们将以分析历史股价为例,介绍怎样从文件中载入数据,以及怎样使用NumPy的基本数学和统计分析函数.学习读写文件的方法,并尝试函数式编程和NumPy线性代数运算,来学习NumPy的常用函数. 文件读入 读写文件是数据分析的一项基本技能 CSV(Comma-Separated Value,逗号分隔值)格式是一种常见的文件格式.通常,数据库的
-
Python列表常用函数使用详解
目录 介绍 append() extend() insert() pop() remove() 介绍 append() 语法 list.append( element ) 参数 element:任何类型的元素 列表「末尾」添加元素 name_list = ['zhangsan', 'lisi', 'wangwu'] name_list.append('zhaoliu') print(name_list) 输出: ['zhangsan', 'lisi', 'wangwu', 'zhaoliu'
-
Python asyncio常用函数使用详解
目录 协程的定义 协程的运行 多个协程运行 关于loop.close() 回调 事件循环 协程的定义 需要使用 async def 语句 协程可以做哪些事: 1.等待一个future结果 2.等待另一个协程(产生一个结果或引发一个异常) 3.产生一个结果给正在等它的协程 4.引发一个异常给正在等它的协程 协程的运行 调用协程函数,协程不会开始运行,只是返回一个协程对象 要让协程对象运行有两种方式: 1.在另一个已经运行的协程中用await等待它 2.通过ensure_future函数计划它的执行
-
python matplotlib中的subplot函数使用详解
python里面的matplotlib.pylot是大家比较常用的,功能也还不错的一个包.基本框架比较简单,但是做一个功能完善且比较好看整洁的图,免不了要网上查找一些函数.于是,为了节省时间,可以一劳永逸.我把常用函数作了一个总结,最后写了一个例子,以后基本不用怎么改了. 一.作图流程: 1.准备数据, , 3作图, 4定制, 5保存, 6显示 1.数据可以是numpy数组,也可以是list 2创建画布: import matplotlib.pyplot as plt #figure(num=N
-
calendar在python3时间中常用函数举例详解
想要在python中写代码游刃有余,没有函数的支持是万万不行的.很多小伙伴反映,最近函数的应用知识不够了,所以小编挑选了python3时间中的函数,希望可以帮助大家在处理日历方面更加的迅速.其他更多的函数,大家也可以自行去搜集一点资料学习,小编就讲几个最简单的吧. 1.firstweekday() firstweekday(): 返回当前每周起始日期值.默认情况下,首次载入calendar模块时返回0,即星期一 import calendar # 0 print(calendar.firstwe
-
Python基础之Numpy的基本用法详解
一.数据生成 1.1 手写数组 a = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]) # 一维数组 b = np.array([[1, 2], [3, 4]]) #二维数组 1.2 序列数组 numpy.arange(start, stop, step, dtype),start默认0,step默认1 c = np.arange(0, 10, 1, dtype=int) # =np.arange(10) [0 1 2 3 4 5 6 7 8 9] d
-
Python入门之三角函数sin()函数实例详解
描述 sin()返回的x弧度的正弦值. 语法 以下是sin()方法的语法: importmath math.sin(x) 注意:sin()是不能直接访问的,需要导入math模块,然后通过math静态对象调用该方法. 参数 x--一个数值. 返回值 返回的x弧度的正弦值,数值在-1到1之间. 实例 以下展示了使用sin()方法的实例: #!/usr/bin/python import math print "sin(3) : ", math.sin(3) print "sin(
-
Python入门之三角函数tan()函数实例详解
描述 tan() 返回x弧度的正弦值. 语法 以下是 tan() 方法的语法: import math math.tan(x) 注意:tan()是不能直接访问的,需要导入 math 模块,然后通过 math 静态对象调用该方法. 参数 x -- 一个数值. 返回值 返回x弧度的正弦值,数值在 -1 到 1 之间. 实例 以下展示了使用 tan() 方法的实例: #!/usr/bin/python import math print "tan(3) : ", math.tan(3) pr
-
python中强大的format函数实例详解
python中format函数用于字符串的格式化 自python2.6开始,新增了一种格式化字符串的函数str.format(),此函数可以快速处理各种字符串. 语法 它通过{}和:来代替%. 请看下面的示例,基本上总结了format函数在python的中所有用法 #通过位置 print '{0},{1}'.format('chuhao',20) print '{},{}'.format('chuhao',20) print '{1},{0},{1}'.format('chuhao',20) #