汇编语言中的函数调用参数传递及全局与局部变量与“基址”

作为刚往底层方向走的一只菜鸟,今天为各位分享一篇名为汇编眼中的函数调用参数传递以及全局、局部变量与“基址”,好了,废话不多说,先来看看C语言代码:

本次的分享主要以画堆栈图为主,通过画图的方式来看看这段代码是如何运作的

我们先写一句汇编代码,mov eax,eax其实这句代码并没有什么用,也就是将eax的值移入eax中,这句代码对于我们的作用仅作为断点,我们F5运行下程序并且切换到反编译界面
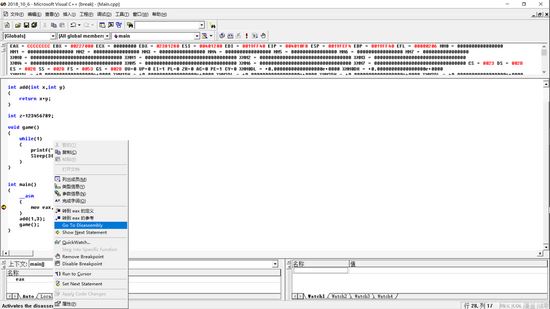
右键之后点击Go To Disassemble,也就是进入反编译界面,我们来看看反编译的代码

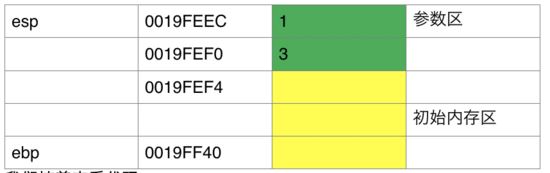
这就是咱们main函数反编译后的结果,那么现在我们记录一下ebp,esp的值,并且画出现在的堆栈图

ESP = 0019FEF4
EBP = 0019FF40

黄色=ebp~esp初始的内存
那好,我们继续来看代码
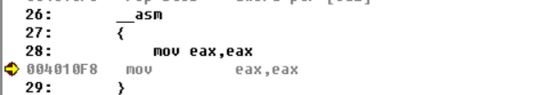
这里是我们自己写的汇编代码,编译器也没有改动过可以说是本色出演,这里内存没有变化,好,那么我们接着来看add函数这里的调用

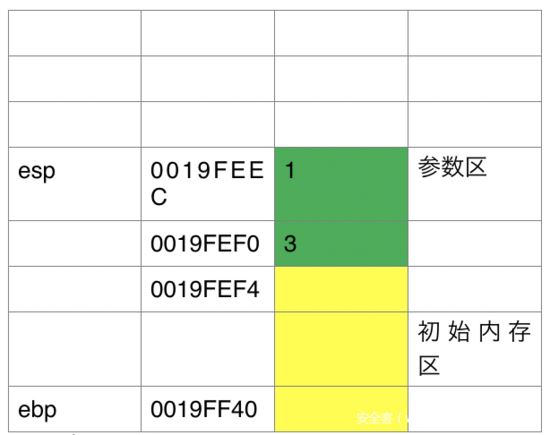
可以看到函数调用的时候首先是将3、1这两个值推入栈中,但是又有疑问了“add函数的调用是这样的add(1,3),为啥首先推入栈中的是3而不是1呢?”之所以这样是因为栈中是先进后出的,所以参数进入栈中的顺序是从右向左的,当然这里也可以看到函数中的参数是压入栈中然后取出来而不是通过通用寄存器eax,edx,ebx这些来传送参数的,其实这也好理解,因为通用寄存器只有八个,像esp,eip,ebp这样的寄存器还不能随便改,能用的也只有剩下的几个,参数超过剩下的几个咋办?那就只能用堆栈了。我们继续来看F10单步执行一下,看看堆栈的变化

我们再看看EBP和ESP

这里可以看到压入一个3后栈顶指针减去了4h,至于为啥减去4h呢?是因为一个int类型的数据宽度是4Byte=32Bit,能存入的最大数也就是0xFFFFFFFF,16进制数又是2进制数的简写形式,一个二进制数需要4Bit来存储,所以4位二进制数最大的值为1111转换为16进制后刚好为F,这样也方便了开发者,存储空间中我们看到的数据都是16进制数

可能以上讲得有些出入,如有错误,请帮忙纠正,好了,我们接着来看,接下来push 1进去,我们来看看现在的堆栈图:

继续看下面的代码:

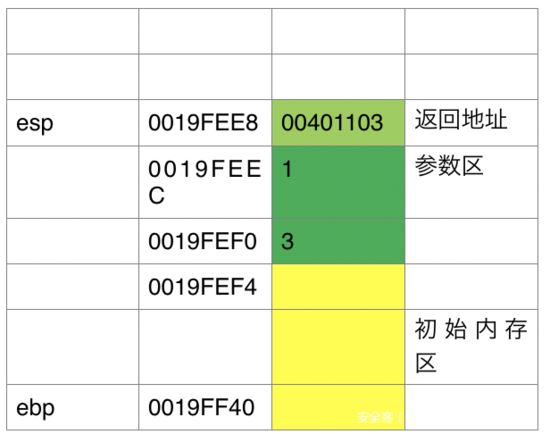
接着是call,call指令在汇编中多用于函数调用,call指令做了两个操作,
1.Push 00401103(下一行代码地址) 2.Jmp 0040100A(函数地址)
这里我们F11一下,遇到call指令后按F11进入函数即可,这样我们就可以看到函数体中的指令
这里CALL之后看看堆栈中的变化:
继续向下走,F11后跳转到的结果如下

这里是编译器决定的,不是所有编译器call后会进入一个jmp指令中转,再F11一下
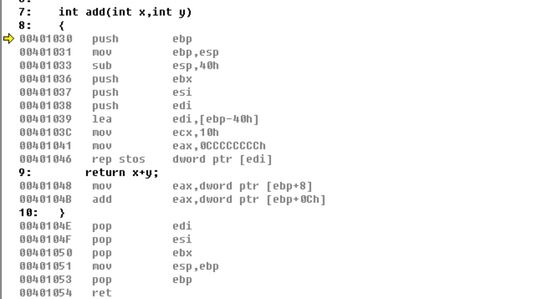
Jmp执行之后直接进入了函数体,这里将通用寄存器ebp的值存入栈中,之所以存入栈中是因为每一个函数中都要使用ebp来寻址,所以需要将ebp的原始值存入栈中,随后将esp栈顶指针的值移入ebp中,sub esp,40h是将栈顶指针加到40h这个位置,之所以是减40h是因为栈空间是从高到低的,现在我们单步执行一下看看栈中的变化
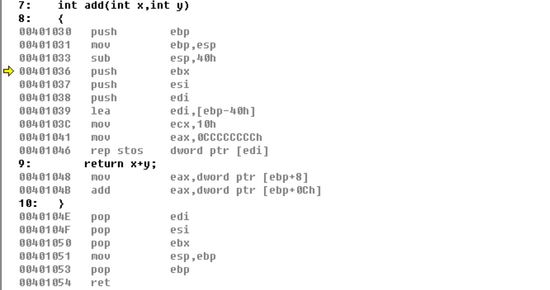

这里40h移动的位置=40h/4h=10h=16,我们看看现在堆栈的变化
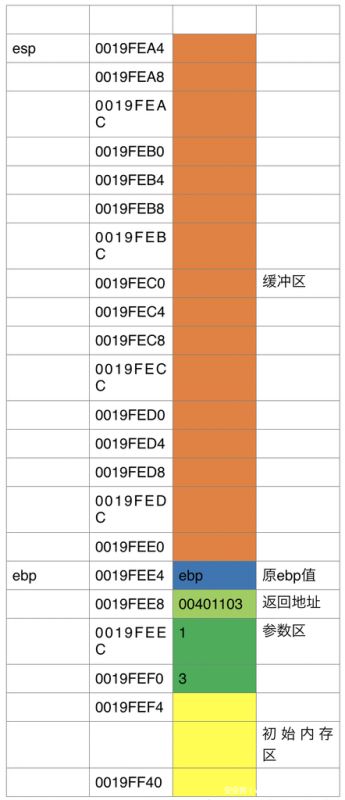
Sub esp,40h这段代码我们是为函数开辟一块栈空间出来供函数存取值的,也就是我们常说的缓冲区,通常用来存储函数中的局部变量,我们接着往下看
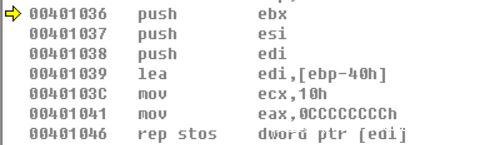
接着向栈中推入了ebx,esi,edi,栈顶指针[esp-Ch],然后lea指令将[ebp-40h]的地址放入edi中,给ecx赋值为10h=16,也就是循环16次又将0xCCCCCCCCh赋给eax,这也被称为断点字符,然后使用rep指令将缓冲区中的值赋值为0xCCCCCCCCh,现在我们再来看看堆栈中的变化
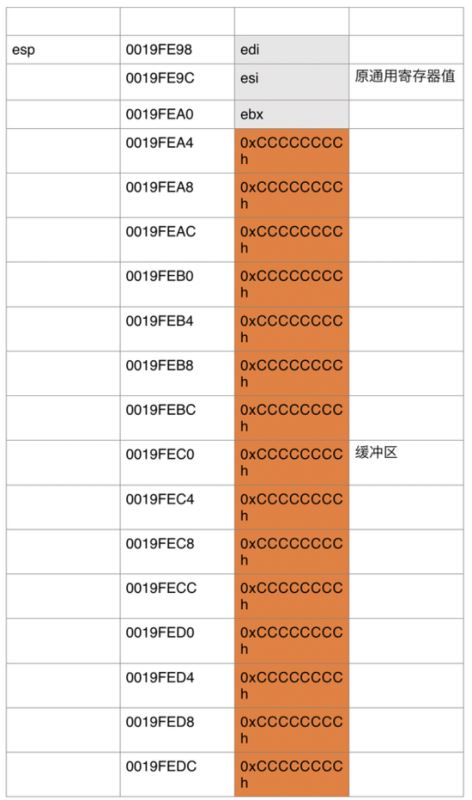
我们看一下单步执行后的esp和ebp的结果
好勒,咱们接着往下走
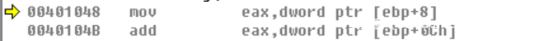
这里可以看到首先是将栈中的[ebp+8]=0019FEE4+8=0019FEEC地址中的值移动到eax中,然后将eax与[ebp+Ch]=0019FEE4+Ch=0019FEF0地址中的值相加,并且将相加后的值存入eax中,栈空间无任何变化,变化的仅仅是eax,咱们单步执行看下

好了,我们接着往下看
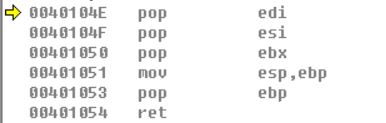
首先将edi,esi,ebx中的值取出来,这里可以看到,我们推入和取出的顺序刚好相反,先进后出的道理,随后将ebp的值移动到esp中,这里也就改变了栈顶指针,然后pop ebp,最后ret,ret的做的操作:
pop eip(这里取出的是返回地址)
咱们单步执行一下

我们接着来看代码

这里esp+8是为了堆栈平衡,恢复最初的堆栈,我们单步一下
堆栈的变化如下:

这样就和我们没进入函数之前的堆栈一样了,程序到这里就解释了函数调用以及传参的问题。我们接着往下走

函数调用又是一个call,call的两个操作:
1、Push 0040110B(下一行代码地址)
2、Jmp 00401005(函数地址)
单步会遇到jmp,我们直接单步进入函数体

对于这里的堆栈就不画了,主要讲解一下这里的全局变量以及“基址”是啥,这里我们的全局变量z是由变量定义的时候分配指定的内存地址,在每一个函数中都可以找到,每一个全局变量都有一个唯一的内存地址,有且只有一个,在游戏外挂中经常会听到找“基址”,然而这个“基址”就是全局变量的地址,只要程序被编译那么就只有这么一个指定的地址,我们这个程序中z的地址[00424a30],打开CE
首先我们运行一下我们写好的程序
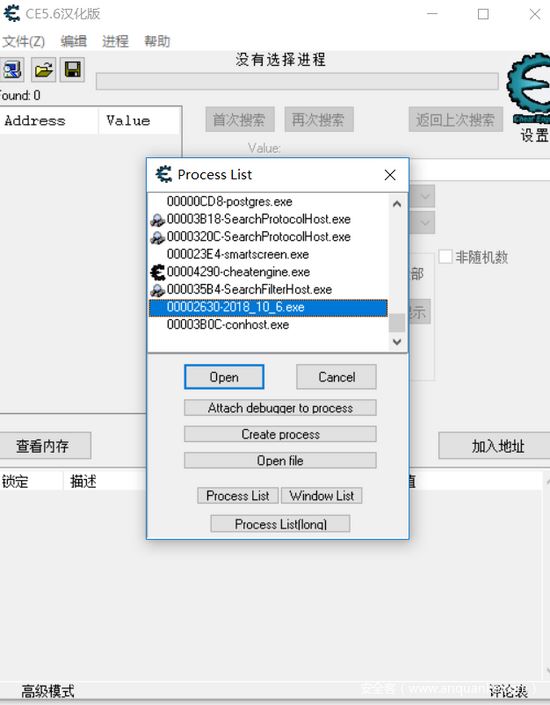
选择我们刚才运行的程序,点击加入地址,我们将00424a30这个内存地址加入进去
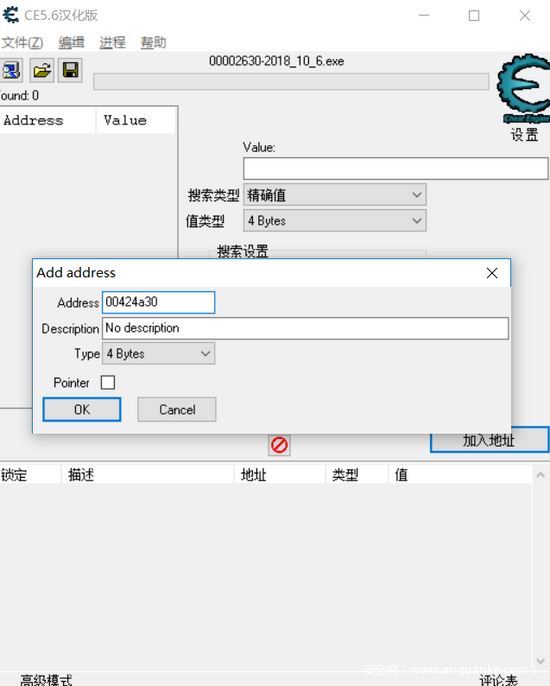
点击ok,我们看看它的初始值
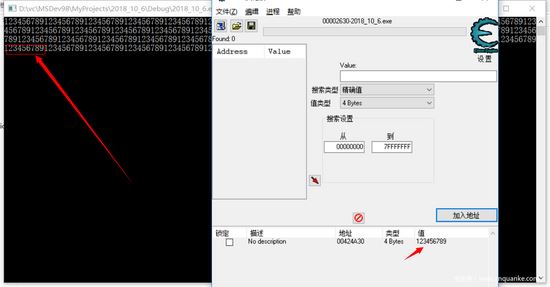
这里完全没有自己输入值,我们改一下值,看看程序的输出
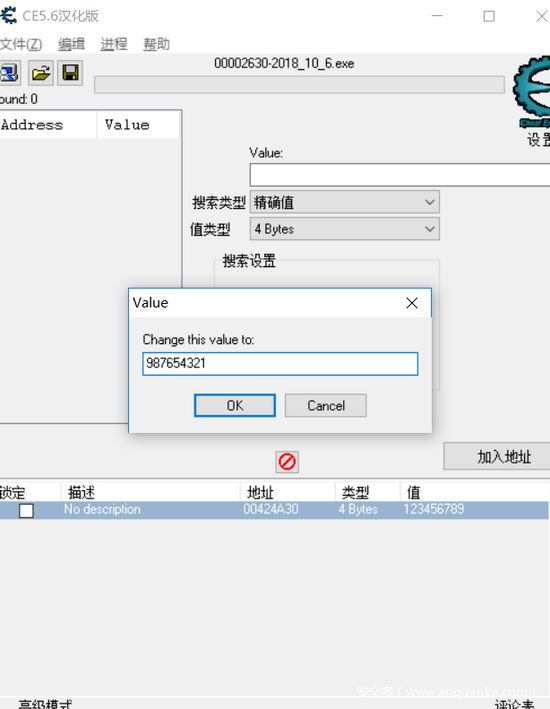
点击OK,再看一下改了之后输出的值
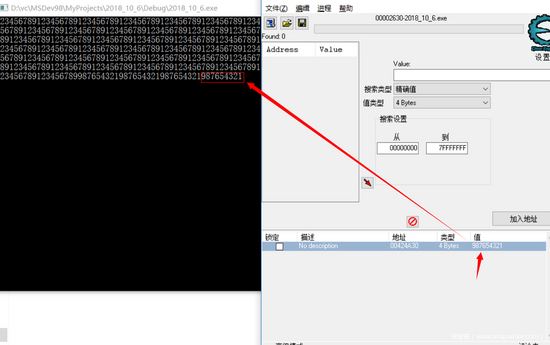
总结:
1、全局变量是编译后分配的一个指定内存空间,因为是公共的所以任何程序或者程序中的函数都可以调用以及修改。
2、局部变量的地址是随机的,因为每次进入函数都会随机分配一段地址给函数,这段分配的地址称为缓冲区,缓冲区也是用来存储局部变量的。
3、“基址”就是全局变量,这是外挂开发中常用到的一个词汇。
4、函数调用使用call,call指令做的两个操作:
(1)push call指令下一行地址
(2)Jmp 函数地址(编译器决定,可能先跳转到中转地址,然后跳转到函数地址)
5、汇编中的函数就是指令的集合,唯一不同的是函数最后都会用ret返回
6、函数中的参数传递是使用堆栈来传递的。
以上所述是小编给大家介绍的汇编语言中的函数调用参数传递及全局与局部变量与“基址”,希望对大家有所帮助!
相关推荐
-

汇编 函数调用的实现
1. 从代码的顺序执行说起 每一个程序员脑子里应该都有这么一种印象:"程序是顺序执行的".这个观点其实和我们开篇所讲的cpu的流水线执行过程直接相关. 让我们再回忆一下脑海中关于函数调用的概念,也许会是这个样子: 这里的"控制流转移"又是如何发生的呢?在解释这个之前,也许我们需要科普一点有关于汇编的知识. 2. 函数调用中的一些细节说明 2.1 函数调用中的关键寄存器 2.1.1 程序计数器PC 程序计数器是一个计算机组成原理中讲过的概念,下面给出一个百度百科中的简
-
c文件汇编后函数参数传递的不同之处
mac下clang编译后函数的参数先保存在寄存器中(以一定的规则保存),然后在函数中压入栈里,以待后用.例如上篇例子,红色部分: 复制代码 代码如下: .global _decToBin _decToBin: pushq %rbp movq %rsp,%rbp movq %rdi,-8(%rbp) #第一个参数,保存在rdi中 movq %rsi,-16(%rbp) #第二个参数,保存在rsi中 movq -8(%rbp),%rax
-
使用汇编语言实现if else 循环函数调用的具体方法
需要使用汇编来演示如下代码 需要下载ollydbg汇编调试器 点击File-Open随意打开一个exe文件 我这里随便找到c:/windows/explorer.exe文件 这里EIP的值表示下一次运行需要执行的代码位置 双击 EIP红色地址 左边代码会自动跳转到对应的代码行 有了以下环节 接下来添加代码 如果替换的代码 占用的字节数 小于原始的代码数 会自动补充 nop空指令 一.实现 if else MOV EAX,1 表示将1立即数 设置给EAX寄存器 CMP EAX,1 比较EAX的值和
-
汇编语言中的函数调用参数传递及全局与局部变量与“基址”
作为刚往底层方向走的一只菜鸟,今天为各位分享一篇名为汇编眼中的函数调用参数传递以及全局.局部变量与"基址",好了,废话不多说,先来看看C语言代码: 本次的分享主要以画堆栈图为主,通过画图的方式来看看这段代码是如何运作的 我们先写一句汇编代码,mov eax,eax其实这句代码并没有什么用,也就是将eax的值移入eax中,这句代码对于我们的作用仅作为断点,我们F5运行下程序并且切换到反编译界面 右键之后点击Go To Disassemble,也就是进入反编译界面,我们来看看反编译的代码
-
汇编语言中的各种寄存器介绍
汇编语言(assembly language)是一种用于电子计算机.微处理器.微控制器或其他可编程器件的低级语言,亦称为符号语言.在汇编语言中,用助记符代替机器指令的操作码,用地址符号或标号代替指令或操作数的地址.在不同的设备中,汇编语言对应着不同的机器语言指令集,通过汇编过程转换成机器指令.特定的汇编语言和特定的机器语言指令集是一一对应的,不同平台之间不可直接移植. 计算机寄存器分类简介: 32位CPU所含有的寄存器有: 4个数据寄存器(EAX.EBX.ECX和EDX) 2个变址和指针寄存器(
-
AngularJS中一般函数参数传递用法分析
本文实例讲述了AngularJS中一般函数参数传递用法.分享给大家供大家参考,具体如下: 1. 模型参数 直接使用变量名,不要加引号 <!doctype html> <html ng-app="passAter"> <head> <meta charset="utf-8"/> </head> <body> <div ng-controller="passCtrl">
-
Javascript中使用exec进行正则表达式全局匹配时的注意事项
本文就是介绍在使用 Javascript 中使用 exec 进行正则表达式全局匹配时的注意事项. 先看一下常见的用法: 复制代码 代码如下: <script type="text/javascript"> var pattern = /http:\/\/([^\/\s]+)/; alert(pattern.exec('http://www.codebit.cn')); // http://www.codebit.cn,www.codebit.cn alert(pattern
-
浅谈Python中函数的参数传递
1.普通的参数传递 >>> def add(a,b): return a+b >>> print add(1,2) 3 >>> print add('abc','123') abc123 2.参数个数可选,参数有默认值的传递 >>> def myjoin(string,sep='_'): return sep.join(string) >>> myjoin('Test') 'T_e_s_t' >>>
-
python中私有函数调用方法解密
本文实例讲述了python中私有函数调用方法.分享给大家供大家参考,具体如下: 与大多数语言一样,Python 也有私有的概念: ① 私有函数不可以从它们的模块外面被调用 ② 私有类方法不能够从它们的类外面被调用 ③ 私有属性不能够从它们的类外面被访问 与大多数的语言不同,一个 Python 函数,方法,或属性是私有还是公有,完全取决于它的名字. 如果一个 Python 函数,类方法,或属性的名字以两个下划线开始(但不是结束),它是私有的:其它所有的都是公有的. Python 没有类方法 保护
-
java 中函数的参数传递详细介绍
java中函数的参数传递 总结: 1.将对象(对象的引用)作为参数传递时传递的是引用(相当于指针).也就是说函数内对参数所做的修改会影响原来的对象. 2.当将基本类型或基本类型的包装集作为参数传递时,传递的是值.也就是说函数内对参数所做的修改不会影响原来的变量. 3.数组(数组引用))作为参数传递时传递的是引用(相当于指针).也就是说函数内对参数所做的修改会影响原来的数组. 4.String类型(引用)作为参数传递时传递的是引用,只是对String做出任何修改时有一个新的String
-
深入学习 JavaScript中的函数调用
定义 可能很多人在学习 JavaScript 过程中碰到过函数参数传递方式的迷惑,本着深入的精神,我想再源码中寻找些答案不过在做这件事之前,首先明确几个概念.抛弃掉值传递.引用传递等固有叫法,回归英文: call by reference && call by value && call by sharing 分别是我们理解的 C++ 中的引用传递,值传递.第三种比较迷惑,官方解释是 receives the copy of the reference to object
-
浅谈在linux kernel中打印函数调用的堆栈的方法
在Linux内核调试中,经常用到的打印函数调用堆栈的方法非常简单,只需在需要查看堆栈的函数中加入: dump_stack(); 或 __backtrace(); 即可 dump_stack()在~/kernel/ lib/Dump_stack.c中定义 void dump_stack(void) { printk(KERN_NOTICE "This architecture does not implement dump_stack()/n"); } __backtrace()的定义在
-
c#继承中的函数调用实例
本文实例讲述了c#继承中的函数调用方法,分享给大家供大家参考.具体分析如下: 首先看下面的代码: 复制代码 代码如下: using System; namespace Test { public class Base { public void Print() { Console.WriteLine(Operate(8, 4)); } protected virtual int Ope