pytorch使用 to 进行类型转换方式
在程序中,有多种方法进行强制类型转换。
本博文将介绍一个非常常用的方法:to()方法。
我们通常使用它来进行GPU和CPU的类型转换,但其实也可以用来进行torch的dtype转换。
常见方法:tensor.to(‘cuda:0')
先看官网介绍:
**Performs Tensor dtype and/or device conversion. A torch.dtype and torch.device are inferred from the arguments of self.to(*args, kwargs).
本文举一个例子,将一个tensor转化成与另一个tensor相同的数据类型和相同GPU或CPU类型
import torch device = 'cuda:0' a = torch.zeros(2, 3) print(type(a)) b = torch.ones(3, 4).to(device) print(type(b)) c = torch.matmul(a, b) print(type(c))
我们看到这个代码会出错的。因为a和b是不同的device,一个是CPU,一个是GPU,不能运行。
修改如下:
a = a.to(b) d = torch.matmul(a, b) print(type(d))
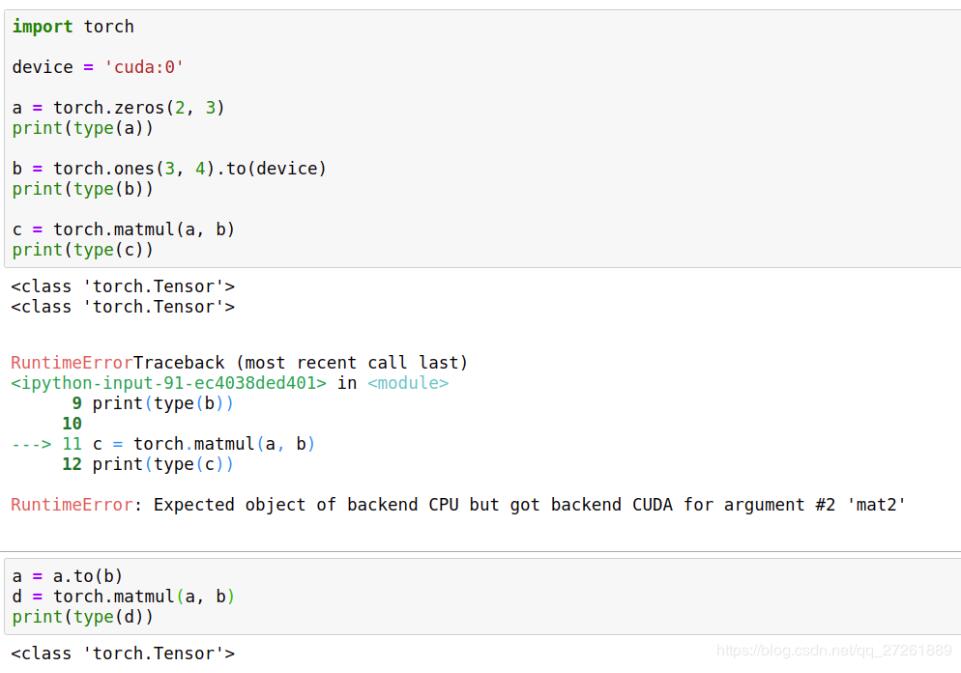
可以看到to还是很好用的,尤其是不确定我们的数据类型和device时。
其实pytorch中还有很多其他方法可以这么做,以后会继续介绍。
以上这篇pytorch使用 to 进行类型转换方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pytorch: tensor类型的构建与相互转换实例
Summary 主要包括以下三种途径: 使用独立的函数: 使用torch.type()函数: 使用type_as(tesnor)将张量转换为给定类型的张量. 使用独立函数 import torch tensor = torch.randn(3, 5) print(tensor) # torch.long() 将tensor投射为long类型 long_tensor = tensor.long() print(long_tensor) # torch.half()将tensor投射为半精度浮点类型
-
Pyorch之numpy与torch之间相互转换方式
numpy中的ndarray转化成pytorch中的tensor : torch.from_numpy() pytorch中的tensor转化成numpy中的ndarray : numpy() 代码 import numpy as np import torch np_arr = np.array([1,2,3,4]) tor_arr=torch.from_numpy(np_arr) tor2numpy=tor_arr.numpy() print('\nnumpy\n',np_arr,'\nto
-
pytorch中tensor张量数据类型的转化方式
1.tensor张量与numpy相互转换 tensor ----->numpy import torch a=torch.ones([2,5]) tensor([[1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.]]) # ********************************** b=a.numpy() array([[1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.]], dtype=float32) numpy --
-
Pytorch to(device)用法
如下所示: device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model.to(device) 这两行代码放在读取数据之前. mytensor = my_tensor.to(device) 这行代码的意思是将所有最开始读取数据时的tensor变量copy一份到device所指定的GPU上去,之后的运算都在GPU上进行. 这句话需要写的次数等于需要保存GPU上的tensor变
-
torch 中各种图像格式转换的实现方法
PIL:使用python自带图像处理库读取出来的图片格式 numpy:使用python-opencv库读取出来的图片格式 tensor:pytorch中训练时所采取的向量格式(当然也可以说图片) PIL与Tensor相互转换 import torch from PIL import Image import matplotlib.pyplot as plt # loader使用torchvision中自带的transforms函数 loader = transforms.Compose([ tr
-
pytorch numpy list类型之间的相互转换实例
如下所示: import torch from torch.autograd import Variable import numpy as np ''' pytorch中Variable与torch.Tensor类型的相互转换 ''' # 1.torch.Tensor转换成Variablea=torch.randn((5,3)) b=Variable(a) print('a',a.type(),a.shape) print('b',type(b),b.shape) # 2.Variable转换
-
pytorch使用 to 进行类型转换方式
在程序中,有多种方法进行强制类型转换. 本博文将介绍一个非常常用的方法:to()方法. 我们通常使用它来进行GPU和CPU的类型转换,但其实也可以用来进行torch的dtype转换. 常见方法:tensor.to('cuda:0') 先看官网介绍: **Performs Tensor dtype and/or device conversion. A torch.dtype and torch.device are inferred from the arguments of self.to(*
-
Pytorch.nn.conv2d 过程验证方式(单,多通道卷积过程)
今天在看文档的时候,发现pytorch 的conv操作不是很明白,于是有了一下记录 首先提出两个问题: 1.输入图片是单通道情况下的filters是如何操作的? 即一通道卷积核卷积过程 2.输入图片是多通道情况下的filters是如何操作的? 即多通道多个卷积核卷积过程 这里首先贴出官方文档: classtorch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1
-
pytorch 自定义参数不更新方式
nn.Module中定义参数:不需要加cuda,可以求导,反向传播 class BiFPN(nn.Module): def __init__(self, fpn_sizes): self.w1 = nn.Parameter(torch.rand(1)) print("no---------------------------------------------------",self.w1.data, self.w1.grad) 下面这个例子说明中间变量可能没有梯度,但是最终变量有梯度
-
Pytorch实现神经网络的分类方式
本文用于利用Pytorch实现神经网络的分类!!! 1.训练神经网络分类模型 import torch from torch.autograd import Variable import matplotlib.pyplot as plt import torch.nn.functional as F import torch.utils.data as Data torch.manual_seed(1)#设置随机种子,使得每次生成的随机数是确定的 BATCH_SIZE = 5#设置batch
-
关于Pytorch的MLP模块实现方式
MLP分类效果一般好于线性分类器,即将特征输入MLP中再经过softmax来进行分类. 具体实现为将原先线性分类模块: self.classifier = nn.Linear(config.hidden_size, num_labels) 替换为: self.classifier = MLP(config.hidden_size, num_labels) 并且添加MLP模块: class MLP(nn.Module): def __init__(self, input_size, common_
-
Pytorch DataLoader 变长数据处理方式
关于Pytorch中怎么自定义Dataset数据集类.怎样使用DataLoader迭代加载数据,这篇官方文档已经说得很清楚了,这里就不在赘述. 现在的问题:有的时候,特别对于NLP任务来说,输入的数据可能不是定长的,比如多个句子的长度一般不会一致,这时候使用DataLoader加载数据时,不定长的句子会被胡乱切分,这肯定是不行的. 解决方法是重写DataLoader的collate_fn,具体方法如下: # 假如每一个样本为: sample = { # 一个句子中各个词的id 'token_li
-
Pytorch释放显存占用方式
如果在python内调用pytorch有可能显存和GPU占用不会被自动释放,此时需要加入如下代码 torch.cuda.empty_cache() 我们来看一下官方文档的说明 Releases all unoccupied cached memory currently held by the caching allocator so that those can be used in other GPU application and visible in nvidia-smi. Note e
-
基于pytorch padding=SAME的解决方式
tensorflow中的conv2有padding='SAME'这个参数.吴恩达讲课中说到当padding=(f-1)/2(f为卷积核大小)时则是SAME策略.但是这个没有考虑到空洞卷积的情况,也没有考虑到strides的情况. 查阅资料后发现网上方法比较麻烦. 手算,实验了一个早上,终于初步解决了问题. 分为两步: 填充多少 中文文档中有计算公式: 输入: 输出: 因为卷积后图片大小同卷积前,所以这里W_out=W_in, H_out=H_in.解一元一次方程即可.结果取ceil. 怎么填充
-

详解C++中常用的四种类型转换方式
目录 1.静态类型转换:static_cast(exp) 2.动态类型转换:dynamic_cast(exp) 3.常类型转换:const_case(exp) 4. 解释类型转换: reinterpret_cast(exp) 1.静态类型转换:static_cast(exp) 1.1静态类型转换主要用于两种转换环境 1.1.1 C++内置类型的转换:与C风格强转类似. 与c相同的地方: #include <iostream> using namespace std; int main() {
-
Pytorch加载数据集的方式总结及补充
目录 前言 一.自己重写定义(Dataset.DataLoader) 二.用Pytorch自带的类(ImageFolder.datasets.DataLoader) 2.1 加载自己的数据集 2.1.1 ImageFolder介绍 2.2.2 ImageFolder加载数据集完整例子 2.2 加载常见的数据集 三.总结 四.transforms变换讲解 五.DataLoader的补充 总结 前言 在用Pytorch加载数据集时,看GitHub上的代码经常会用到ImageFolder.DataLo