利用Tensorflow构建和训练自己的CNN来做简单的验证码识别方式
Tensorflow是目前最流行的深度学习框架,我们可以用它来搭建自己的卷积神经网络并训练自己的分类器,本文介绍怎样使用Tensorflow构建自己的CNN,怎样训练用于简单的验证码识别的分类器。本文假设你已经安装好了Tensorflow,了解过CNN的一些知识。
下面将分步介绍怎样获得训练数据,怎样使用tensorflow构建卷积神经网络,怎样训练,以及怎样测试训练出来的分类器
1. 准备训练样本
使用Python的库captcha来生成我们需要的训练样本,代码如下:
import sys
import os
import shutil
import random
import time
#captcha是用于生成验证码图片的库,可以 pip install captcha 来安装它
from captcha.image import ImageCaptcha
#用于生成验证码的字符集
CHAR_SET = ['0','1','2','3','4','5','6','7','8','9']
#字符集的长度
CHAR_SET_LEN = 10
#验证码的长度,每个验证码由4个数字组成
CAPTCHA_LEN = 4
#验证码图片的存放路径
CAPTCHA_IMAGE_PATH = 'E:/Tensorflow/captcha/images/'
#用于模型测试的验证码图片的存放路径,它里面的验证码图片作为测试集
TEST_IMAGE_PATH = 'E:/Tensorflow/captcha/test/'
#用于模型测试的验证码图片的个数,从生成的验证码图片中取出来放入测试集中
TEST_IMAGE_NUMBER = 50
#生成验证码图片,4位的十进制数字可以有10000种验证码
def generate_captcha_image(charSet = CHAR_SET, charSetLen=CHAR_SET_LEN, captchaImgPath=CAPTCHA_IMAGE_PATH):
k = 0
total = 1
for i in range(CAPTCHA_LEN):
total *= charSetLen
for i in range(charSetLen):
for j in range(charSetLen):
for m in range(charSetLen):
for n in range(charSetLen):
captcha_text = charSet[i] + charSet[j] + charSet[m] + charSet[n]
image = ImageCaptcha()
image.write(captcha_text, captchaImgPath + captcha_text + '.jpg')
k += 1
sys.stdout.write("\rCreating %d/%d" % (k, total))
sys.stdout.flush()
#从验证码的图片集中取出一部分作为测试集,这些图片不参加训练,只用于模型的测试
def prepare_test_set():
fileNameList = []
for filePath in os.listdir(CAPTCHA_IMAGE_PATH):
captcha_name = filePath.split('/')[-1]
fileNameList.append(captcha_name)
random.seed(time.time())
random.shuffle(fileNameList)
for i in range(TEST_IMAGE_NUMBER):
name = fileNameList[i]
shutil.move(CAPTCHA_IMAGE_PATH + name, TEST_IMAGE_PATH + name)
if __name__ == '__main__':
generate_captcha_image(CHAR_SET, CHAR_SET_LEN, CAPTCHA_IMAGE_PATH)
prepare_test_set()
sys.stdout.write("\nFinished")
sys.stdout.flush()
运行上面的代码,可以生成验证码图片,
生成的验证码图片如下图所示:


2. 构建CNN,训练分类器
代码如下:
import tensorflow as tf
import numpy as np
from PIL import Image
import os
import random
import time
#验证码图片的存放路径
CAPTCHA_IMAGE_PATH = 'E:/Tensorflow/captcha/images/'
#验证码图片的宽度
CAPTCHA_IMAGE_WIDHT = 160
#验证码图片的高度
CAPTCHA_IMAGE_HEIGHT = 60
CHAR_SET_LEN = 10
CAPTCHA_LEN = 4
#60%的验证码图片放入训练集中
TRAIN_IMAGE_PERCENT = 0.6
#训练集,用于训练的验证码图片的文件名
TRAINING_IMAGE_NAME = []
#验证集,用于模型验证的验证码图片的文件名
VALIDATION_IMAGE_NAME = []
#存放训练好的模型的路径
MODEL_SAVE_PATH = 'E:/Tensorflow/captcha/models/'
def get_image_file_name(imgPath=CAPTCHA_IMAGE_PATH):
fileName = []
total = 0
for filePath in os.listdir(imgPath):
captcha_name = filePath.split('/')[-1]
fileName.append(captcha_name)
total += 1
return fileName, total
#将验证码转换为训练时用的标签向量,维数是 40
#例如,如果验证码是 ‘0296' ,则对应的标签是
# [1 0 0 0 0 0 0 0 0 0
# 0 0 1 0 0 0 0 0 0 0
# 0 0 0 0 0 0 0 0 0 1
# 0 0 0 0 0 0 1 0 0 0]
def name2label(name):
label = np.zeros(CAPTCHA_LEN * CHAR_SET_LEN)
for i, c in enumerate(name):
idx = i*CHAR_SET_LEN + ord(c) - ord('0')
label[idx] = 1
return label
#取得验证码图片的数据以及它的标签
def get_data_and_label(fileName, filePath=CAPTCHA_IMAGE_PATH):
pathName = os.path.join(filePath, fileName)
img = Image.open(pathName)
#转为灰度图
img = img.convert("L")
image_array = np.array(img)
image_data = image_array.flatten()/255
image_label = name2label(fileName[0:CAPTCHA_LEN])
return image_data, image_label
#生成一个训练batch
def get_next_batch(batchSize=32, trainOrTest='train', step=0):
batch_data = np.zeros([batchSize, CAPTCHA_IMAGE_WIDHT*CAPTCHA_IMAGE_HEIGHT])
batch_label = np.zeros([batchSize, CAPTCHA_LEN * CHAR_SET_LEN])
fileNameList = TRAINING_IMAGE_NAME
if trainOrTest == 'validate':
fileNameList = VALIDATION_IMAGE_NAME
totalNumber = len(fileNameList)
indexStart = step*batchSize
for i in range(batchSize):
index = (i + indexStart) % totalNumber
name = fileNameList[index]
img_data, img_label = get_data_and_label(name)
batch_data[i, : ] = img_data
batch_label[i, : ] = img_label
return batch_data, batch_label
#构建卷积神经网络并训练
def train_data_with_CNN():
#初始化权值
def weight_variable(shape, name='weight'):
init = tf.truncated_normal(shape, stddev=0.1)
var = tf.Variable(initial_value=init, name=name)
return var
#初始化偏置
def bias_variable(shape, name='bias'):
init = tf.constant(0.1, shape=shape)
var = tf.Variable(init, name=name)
return var
#卷积
def conv2d(x, W, name='conv2d'):
return tf.nn.conv2d(x, W, strides=[1,1,1,1], padding='SAME', name=name)
#池化
def max_pool_2X2(x, name='maxpool'):
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME', name=name)
#输入层
#请注意 X 的 name,在测试model时会用到它
X = tf.placeholder(tf.float32, [None, CAPTCHA_IMAGE_WIDHT * CAPTCHA_IMAGE_HEIGHT], name='data-input')
Y = tf.placeholder(tf.float32, [None, CAPTCHA_LEN * CHAR_SET_LEN], name='label-input')
x_input = tf.reshape(X, [-1, CAPTCHA_IMAGE_HEIGHT, CAPTCHA_IMAGE_WIDHT, 1], name='x-input')
#dropout,防止过拟合
#请注意 keep_prob 的 name,在测试model时会用到它
keep_prob = tf.placeholder(tf.float32, name='keep-prob')
#第一层卷积
W_conv1 = weight_variable([5,5,1,32], 'W_conv1')
B_conv1 = bias_variable([32], 'B_conv1')
conv1 = tf.nn.relu(conv2d(x_input, W_conv1, 'conv1') + B_conv1)
conv1 = max_pool_2X2(conv1, 'conv1-pool')
conv1 = tf.nn.dropout(conv1, keep_prob)
#第二层卷积
W_conv2 = weight_variable([5,5,32,64], 'W_conv2')
B_conv2 = bias_variable([64], 'B_conv2')
conv2 = tf.nn.relu(conv2d(conv1, W_conv2,'conv2') + B_conv2)
conv2 = max_pool_2X2(conv2, 'conv2-pool')
conv2 = tf.nn.dropout(conv2, keep_prob)
#第三层卷积
W_conv3 = weight_variable([5,5,64,64], 'W_conv3')
B_conv3 = bias_variable([64], 'B_conv3')
conv3 = tf.nn.relu(conv2d(conv2, W_conv3, 'conv3') + B_conv3)
conv3 = max_pool_2X2(conv3, 'conv3-pool')
conv3 = tf.nn.dropout(conv3, keep_prob)
#全链接层
#每次池化后,图片的宽度和高度均缩小为原来的一半,进过上面的三次池化,宽度和高度均缩小8倍
W_fc1 = weight_variable([20*8*64, 1024], 'W_fc1')
B_fc1 = bias_variable([1024], 'B_fc1')
fc1 = tf.reshape(conv3, [-1, 20*8*64])
fc1 = tf.nn.relu(tf.add(tf.matmul(fc1, W_fc1), B_fc1))
fc1 = tf.nn.dropout(fc1, keep_prob)
#输出层
W_fc2 = weight_variable([1024, CAPTCHA_LEN * CHAR_SET_LEN], 'W_fc2')
B_fc2 = bias_variable([CAPTCHA_LEN * CHAR_SET_LEN], 'B_fc2')
output = tf.add(tf.matmul(fc1, W_fc2), B_fc2, 'output')
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=Y, logits=output))
optimizer = tf.train.AdamOptimizer(0.001).minimize(loss)
predict = tf.reshape(output, [-1, CAPTCHA_LEN, CHAR_SET_LEN], name='predict')
labels = tf.reshape(Y, [-1, CAPTCHA_LEN, CHAR_SET_LEN], name='labels')
#预测结果
#请注意 predict_max_idx 的 name,在测试model时会用到它
predict_max_idx = tf.argmax(predict, axis=2, name='predict_max_idx')
labels_max_idx = tf.argmax(labels, axis=2, name='labels_max_idx')
predict_correct_vec = tf.equal(predict_max_idx, labels_max_idx)
accuracy = tf.reduce_mean(tf.cast(predict_correct_vec, tf.float32))
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
steps = 0
for epoch in range(6000):
train_data, train_label = get_next_batch(64, 'train', steps)
sess.run(optimizer, feed_dict={X : train_data, Y : train_label, keep_prob:0.75})
if steps % 100 == 0:
test_data, test_label = get_next_batch(100, 'validate', steps)
acc = sess.run(accuracy, feed_dict={X : test_data, Y : test_label, keep_prob:1.0})
print("steps=%d, accuracy=%f" % (steps, acc))
if acc > 0.99:
saver.save(sess, MODEL_SAVE_PATH+"crack_captcha.model", global_step=steps)
break
steps += 1
if __name__ == '__main__':
image_filename_list, total = get_image_file_name(CAPTCHA_IMAGE_PATH)
random.seed(time.time())
#打乱顺序
random.shuffle(image_filename_list)
trainImageNumber = int(total * TRAIN_IMAGE_PERCENT)
#分成测试集
TRAINING_IMAGE_NAME = image_filename_list[ : trainImageNumber]
#和验证集
VALIDATION_IMAGE_NAME = image_filename_list[trainImageNumber : ]
train_data_with_CNN()
print('Training finished')
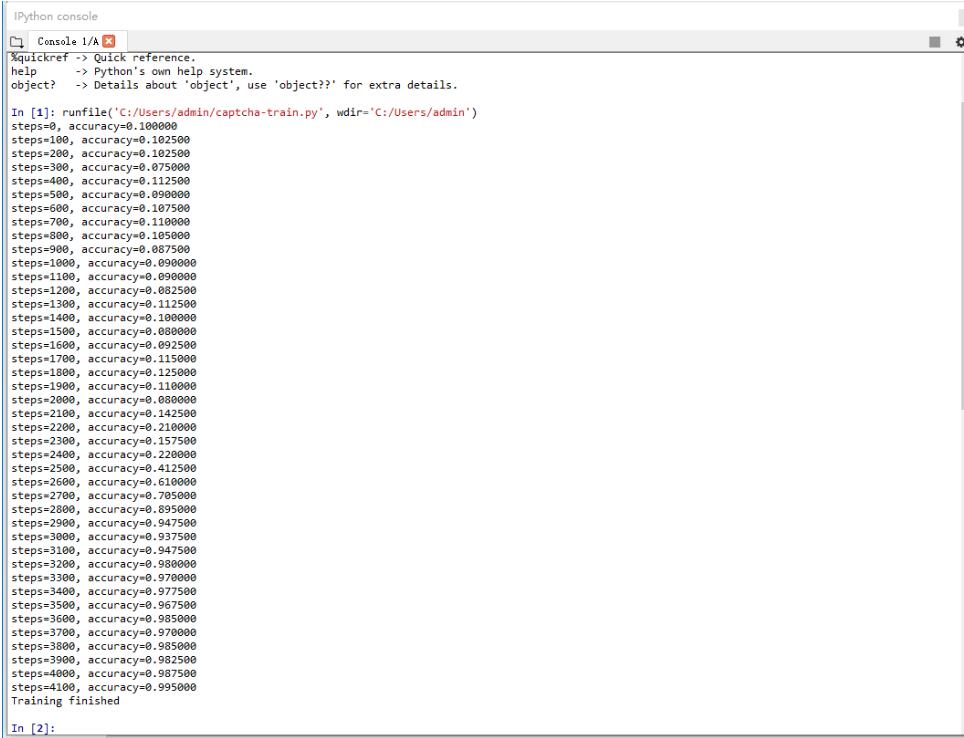
运行上面的代码,开始训练,训练要花些时间,如果没有GPU的话,会慢些,
训练完后,输出如下结果,经过4100次的迭代,训练出来的分类器模型在验证集上识别的准确率为99.5%
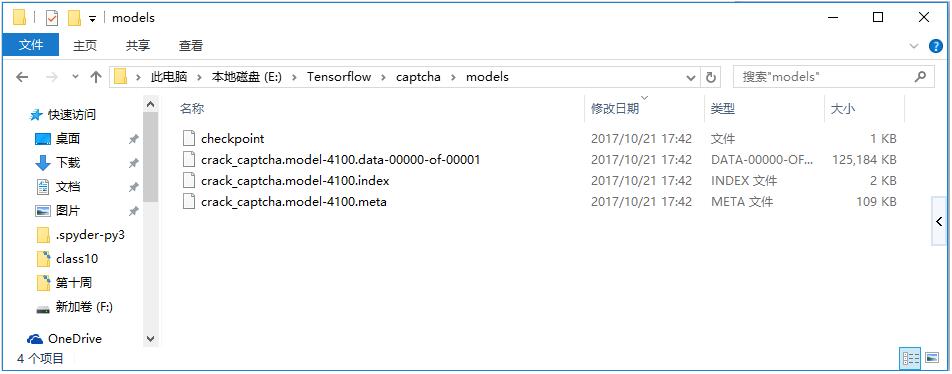
生成的模型文件如下,在模型测试时将用到这些文件
3. 测试模型
编写代码,对训练出来的模型进行测试
import tensorflow as tf
import numpy as np
from PIL import Image
import os
import matplotlib.pyplot as plt
CAPTCHA_LEN = 4
MODEL_SAVE_PATH = 'E:/Tensorflow/captcha/models/'
TEST_IMAGE_PATH = 'E:/Tensorflow/captcha/test/'
def get_image_data_and_name(fileName, filePath=TEST_IMAGE_PATH):
pathName = os.path.join(filePath, fileName)
img = Image.open(pathName)
#转为灰度图
img = img.convert("L")
image_array = np.array(img)
image_data = image_array.flatten()/255
image_name = fileName[0:CAPTCHA_LEN]
return image_data, image_name
def digitalStr2Array(digitalStr):
digitalList = []
for c in digitalStr:
digitalList.append(ord(c) - ord('0'))
return np.array(digitalList)
def model_test():
nameList = []
for pathName in os.listdir(TEST_IMAGE_PATH):
nameList.append(pathName.split('/')[-1])
totalNumber = len(nameList)
#加载graph
saver = tf.train.import_meta_graph(MODEL_SAVE_PATH+"crack_captcha.model-4100.meta")
graph = tf.get_default_graph()
#从graph取得 tensor,他们的name是在构建graph时定义的(查看上面第2步里的代码)
input_holder = graph.get_tensor_by_name("data-input:0")
keep_prob_holder = graph.get_tensor_by_name("keep-prob:0")
predict_max_idx = graph.get_tensor_by_name("predict_max_idx:0")
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint(MODEL_SAVE_PATH))
count = 0
for fileName in nameList:
img_data, img_name = get_image_data_and_name(fileName, TEST_IMAGE_PATH)
predict = sess.run(predict_max_idx, feed_dict={input_holder:[img_data], keep_prob_holder : 1.0})
filePathName = TEST_IMAGE_PATH + fileName
print(filePathName)
img = Image.open(filePathName)
plt.imshow(img)
plt.axis('off')
plt.show()
predictValue = np.squeeze(predict)
rightValue = digitalStr2Array(img_name)
if np.array_equal(predictValue, rightValue):
result = '正确'
count += 1
else:
result = '错误'
print('实际值:{}, 预测值:{},测试结果:{}'.format(rightValue, predictValue, result))
print('\n')
print('正确率:%.2f%%(%d/%d)' % (count*100/totalNumber, count, totalNumber))
if __name__ == '__main__':
model_test()
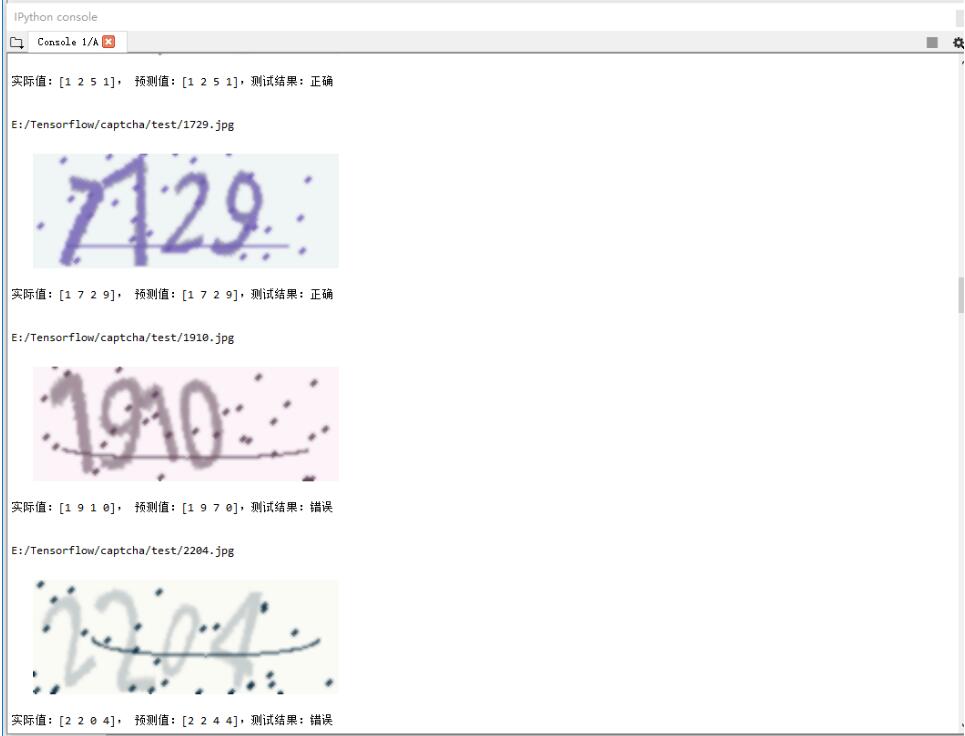
对模型的测试结果如下,在测试集上识别的准确率为 94%

下面是两个识别错误的验证码
以上这篇利用Tensorflow构建和训练自己的CNN来做简单的验证码识别方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python通过TensorFLow进行线性模型训练原理与实现方法详解
本文实例讲述了Python通过TensorFLow进行线性模型训练原理与实现方法.分享给大家供大家参考,具体如下: 1.相关概念 例如要从一个线性分布的途中抽象出其y=kx+b的分布规律 特征是输入变量,即简单线性回归中的 x 变量.简单的机器学习项目可能会使用单个特征,而比较复杂的机器学习项目可能会使用数百万个特征. 标签是我们要预测的事物,即简单线性回归中的 y 变量. 样本是指具体的数据实例.有标签样本是指具有{特征,标签}的数据,用于训练模型,总结规律.无标签样本只具有特征的数据x,通过
-
Tensorflow实现在训练好的模型上进行测试
Tensorflow可以使用训练好的模型对新的数据进行测试,有两种方法:第一种方法是调用模型和训练在同一个py文件中,中情况比较简单:第二种是训练过程和调用模型过程分别在两个py文件中.本文将讲解第二种方法. 模型的保存 tensorflow提供可保存训练模型的接口,使用起来也不是很难,直接上代码讲解: #网络结构 w1 = tf.Variable(tf.truncated_normal([in_units, h1_units], stddev=0.1)) b1 = tf.Variable(tf
-
利用TensorFlow训练简单的二分类神经网络模型的方法
利用TensorFlow实现<神经网络与机器学习>一书中4.7模式分类练习 具体问题是将如下图所示双月牙数据集分类. 使用到的工具: python3.5 tensorflow1.2.1 numpy matplotlib 1.产生双月环数据集 def produceData(r,w,d,num): r1 = r-w/2 r2 = r+w/2 #上半圆 theta1 = np.random.uniform(0, np.pi ,num) X_Col1 = np.random.unifo
-
详解tensorflow训练自己的数据集实现CNN图像分类
利用卷积神经网络训练图像数据分为以下几个步骤 1.读取图片文件 2.产生用于训练的批次 3.定义训练的模型(包括初始化参数,卷积.池化层等参数.网络) 4.训练 1 读取图片文件 def get_files(filename): class_train = [] label_train = [] for train_class in os.listdir(filename): for pic in os.listdir(filename+train_class): class_train.app
-
从训练好的tensorflow模型中打印训练变量实例
从tensorflow 训练后保存的模型中打印训变量:使用tf.train.NewCheckpointReader() import tensorflow as tf reader = tf.train.NewCheckpointReader('path/alexnet/model-330000') dic = reader.get_variable_to_shape_map() print dic 打印变量 w = reader.get_tensor("fc1/W") print t
-
利用Tensorflow构建和训练自己的CNN来做简单的验证码识别方式
Tensorflow是目前最流行的深度学习框架,我们可以用它来搭建自己的卷积神经网络并训练自己的分类器,本文介绍怎样使用Tensorflow构建自己的CNN,怎样训练用于简单的验证码识别的分类器.本文假设你已经安装好了Tensorflow,了解过CNN的一些知识. 下面将分步介绍怎样获得训练数据,怎样使用tensorflow构建卷积神经网络,怎样训练,以及怎样测试训练出来的分类器 1. 准备训练样本 使用Python的库captcha来生成我们需要的训练样本,代码如下: import sys i
-
python人工智能tensorflow构建卷积神经网络CNN
目录 简介 隐含层介绍 1.卷积层 2.池化层 3.全连接层 具体实现代码 卷积层.池化层与全连接层实现代码 全部代码 学习神经网络已经有一段时间,从普通的BP神经网络到LSTM长短期记忆网络都有一定的了解,但是从未系统的把整个神经网络的结构记录下来,我相信这些小记录可以帮助我更加深刻的理解神经网络. 简介 卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),
-
tensorflow构建BP神经网络的方法
之前的一篇博客专门介绍了神经网络的搭建,是在python环境下基于numpy搭建的,之前的numpy版两层神经网络,不能支持增加神经网络的层数.最近看了一个介绍tensorflow的视频,介绍了关于tensorflow的构建神经网络的方法,特此记录. tensorflow的构建封装的更加完善,可以任意加入中间层,只要注意好维度即可,不过numpy版的神经网络代码经过适当地改动也可以做到这一点,这里最重要的思想就是层的模型的分离. import tensorflow as tf import nu
-
TensorFlow深度学习之卷积神经网络CNN
一.卷积神经网络的概述 卷积神经网络(ConvolutionalNeural Network,CNN)最初是为解决图像识别等问题设计的,CNN现在的应用已经不限于图像和视频,也可用于时间序列信号,比如音频信号和文本数据等.CNN作为一个深度学习架构被提出的最初诉求是降低对图像数据预处理的要求,避免复杂的特征工程.在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一层卷积(滤波器)都会提取数据中最有效的特征,这种方法可以提取到图像中最基础的特征,而后再进行组合和抽象形成更高阶的特征,因此
-
TensorFlow实现随机训练和批量训练的方法
TensorFlow更新模型变量.它能一次操作一个数据点,也可以一次操作大量数据.一个训练例子上的操作可能导致比较"古怪"的学习过程,但使用大批量的训练会造成计算成本昂贵.到底选用哪种训练类型对机器学习算法的收敛非常关键. 为了TensorFlow计算变量梯度来让反向传播工作,我们必须度量一个或者多个样本的损失. 随机训练会一次随机抽样训练数据和目标数据对完成训练.另外一个可选项是,一次大批量训练取平均损失来进行梯度计算,批量训练大小可以一次上扩到整个数据集.这里将显示如何扩展前面的回
-
tensorflow入门之训练简单的神经网络方法
这几天开始学tensorflow,先来做一下学习记录 一.神经网络解决问题步骤: 1.提取问题中实体的特征向量作为神经网络的输入.也就是说要对数据集进行特征工程,然后知道每个样本的特征维度,以此来定义输入神经元的个数. 2.定义神经网络的结构,并定义如何从神经网络的输入得到输出.也就是说定义输入层,隐藏层以及输出层. 3.通过训练数据来调整神经网络中的参数取值,这是训练神经网络的过程.一般来说要定义模型的损失函数,以及参数优化的方法,如交叉熵损失函数和梯度下降法调优等. 4.利用训练好的模型预测
-
利用Tensorflow的队列多线程读取数据方式
在tensorflow中,有三种方式输入数据 1. 利用feed_dict送入numpy数组 2. 利用队列从文件中直接读取数据 3. 预加载数据 其中第一种方式很常用,在tensorflow的MNIST训练源码中可以看到,通过feed_dict={},可以将任意数据送入tensor中. 第二种方式相比于第一种,速度更快,可以利用多线程的优势把数据送入队列,再以batch的方式出队,并且在这个过程中可以很方便地对图像进行随机裁剪.翻转.改变对比度等预处理,同时可以选择是否对数据随机打乱,可以说是
-
tensorflow保持每次训练结果一致的简单实现
在用tensorflow构建神经网络的时候,有很多随机的因素,比如参数的随机初始化: 正态分布随机变量tf.random_normal([m,n]),均匀分布的随机变量tf.random_uniform([m,n]),还有在从tfrecord读取数据时,也会随机打乱数据. 那么由于这些随机的操作,即使是在输入数据完全一样的情况下,每次训练的结果也不一样,那么如果想要使得每次训练的结果一致,应该怎么做呢? 可以在最开始时,固定随机数种子,如下 tf.set_random_seed(1) 以上这篇t