python 回溯法模板详解
什么是回溯法
回溯法(探索与回溯法)是一种选优搜索法,又称为试探法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。
无重复元素全排列问题
给定一个所有元素都不同的list,要求返回list元素的全排列。
设n = len(list),那么这个问题可以考虑为n叉树,对这个树进行dfs,这个问题里的回溯点就是深度(也就是templist的长度)为n时,回溯的条件就是当前元素已经出现在templist中了。
回溯法与递归:
回溯法是一种思想,递归是一种形式
class Solution(object):
#rtlist用来存储所有的返回所有排列,templist用来生成每个排列
def backtrack(self,rtlist,templist,nums):
if(len(templist) == len(nums)):
rtlist.append(templist[:])
else:
for i in nums:
if(i in templist): #如果在当前排列中已经有i了,就continue,相当于分支限界,即不对当前节点子树搜寻了
continue
templist.append(i)
self.backtrack(rtlist,templist,nums)
templist.pop() #把结尾的元素用nums中的下一个值替换掉,遍历下一颗子树
def permute(self,nums):
rtlist = []
templist = []
self.backtrack(rtlist,templist,nums)
return rtlist
nums=[1,2,3]时的树结构:
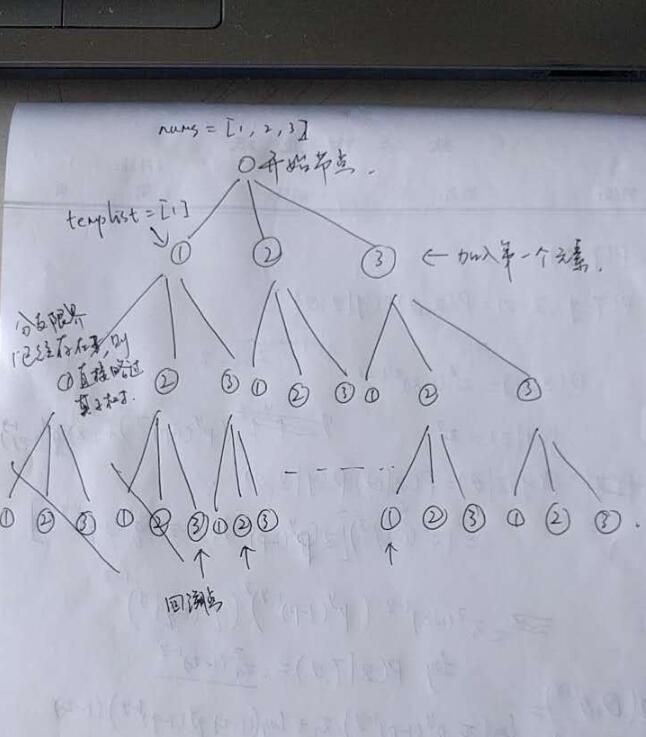
关键的就是确定好分支限界以及回溯点。
这里面有一个问题就是每次递归时把新加入的元素从nums删除在递归可不可以,实际上这样的时间复杂度并不会减少太多,因为对list进行操作还需要一定的时间,而原解法中因为有分支限界所以时间复杂度也不会太差。
有重复元素全排列
这个问题和上面的区别主要在于分支限界的差别,不能在使用出现重复元素作为回溯条件了,否则所有的都不满足。
这里我们应该使用计数器记录nums中每个元素出现的次数,如果当前元素超过次数则返回,但是这里还有一个问题就是可能会出现同样的排列多次,这里的解决办法就是同一层不许出现重复元素,这里有两种解决办法,一种是直接传入distinct的数组,还有一种是使用一个集合记录当前层已使用的元素。
第一种方法:
from collections import Counter
class Solution(object):
def backtrack(self, rtlist, tmplist, counter, nums, length):
if len(tmplist) == length:#回溯点
rtlist.append(tmplist[:])
else:
for i in nums:#横向遍历
if counter[i] == 0:#分支限界
continue
counter[i] -= 1
tmplist.append(i)
self.backtrack(rtlist, tmplist, counter, nums, length)#纵向遍历
counter[i] += 1
tmplist.pop()
def permuteUnique(self, nums):
rtlist, tmplist, counter = [], [], Counter(nums)
length = len(nums)
self.backtrack(rtlist, tmplist, counter, list(set(nums)), length)
return rtlist
第二种
from collections import Counter
class Solution(object):
def backtrack(self, rtlist, tmplist, level, counter, nums):
if len(tmplist) == len(nums):
rtlist.append(tmplist[:])
else:
for i in nums:
if i in level or counter[i] == 0:
continue
counter[i] -= 1
tmplist.append(i)
level.add(i)
self.backtrack(rtlist, tmplist, set(), counter, nums)
counter[i] += 1
tmplist.pop()
def permuteUnique(self, nums):
if not nums:
return []
rtlist, tmplist, level, counter = [], [], set(), Counter(nums)
self.backtrack(rtlist, tmplist, level, counter, nums)
return rtlist
在递归时不能用“=”修改父函数的变量,因为“=”只能改变变量的指向,要修改父函数的变量要直接在内存中修改,例如放入容器中可以直接找到变量内存地址。通常使用container.method()。
例如在上面的程序中如果我们想要在回溯点把counter复原不能使用counter = Counter(nums),而是应该逐个修改counter[key]
总结
回溯法其实就是把原问题考虑成一棵树,我们遍历这棵树在不可能的地方返回,不在遍历这个节点的子树,在满足要求时返回。
所以在回溯法中,关键的就是找出合理的分支限界(重要),和返回条件。
更多请参考
多叉树的遍历方法:
def travel(root):
遍历root
for subtree_root in 当前层所有节点:
travel(subtree_root)
在for中对一层的所有节点都执行了travel,又因为对所有节点的所有子树都执行了travel,所以可以完成遍历。
以上这篇python 回溯法模板详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python循环实现n的全排列功能
描述: 输入一个大于0的整数n,输出1到n的全排列: 例如: n=3,输出[[3, 2, 1], [2, 3, 1], [2, 1, 3], [3, 1, 2], [1, 3, 2], [1, 2, 3]] n=4,输出[[4, 3, 2, 1], [3, 4, 2, 1], [3, 2, 4, 1], [3, 2, 1, 4], [4, 2, 3, 1], [2, 4, 3, 1], [2, 3, 4, 1], [2, 3, 1, 4], [4, 2, 1, 3], [2, 4, 1, 3],
-
基于Python数据结构之递归与回溯搜索
目录 1. 递归函数与回溯深搜的基础知识 2. 求子集 (LeetCode 78) 3. 求子集2 (LeetCode 90) 4. 组合数之和(LeetCode 39,40) 5. 生成括号(LeetCode 22) 6. N皇后(LeetCode 51,52) 7. 火柴棍摆正方形(LeetCode 473) 1. 递归函数与回溯深搜的基础知识 递归是指在函数内部调用自身本身的方法.能采用递归描述的算法通常有这样的特征:为求解规模为N的问题,设法将它分解成规模较小的问题,然后从这些小问题的解
-
python实现全排列代码(回溯、深度优先搜索)
从n个不同元素中任取m(m≤n)个元素,按照一定的顺序排列起来,叫做从n个不同元素中取出m个元素的一个排列.当m=n时所有的排列情况叫全排列. 公式:全排列数f(n)=n!(定义0!=1) 1 递归实现全排列(回溯思想) 1.1 思想 举个例子,比如你要对a,b,c三个字符进行全排列,那么它的全排列有abc,acb,bac,bca,cba,cab这六种可能就是当指针指向第一个元素a时,它可以是其本身a(即和自己进行交换),还可以和b,c进行交换,故有3种可能,当第一个元素a确定以后,指针移向第二
-
Python实现全排列的打印
本文为大家分享了Python实现全排列的打印的代码,供大家参考,具体如下 问题:输入一个数字:3,打印它的全排列组合:123 132 213 231 312 321,并进行统计个数. 下面是Python的实现代码: #!/usr/bin/env python # -*- coding: <encoding name> -*- ''' 全排列的demo input : 3 output:123 132 213 231 312 321 ''' total = 0 def permutationCo
-
如何通过python实现全排列
这篇文章主要介绍了如何通过python实现全排列,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 itertools模块现成的全排列: for i in itertools.permutations('abcd',4): print ''.join(i) 相关全排列算法: def perm(l): if(len(l)<=1): return [l] r=[] for i in range(len(l)): s=l[:i]+l[i+1:] p=pe
-
Python字符串的全排列算法实例详解
本文实例讲述了Python字符串的全排列算法.分享给大家供大家参考,具体如下: 题目描述 输入一个字符串,按字典序打印出该字符串中字符的所有排列.例如输入字符串abc,则打印出由字符a,b,c所能排列出来的所有字符串abc,acb,bac,bca,cab和cba. 输入描述 输入一个字符串,长度不超过9(可能有字符重复),字符只包括大小写字母. 注意有可能重复,因此需要判断 注意list的append方法和list的+方法的区别 append方法在list后面添加元素 +方法在list后面添加l
-
python 使用递归回溯完美解决八皇后的问题
八皇后问题描述:在一个8✖️8的棋盘上,任意摆放8个棋子,要求任意两个棋子不能在同一行,同一列,同一斜线上,问有多少种解法. 规则分析: 任意两个棋子不能在同一行比较好办,设置一个队列,队列里的每个元素代表一行,就能达到要求 任意两个棋子不能在同一列也比较好处理,设置的队列里每个元素的数值代表着每行棋子的列号,比如(0,7,3),表示第一行的棋子放在第一列,第二行的棋子放在第8列,第3行的棋子放在第4列(从0开始计算列号) 任意两个棋子不能在同一斜线上,可以把整个棋盘当作是一个XOY平面,原点在
-
python 回溯法模板详解
什么是回溯法 回溯法(探索与回溯法)是一种选优搜索法,又称为试探法,按选优条件向前搜索,以达到目标.但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为"回溯点". 无重复元素全排列问题 给定一个所有元素都不同的list,要求返回list元素的全排列. 设n = len(list),那么这个问题可以考虑为n叉树,对这个树进行dfs,这个问题里的回溯点就是深度(也就是templist的长度)为n时,回
-
熵值法原理及Python实现的示例详解
目录 1.简单理解 信息熵 2.编制指标 (学术情景应用) 3.python实现 3.1 数据准备 3.2 数据预处理 3.3 熵值.权重计算 3.4 编制综合评价指标 熵值法也称熵权法,是学术研究,及实际应用中的一种常用且有效的编制指标的方法. 1.简单理解 信息熵 机器学习中的决策树算法是对信息熵的一种典型的应用. 在信息论中,使用 熵 (Entropy)来描述随机变量分布的不确定性. 假设对随机变量X,其可能的取值有x1,x2,...,xn .即有n种可能发生的结果.其对应发生的概率依次为
-
Python之str操作方法(详解)
1. str.format():使用"{}"占位符格式化字符串(占位符中的索引号形式和键值对形式可以混合使用). >>> string = 'python{}, django{}, tornado{}'.format(2.7, 'web', 'tornado') # 有多少个{}占位符就有多少个值与其对应,按照顺序"填"进字符串中 >>> string 'python2.7, djangoweb, tornadotornado'
-

Python实现调度算法代码详解
调度算法 操作系统管理了系统的有限资源,当有多个进程(或多个进程发出的请求)要使用这些资源时,因为资源的有限性,必须按照一定的原则选择进程(请求)来占用资源.这就是调度.目的是控制资源使用者的数量,选取资源使用者许可占用资源或占用资源. 在操作系统中调度是指一种资源分配,因而调度算法是指:根据系统的资源分配策略所规定的资源分配算法.对于不同的的系统和系统目标,通常采用不同的调度算法,例如,在批处理系统中,为了照顾为数众多的段作业,应采用短作业优先的调度算法:又如在分时系统中,为了保证系统具有合理
-
Python opencv操作深入详解
直接读取图片 def display_img(file="p.jpeg"): img = cv.imread(file) print (img.shape) cv.imshow('image',img) cv.waitKey(0) cv.destroyAllWindows() 读取灰度图片 def display_gray_img(file="p.jpeg"): img = cv.imread(file,cv.IMREAD_GRAYSCALE) print (img
-
C++11新特性之变长参数模板详解
目录 C++11 变长参数模板 变长函数参数包 如何解参数包 sizeof()获得函数参数个数 递归模板函数 变参模板展开 结论 C++11 变长参数模板 在C++11之前,无论是类模板 还是函数模板,都只能按其指定的样子,接受一组固定数量的模板参数: 这已经大大提升了代码的复用! 在C++11之后,加入了新的表示方 法,允许任意个数.任意类别的模板参数,同时也不需要在定义时将参数的个数固定.更加像"黑魔法"了. template<typename... Ts> class
-
通过Python实现控制手机详解
几天前我在考虑使用 python 从 whatsapp 发送消息.和你们一样,我开始潜伏在互联网上寻找一些解决方案并找到了关于twilio. 一开始,是一个不错的解决方案,但它不是免费的,我必须购买一个 twilio 电话号码.此外,我无法在互联网上找到任何可用的 whatsapp API.所以我放弃了使用 twilio 和任何其他 whatsapp API 的想法.在想了很多之,打开 android studio,我连接了我的手机,然后开始了这个过程.当应用程序构建时,我想到了使用手机本身自动
-
Python实现KPM算法详解
目录 知识点说明: 一.要获取KPM算法的next[]数组 二.KMP函数 知识点说明: 先说前缀,和后缀吧 比如有一个串:abab 则在下标为3处的(前缀和后缀都要比下标出的长度小1,此处下标为3出的长度是4) 前缀为:a,ab,aba 后缀为:b,ba,bab 一.要获取KPM算法的next[]数组 简单说一下原理吧,首先k,用来存放前缀的下标,首先初始化j=0(j用来表示模式串的下标,一直去模式串的每一位与前面的进行比较,如果相等,则记录下当前位置与前面的哪个位置相同,我们这里主要是要记录
-
Python 变量类型实例详解
目录 1.变量赋值 2.多个变量赋值 3.标准数据类型 4.Python 数字 5.Python字符串 6.Python列表 7.ython 元组 8..Python 字典 9.Python数据类型转换 前言: 变量存储在内存中的值,这就意味着在创建变量时会在内存中开辟一个空间. 基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中. 因此,变量可以指定不同的数据类型,这些变量可以存储整数,小数或字符. 1.变量赋值 Python 中的变量赋值不需要类型声明. 每个变量在内
-
使用Python进行数独求解详解(二)
目录 1.引言 2.前文回顾 3.减少非比要的迭代次数 3.1生成候选值字典 3.2生成候选值列表 3.3函数调用 4.总结 1. 引言 本文是数独游戏问题求解的第二篇,在前文中我们使用回溯算法实现了最简单版本的数独游戏求解方案.本文主要在前文解决方案的基础上,来思考如何通过改进来提升数独问题求解算法的性能. 闲话少说,我们直接开始吧. :) 2. 前文回顾 我们首先来回顾下前文的回溯算法,如下图示: 在前文中,我们引入了回溯算法来对数独问题求解,通过迭代每个子单元格cell的所有可能取值来暴力