浅谈内存耗尽后Redis会发生什么
前言
作为一台服务器来说,内存并不是无限的,所以总会存在内存耗尽的情况,那么当 Redis 服务器的内存耗尽后,如果继续执行请求命令,Redis 会如何处理呢?
内存回收
使用Redis 服务时,很多情况下某些键值对只会在特定的时间内有效,为了防止这种类型的数据一直占有内存,我们可以给键值对设置有效期。Redis 中可以通过 4 个独立的命令来给一个键设置过期时间:
expire key ttl:将key值的过期时间设置为ttl秒。pexpire key ttl:将key值的过期时间设置为ttl毫秒。expireat key timestamp:将key值的过期时间设置为指定的timestamp秒数。pexpireat key timestamp:将key值的过期时间设置为指定的timestamp毫秒数。
PS:不管使用哪一个命令,最终 Redis 底层都是使用 pexpireat 命令来实现的。另外,set 等命令也可以设置 key 的同时加上过期时间,这样可以保证设值和设过期时间的原子性。
设置了有效期后,可以通过 ttl 和 pttl 两个命令来查询剩余过期时间(如果未设置过期时间则下面两个命令返回 -1,如果设置了一个非法的过期时间,则都返回 -2):
ttl key返回key剩余过期秒数。pttl key返回key剩余过期的毫秒数。
过期策略
如果将一个过期的键删除,我们一般都会有三种策略:
- 定时删除:为每个键设置一个定时器,一旦过期时间到了,则将键删除。这种策略对内存很友好,但是对
CPU不友好,因为每个定时器都会占用一定的CPU资源。 - 惰性删除:不管键有没有过期都不主动删除,等到每次去获取键时再判断是否过期,如果过期就删除该键,否则返回键对应的值。这种策略对内存不够友好,可能会浪费很多内存。
- 定期扫描:系统每隔一段时间就定期扫描一次,发现过期的键就进行删除。这种策略相对来说是上面两种策略的折中方案,需要注意的是这个定期的频率要结合实际情况掌控好,使用这种方案有一个缺陷就是可能会出现已经过期的键也被返回。
在 Redis 当中,其选择的是策略 2 和策略 3 的综合使用。不过 Redis 的定期扫描只会扫描设置了过期时间的键,因为设置了过期时间的键 Redis 会单独存储,所以不会出现扫描所有键的情况:
typedef struct redisDb {
dict *dict; //所有的键值对
dict *expires; //设置了过期时间的键值对
dict *blocking_keys; //被阻塞的key,如客户端执行BLPOP等阻塞指令时
dict *watched_keys; //WATCHED keys
int id; //Database ID
//... 省略了其他属性
} redisDb;
8 种淘汰策略
假如 Redis 当中所有的键都没有过期,而且此时内存满了,那么客户端继续执行 set 等命令时 Redis 会怎么处理呢?Redis 当中提供了不同的淘汰策略来处理这种场景。
首先 Redis 提供了一个参数 maxmemory 来配置 Redis 最大使用内存:
maxmemory <bytes>
或者也可以通过命令 config set maxmemory 1GB 来动态修改。
如果没有设置该参数,那么在 32 位的操作系统中 Redis 最多使用 3GB 内存,而在 64 位的操作系统中则不作限制。
Redis 中提供了 8 种淘汰策略,可以通过参数 maxmemory-policy 进行配置:
| 淘汰策略 | 说明 |
|---|---|
| volatile-lru | 根据 LRU 算法删除设置了过期时间的键,直到腾出可用空间。如果没有可删除的键对象,且内存还是不够用时,则报错 |
| allkeys-lru | 根据 LRU 算法删除所有的键,直到腾出可用空间。如果没有可删除的键对象,且内存还是不够用时,则报错 |
| volatile-lfu | 根据 LFU 算法删除设置了过期时间的键,直到腾出可用空间。如果没有可删除的键对象,且内存还是不够用时,则报错 |
| allkeys-lfu | 根据 LFU 算法删除所有的键,直到腾出可用空间。如果没有可删除的键对象,且内存还是不够用时,则报错 |
| volatile-random | 随机删除设置了过期时间的键,直到腾出可用空间。如果没有可删除的键对象,且内存还是不够用时,则报错 |
| allkeys-random | 随机删除所有键,直到腾出可用空间。如果没有可删除的键对象,且内存还是不够用时,则报错 |
| volatile-ttl | 根据键值对象的 ttl 属性, 删除最近将要过期数据。 如果没有,则直接报错 |
| noeviction | 默认策略,不作任何处理,直接报错 |
PS:淘汰策略也可以直接使用命令 config set maxmemory-policy <策略> 来进行动态配置。
LRU 算法
LRU 全称为:Least Recently Used。即:最近最长时间未被使用。这个主要针对的是使用时间。
Redis 改进后的 LRU 算法
在 Redis 当中,并没有采用传统的 LRU 算法,因为传统的 LRU 算法存在 2 个问题:
- 需要额外的空间进行存储。
- 可能存在某些
key值使用很频繁,但是最近没被使用,从而被LRU算法删除。
为了避免以上 2 个问题,Redis 当中对传统的 LRU 算法进行了改造,通过抽样的方式进行删除。
配置文件中提供了一个属性 maxmemory_samples 5,默认值就是 5,表示随机抽取 5 个 key 值,然后对这 5 个 key 值按照 LRU 算法进行删除,所以很明显,key 值越大,删除的准确度越高。
对抽样 LRU 算法和传统的 LRU 算法,Redis 官网当中有一个对比图:
- 浅灰色带是被删除的对象。
- 灰色带是未被删除的对象。
- 绿色是添加的对象。

左上角第一幅图代表的是传统 LRU 算法,可以看到,当抽样数达到 10 个(右上角),已经和传统的 LRU 算法非常接近了。
Redis 如何管理热度数据
前面我们讲述字符串对象时,提到了 redisObject 对象中存在一个 lru 属性:
typedef struct redisObject {
unsigned type:4;//对象类型(4位=0.5字节)
unsigned encoding:4;//编码(4位=0.5字节)
unsigned lru:LRU_BITS;//记录对象最后一次被应用程序访问的时间(24位=3字节)
int refcount;//引用计数。等于0时表示可以被垃圾回收(32位=4字节)
void *ptr;//指向底层实际的数据存储结构,如:SDS等(8字节)
} robj;
lru 属性是创建对象的时候写入,对象被访问到时也会进行更新。正常人的思路就是最后决定要不要删除某一个键肯定是用当前时间戳减去 lru,差值最大的就优先被删除。但是 Redis 里面并不是这么做的,Redis 中维护了一个全局属性 lru_clock,这个属性是通过一个全局函数 serverCron 每隔 100 毫秒执行一次来更新的,记录的是当前 unix 时间戳。
最后决定删除的数据是通过 lru_clock 减去对象的 lru 属性而得出的。那么为什么 Redis 要这么做呢?直接取全局时间不是更准确吗?
这是因为这么做可以避免每次更新对象的 lru 属性的时候可以直接取全局属性,而不需要去调用系统函数来获取系统时间,从而提升效率(Redis 当中有很多这种细节考虑来提升性能,可以说是对性能尽可能的优化到极致)。
不过这里还有一个问题,我们看到,redisObject 对象中的 lru 属性只有 24 位,24 位只能存储 194 天的时间戳大小,一旦超过 194 天之后就会重新从 0 开始计算,所以这时候就可能会出现 redisObject 对象中的 lru 属性大于全局的 lru_clock 属性的情况。
正因为如此,所以计算的时候也需要分为 2 种情况:
- 当全局
lruclock>lru,则使用lruclock-lru得到空闲时间。 - 当全局
lruclock<lru,则使用lruclock_max(即194天) -lru+lruclock得到空闲时间。
需要注意的是,这种计算方式并不能保证抽样的数据中一定能删除空闲时间最长的。这是因为首先超过 194 天还不被使用的情况很少,再次只有 lruclock 第 2 轮继续超过 lru 属性时,计算才会出问题。
比如对象 A 记录的 lru 是 1 天,而 lruclock 第二轮都到 10 天了,这时候就会导致计算结果只有 10-1=9 天,实际上应该是 194+10-1=203 天。但是这种情况可以说又是更少发生,所以说这种处理方式是可能存在删除不准确的情况,但是本身这种算法就是一种近似的算法,所以并不会有太大影响。
LFU 算法
LFU 全称为:Least Frequently Used。即:最近最少频率使用,这个主要针对的是使用频率。这个属性也是记录在redisObject 中的 lru 属性内。
当我们采用 LFU 回收策略时,lru 属性的高 16 位用来记录访问时间(last decrement time:ldt,单位为分钟),低 8 位用来记录访问频率(logistic counter:logc),简称 counter。
访问频次递增
LFU 计数器每个键只有 8 位,它能表示的最大值是 255,所以 Redis 使用的是一种基于概率的对数器来实现 counter 的递增。r
给定一个旧的访问频次,当一个键被访问时,counter 按以下方式递增:
- 提取
0和1之间的随机数R。 counter- 初始值(默认为5),得到一个基础差值,如果这个差值小于0,则直接取0,为了方便计算,把这个差值记为baseval。- 概率
P计算公式为:1/(baseval * lfu_log_factor + 1)。 - 如果
R < P时,频次进行递增(counter++)。
公式中的 lfu_log_factor 称之为对数因子,默认是 10 ,可以通过参数来进行控制:
lfu_log_factor 10
下图就是对数因子 lfu_log_factor 和频次 counter 增长的关系图:
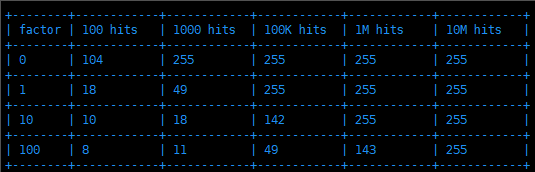
可以看到,当对数因子 lfu_log_factor 为 100 时,大概是 10M(1000万) 次访问才会将访问 counter 增长到 255,而默认的 10 也能支持到 1M(100万) 次访问 counter 才能达到 255 上限,这在大部分场景都是足够满足需求的。
访问频次递减
如果访问频次 counter 只是一直在递增,那么迟早会全部都到 255,也就是说 counter 一直递增不能完全反应一个 key 的热度的,所以当某一个 key 一段时间不被访问之后,counter 也需要对应减少。
counter 的减少速度由参数 lfu-decay-time 进行控制,默认是 1,单位是分钟。默认值 1 表示:N 分钟内没有访问,counter 就要减 N。
lfu-decay-time 1
具体算法如下:
- 获取当前时间戳,转化为分钟后取低
16位(为了方便后续计算,这个值记为now)。 - 取出对象内的
lru属性中的高16位(为了方便后续计算,这个值记为ldt)。 - 当
lru>now时,默认为过了一个周期(16位,最大65535),则取差值65535-ldt+now:当lru<=now时,取差值now-ldt(为了方便后续计算,这个差值记为idle_time)。 - 取出配置文件中的
lfu_decay_time值,然后计算:idle_time / lfu_decay_time(为了方便后续计算,这个值记为num_periods)。 - 最后将
counter减少:counter - num_periods。
看起来这么复杂,其实计算公式就是一句话:取出当前的时间戳和对象中的 lru 属性进行对比,计算出当前多久没有被访问到,比如计算得到的结果是 100 分钟没有被访问,然后再去除配置参数 lfu_decay_time,如果这个配置默认为 1也即是 100/1=100,代表 100 分钟没访问,所以 counter 就减少 100。
总结
本文主要介绍了 Redis 过期键的处理策略,以及当服务器内存不够时 Redis 的 8 种淘汰策略,最后介绍了 Redis 中的两种主要的淘汰算法 LRU 和 LFU。
到此这篇关于浅谈内存耗尽后Redis会发生什么的文章就介绍到这了,更多相关Redis内存耗尽内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

redis 限制内存使用大小的实现
记录一次生产环境问题排查过程: 生产环境部署方式:nginx + uwsgi + flask 问题描述: 发现生产环境中之前正常运行的服务突然不可用了,查看程序日志发现部分接口访问时报I/O写错误,nginx acess.log显示504,error.log显示 upstream time out. 同时 netstat -apn | grep 6379 | wc -l 检查发现redis存在大量连接,进一步检查发现其中大多为 SYN_SENT 包,连接大多归属于uwsgi 进程. 因为程序
-
一次关于Redis内存诡异增长的排查过程实战记录
一.现象 实例名:r-bp1cxxxxxxxxxd04(主从) 问题:一分钟内存上涨了2G,如下图所示: 键值规模:6000万左右 内存一分钟增长2G.png 二.Redis内存分析 1. 内存组成 上图中的内存统计的是Redis的info memory命令中的used_memory属性,例如: redis>infomemory#Memoryused_memory:9195978072used_memory_human:8.56Gused_memory_rss:9358786560used_me
-
Redis教程(十四):内存优化介绍
一.特殊编码: 自从Redis 2.2之后,很多数据类型都可以通过特殊编码的方式来进行存储空间的优化.其中,Hash.List和由Integer组成的Sets都可以通过该方式来优化存储结构,以便占用更少的空间,在有些情况下,可以省去9/10的空间. 这些特殊编码对于Redis的使用而言是完全透明的,事实上,它只是CPU和内存之间的一个交易而言.如果内存使用率方面高一些,那么在操作数据时消耗的CPU自然要多一些,反之亦然.在Redis中提供了一组配置参数用于设置与特殊编码相关的各种阈值,如
-
降低PHP Redis内存占用
1.降低redis内存占用的优点 1.有助于减少创建快照和加载快照所用的时间 2.提升载入AOF文件和重写AOF文件时的效率 3.缩短从服务器进行同步所需的时间 4.无需添加额外的硬件就可以让redis存贮更多的数据 2.短结构 Redis为列表.集合.散列.有序集合提供了一组配置选项,这些选项可以让redis以更节约的方式存储较短的结构. 2.1.ziplist压缩列表(列表.散列.有续集和) 通常情况下使用的存储方式 当列表.散列.有序集合的长度较短或者体积较小的时候,redis将会采用一种
-
内存型数据库Redis持久化小结
因为Redis是内存型数据库,所以为了防止因为系统崩溃等原因导致数据丢失的问题,Redis提供了两种不同的持久化方法来将数据存储在硬盘里面,一种方法是快照(RDB),它可以将存在于某一个时刻的所有数据都写入到硬盘里面,另外一种方法是只追加文件(AOF),它会在执行写命令时,将被执行的写命令都写入到硬盘里面. 快照持久化 Redis可以通过创建快照来获得在内存里面的数据在某一个时间点上的副本.在创建快照之后,用户可以对快照进行备份,可以将快照复制到其它服务器从而创建具有相同数据的服务器副本,还可以
-
redis 使用lettuce 启动内存泄漏错误的解决方案
redis 使用 lettuce 出现 LEAK: hashedwheelTimer.release() was not called before it's garbage-collected. Enable advanced leak 内存泄漏.其实是内存不够大导致. 找到eclispe 中window->preferences->Java->Installed JRE ,点击右侧的Edit 按钮,在编辑界面中的 "Default VM Arguments "选项
-
详解Redis瘦身指南
Redis内存回收 Redis 服务器的最大占用内存量由配置项 maxmemory 决定,我们可以通过 config set maxmemory 2GB 的格式来配置.一旦 Redis 内存满,所有引起内存增加的操作都会被返回 error.作为专业 Redis 服务器我们通常将此项设置为0,以服务器系统内存来作为限制: 那么 Redis 使用内存达到了上限怎么办?Redis 为我们提供了几种选项以自动回收内存,可以通过配置项 maxmemory-policy 来配置: noeviction 不回
-
redis内存空间效率问题的深入探究
前言 在使用redis时,我们会遇到一个问题,数据删除后,数据量已经不大了,但是使用top命令查看,还会发现redis占用了很对内存.实际上,因为数据删除后,redis释放内存由内存分配器管理,不会立刻返回给操作系统.所以,操作系统仍然记录着给redis分配了大量的内存 这往往会伴随一个潜在的风险点:Redis 释放的内存空间可能并不是连续的,那么,这些不连续的内存空间很有可能处于一种闲置的状态.这就会导致一个问题:虽然有空闲空间,Redis 却无法用来保存数据,不仅会减少 Redis 能够实际
-
浅谈redis内存数据的持久化方式
一.概述 Redis的强大性能很大程度上都是因为所有数据都是存储在内存中的,然而当Redis重启后,所有存储在内存中的数据将会丢失,在很多情况下是无法容忍这样的事情的.所以,我们需要将内存中的数据持久化!典型的需要持久化数据的场景如下: 将Redis作为数据库使用: 将Redis作为缓存服务器使用,但是缓存miss后会对性能造成很大影响,所有缓存同时失效时会造成服务雪崩,无法响应. 本文介绍Redis所支持的两种数据持久化方式. 二.Redis数据持久化 Redis支持两种数据持久化方式:RDB
-
浅谈内存耗尽后Redis会发生什么
前言 作为一台服务器来说,内存并不是无限的,所以总会存在内存耗尽的情况,那么当 Redis 服务器的内存耗尽后,如果继续执行请求命令,Redis 会如何处理呢? 内存回收 使用Redis 服务时,很多情况下某些键值对只会在特定的时间内有效,为了防止这种类型的数据一直占有内存,我们可以给键值对设置有效期.Redis 中可以通过 4 个独立的命令来给一个键设置过期时间: expire key ttl:将 key 值的过期时间设置为 ttl 秒. pexpire key ttl:将 key 值的过期时
-
浅谈java如何实现Redis的LRU缓存机制
目录 LRU概述 使用LinkedHashMap实现 使用LinkedHashMap简单方法实现 双链表+hashmap LRU概述 最近使用的放在前面,最近没用的放在后面,如果来了一个新的数,此时内存满了,就需要把旧的数淘汰,那为了方便移动数据,肯定就得使用链表类似的数据结构,再加上要判断这条数据是不是最新的或者最旧的那么应该也要使用hashmap等key-value形式的数据结构. 使用LinkedHashMap实现 package thread; import java.util.Link
-
浅谈为什么单线程的redis那么快
目录 redis单机QPS 为什么这么快 内存型数据库 简单的数据结构 单线程 IO多路复用 总结 redis单机QPS ./redis-benchmark -t set,lpush -n 100000 -q SET: 82101.80 requests per second LPUSH: 82440.23 requests per second 在自己的电脑上测试SET和LPUSH10万次,可以发现每秒SET和LPUSH大概在8w多,接近官方说的单机10w qps的写. 为什么这么快 内存型数
-
浅谈我是如何用redis做实时订阅推送的
前阵子开发了公司领劵中心的项目,这个项目是以redis作为关键技术落地的. 先说一下领劵中心的项目吧,这个项目就类似京东app的领劵中心,当然图是截取京东的,公司的就不截了... 其中有一个功能叫做领劵的订阅推送.什么是领劵的订阅推送?就是用户订阅了该劵的推送,在可领取前的一分钟就要把提醒信息推送到用户的app中.本来这个订阅功能应该是消息中心那边做的,但他们说这个短时间内做不了.所以让我这个负责优惠劵的做了-.-!.具体方案就是到具体的推送时间点了,coupon系统调用消息中心的推送接口,把信
-
浅谈一下如何保证Redis缓存与数据库的一致性
目录 1.四种同步策略: 2.更新缓存还是删除缓存 2.1 更新缓存 2.2 删除缓存 3.先操作数据库还是缓存 3.1 先删除缓存再更新数据库 3.2 先更新数据库再删除缓存 最终结论: 4.延时双删 4.1 采用读写分离的架构怎么办? 5.利用消息队列进行删除的补偿 1.四种同步策略: 想要保证缓存与数据库的双写一致,一共有4种方式,即4种同步策略: 先更新缓存,再更新数据库: 先更新数据库,再更新缓存: 先删除缓存,再更新数据库: 先更新数据库,再删除缓存. 从这4种同步策略中,我们需要作
-
浅谈Spring Boot中Redis缓存还能这么用
经过Spring Boot的整合封装与自动化配置,在Spring Boot中整合Redis已经变得非常容易了,开发者只需要引入Spring Data Redis依赖,然后简单配下redis的基本信息,系统就会提供一个RedisTemplate供开发者使用,但是今天松哥想和大伙聊的不是这种用法,而是结合Cache的用法.Spring3.1中开始引入了令人激动的Cache,在Spring Boot中,可以非常方便的使用Redis来作为Cache的实现,进而实现数据的缓存. 工程创建 首先创建一个Sp
-
浅谈开启magic_quote_gpc后的sql注入攻击与防范
通过启用php.ini配置文件中的相关选项,就可以将大部分想利用SQL注入漏洞的骇客拒绝于门外. 开启magic_quote_gpc=on之后,能实现addslshes()和stripslashes()这两个函数的功能.在PHP4.0及以上的版本中,该选项默认情况下是开启的,所以在PHP4.0及以上的版本中,就算PHP程序中的参数没有进行过滤,PHP系统也会对每一个通过GET.POST.COOKIE方式传递的变量自动转换,换句话说,输入的注入攻击代码将会全部被转换,将给攻击者带来非常大的困难.
-
浅谈go build后加文件和目录的区别
如下: go build + xxx.go:生成以xxx命名的可执行文件 go build + dir / go build . / go build:生成以目录名命名的可执行文件 补充:golang学习------golang的目录管理以及go install,go build的使用 一个优秀的项目离不开良好的代码管理,golang通过package提供一些代码的管理封装,那么我们应该如何来设计我们的代码结构呢? 我们假设我们需要完成一个项目,项目的功能如下: 在基于package的目录思路下
-
浅谈redis采用不同内存分配器tcmalloc和jemalloc
我们知道Redis并没有自己实现内存池,没有在标准的系统内存分配器上再加上自己的东西.所以系统内存分配器的性能及碎片率会对Redis造成一些性能上的影响. 在Redis的 zmalloc.c 源码中,我们可以看到如下代码: /* Double expansion needed for stringification of macro values. */ #define __xstr(s) __str(s) #define __str(s) #s #if defined(USE_TCMALLOC
-
浅谈Redis 中的过期删除策略和内存淘汰机制
目录 前言 Redis 中 key 的过期删除策略 1.定时删除 2.惰性删除 3.定期删除 Redis 中过期删除策略 从库是否会脏读主库创建的过期键 内存淘汰机制 内存淘汰触发的最大内存 有哪些内存淘汰策略 内存淘汰算法 LRU LFU 为什么数据删除后内存占用还是很高 内存碎片如何产生 碎片率的意义 如何清理内存碎片 总结 参考 前言 Redis 中的 key 设置一个过期时间,在过期时间到的时候,Redis 是如何清除这个 key 的呢? 这来分析下 Redis 中的过期删除策略和内存淘