Node使用Selenium进行前端自动化操作的代码实现
前言:
最近项目中有类似的需求:需要对前端项目中某一个用户下的产品数据进行批量的处理。手动处理的流程大概是首先登录系统,获取到当前用户下的产品列表,点击产品列表的中产品项进入详情页,对该产品进行一系列的操作,然后保存退出。因为当前有20多万条数据,手动一条一条的处理不太现实,所以希望通过写脚本的方式来进行处理。
需求分析
其实这个需求还算比较简单,需要实现的点主要有三个,一是如何进行登录,获取登录信息,查询当前用户下的产品数据;二是如何知道当前数据是否处理完,然后退出当前的处理流程;三是如何异步的处理一批数据。
所以需要做的工作就是模拟登录,调用产品列表的查询接口获取产品ID集合,然后循环遍历当前的集合,通过产品ID跳转产品详情页面,模拟页面按钮的点击操作,监听处理完成的动作,退出当前的流程。
Selenium 介绍
What is Selenium?
Selenium automates browsers. That's it! What you do with that power is entirely up to you. Primarily, it is for automating web applications for testing purposes, but is certainly not limited to just that. Boring web-based administration tasks can (and should!) be automated as well.
Selenium has the support of some of the largest browser vendors who have taken (or are taking) steps to make Selenium a native part of their browser. It is also the core technology in countless other browser automation tools, APIs and frameworks.翻译过来大致意思就是: Selenium 可以自动化操作浏览器。怎么去使用Selenium 的功能完全取决于我们自己。它主要还是使用在web应用的自动化测试上。但是他的功能并不仅限于此。那些枯燥的基于web的管理任务也可以自动化。很多流行的浏览器都采取了一些措施来支持Selenium实现本地化。它也是很多浏览器自动化工具、API自动化以及框架的核心技术。
Selenium 主要分 Selenium WebDriver 以及 Selenium IDE。我主要结合Node来介绍 Selenium WebDriver 的安装使用。本文主要介绍Selenium 结合 Node 的安装使用。需要进行深入研究的同学请自行查看官网文档。
Node 环境搭建
1. node的安装在此不再赘述。点击链接查看官网下载安装方法。
2. express安装
$ npx express-generator
或者
$ npm install -g express-generator
创建项目:
$ express --view=ejs selenium-start $ cd selenium-start $ yarn
启动项目:
$ DEBUG=myapp:* yarn start
至此,Node 项目创建完毕。接下来我们就可以在项目中集成Selenium WebDriver
Selenium WebDriver 集成
1. 安装selenium-webdriver
yarn add selenium-webdriver
2. 下载安装支持不同浏览器的驱动。(此处只介绍Chrome驱动)
[ChromeDriver][3]
下载并解压文件,同时把解压的执行文件放置到 /usr/bin目录下。或者设置相应的PATH路径,确保可执行文件在PATH路径中。
开始使用
进入我们刚才创建的项目文件夹,目录如下:
页面添加一个开始按钮,以及给按钮添加事件。
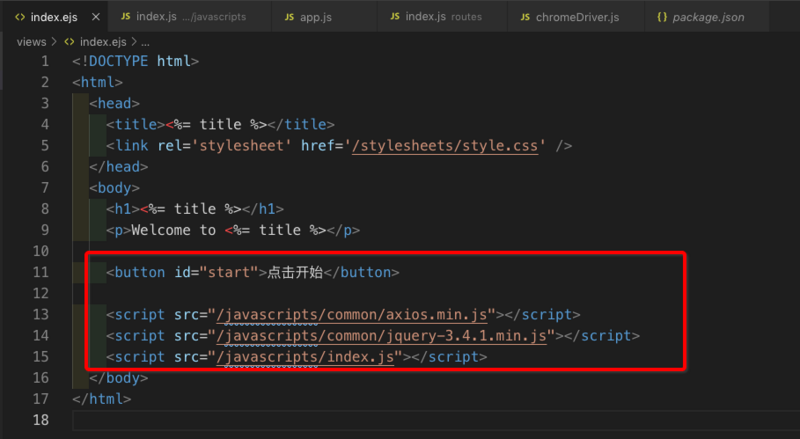
找到 views/index.ejs, 添加如下代码:(为了方便操作,引入了jquery, axios, 所以需要下载准备好)
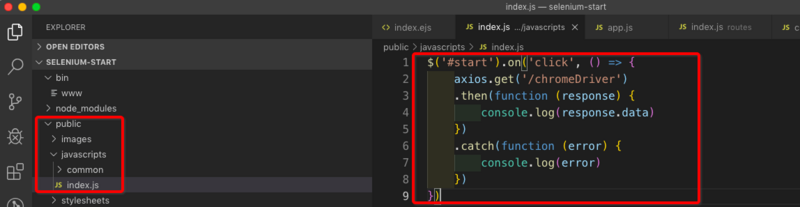
添加对应的路由
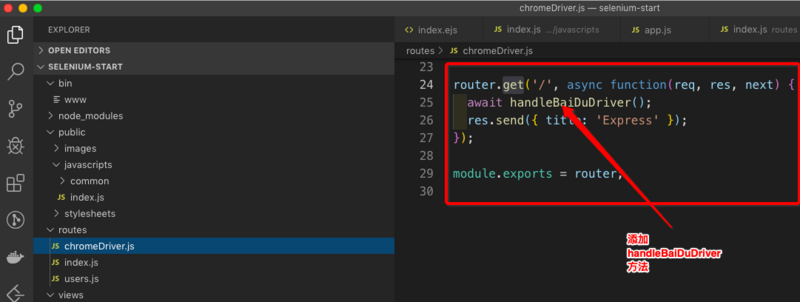
在app.js文件中,引入路由chromeDriver
var chromeDriverRouter = require('./routes/chromeDriver');
app.use('/chromeDriver', chromeDriverRouter);
引入selenium-webdriver
在routes/chromeDirver.js文件中,我们添加了一个方法handleBaiDuDriver,这个方法用于处理模拟百度搜索自动化的一些测试。
首先我们需要在文件顶部引入selenium-webdriver
const {Builder, By, Key, until} = require('selenium-webdriver');
// Builder: 用于创建一个WebDriver实例。
// By: 表示通过什么方式来查找页面的元素。
// By.className( name ) → By
// By.css( selector ) → By
// By.id( id ) → By
// By.js( script, ...var_args ) → function(WebDriver): Promise
// By.linkText( text ) → By
// By.name( name ) → By
// By.partialLinkText( text ) → By
// Key: 表示键盘上一系列的按键。
// until: 定义了一些工具类的方法。
然后书写我们的方法体里的内容。
const handleBaiDuDriver = async () => {
let driver = await new Builder().forBrowser('chrome').build();
try {
await driver.get('http://www.baidu.com');
await driver.findElement(By.id('kw')).sendKeys('webdriver', Key.RETURN);//正常使用
await driver.findElement(By.id('su')).click();
await driver.wait(until.titleIs('百度一下,你就知道'), 1000);
} catch (error) {
console.log(error)
} finally {
await driver.sleep(2000);
await driver.quit();
}
}
启动服务,查看效果。
启动服务之后,我梦能看到如下的界面。

点击页面中的【点击开始】按钮,最终能够看到如下的界面,为了演示我做了两秒的延迟。生成的gif图有9M多,无法上传。后续可以下载源码运行看效果。
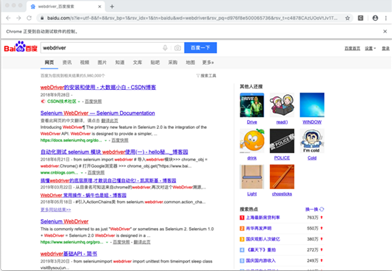
获取登录信息
以上是selenium-webdriver的简单集成。在之前我们提到过实际需求中如何获取登录信息的问题。在访问产品列表页面的时候需要进行登录校验。如果没有登录则会跳转界面。由于我们的登录页是通过iframe来嵌套引入的。由于暂时还没有了解如何处理iframe里的操作,所以没法去模拟用户名密码的输入。
查看API文档,WebDriver 会有一个manage方法:
this.manage() → Options
该方法会返回一个Options实例,具有如下的方法:
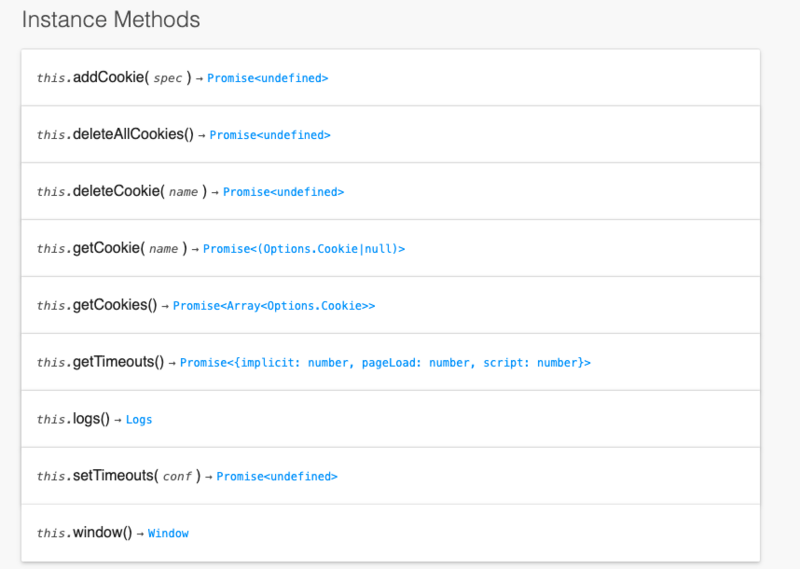
其中有对cookie的操作方法。所以可以通过首次输入用户信息并进行缓存的方式来实现登录态的保存。在下一次再打开页面的时候直接从缓存里获取cookie信息,并通过addCookie方法进行cookie的设置。但是由于我不知道什么时候、多长时间登录才会成功,所以在获取cookie的时候需要通过不断循环的方式去获取,直到拿到cookie。当然可以设置一个超时时间。超时之后就退出当前driver。
// 缓存cookie
async function setCookies(driver) {
const manage = driver.manage();
let sleepTime = 6000;
await driver.sleep(sleepTime);
let cookies = null
try {
cookies = await manage.getCookies();
} catch (error) {
}
while (!cookies || !findSessionIdFromCookies(cookies)) {
await driver.sleep(2000)
sleepTime += 2000;
try {
cookies = await manage.getCookies();
} catch (error) {
}
}
if (cookies && findSessionIdFromCookies(cookies)) {
cache.cookies = cookies; // cache是全局用于缓存cookie的对象
cache.cookiesStr = cache.cookies.map((cookie) => {
return `${cookie.name}=${cookie.value}`
}).join(';');
}
return cookies;
}
// 设置cookie
async function initCookies(driver) {
const cookies = cache.cookies;
if (cookies && cookies.length > 0) {
await driver.manage().deleteAllCookies();
for (let i = 0 ; i < cookies.length; i++) {
cookie = cookies[i];
await driver.manage().addCookie(cookie);
};
}
}
获取到cookie 信息之后就可以请求产品列表以及通过产品ID进入产品详情页。然后再模拟页面按钮点击操作即可。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

使用pm2自动化部署node项目的方法步骤
1.pm2简介 pm2(process manager)是一个进程管理工具,维护一个进程列表,可以用它来管理你的node进程,负责所有正在运行的进程,并查看node进程的状态,也支持性能监控,负载均衡等功能. 1.1.使用pm2管理的node程序的好处 监听文件变化,自动重启程序 支持性能监控 负载均衡 程序崩溃自动重启 服务器重新启动时自动重新启动 自动化部署项目 2.pm2安装与使用 2.1.全局安装 npm install pm2 -g 2.2.常用命令 启动一个node程序 pm2 st
-
nodejs前端自动化构建环境的搭建
为了UED前端团队更好的协作开发同时提高项目编码质量,我们需要将Web前端使用工程化方式构建: 目前需要一些简单的功能: 1. 版本控制 2. 检查JS 3. 图片合并 4. 压缩CSS 5. 压缩JS 6. 编译SASS 这些都是每个Web项目在构建.开发阶段需要做的事情.前端自动化构建环境可以把这些重复工作一次配置,多次重复执行,极大的提高开发效率. 目前最知名的构建工具: Gulp.Grunt.NPM + Webpack: grunt是前端工
-
在Mac OS上安装使用Node.js的项目自动化构建工具Gulp
安装 node.js 首先需要安装 node.js, 通常情况下,只需要到 Node.js 官网下载安装包安装就可以了.不过我可耻的失败了,弹出了如下错误: 于是我换成了 brew 大法: brew install nodejs 安装 Gulp gulp 使用 Node.js 的 npm 命令安装: npm install --global gulp 然后在项目目录中还要安装一遍: npm install --save-dev gulp 我对这步的操作比较费解.以我多年码农经验,即然全局安装过了
-
前端自动化开发之Node.js的环境搭建教程
一.为什么我们前端自动化开发 相信任何学开发的,不管学什么语言,老师都这样讲过,作为一名开发人员,你最大的精力应该是放在创造力上面,don't you repeat myself 不要重复自己,而在我们开发过程中,往往存在很多大量的重复操作,所以我们需要为这些操作省去时间,腾出更多的时间来让我们创造. 而自动化开发能带来哪些自动化: 1.自动编译(将less,sass等自动编译) 2.自动合并(将页面引入的多个js文件,或者css文件,合并为同一个且压缩) 3.自动刷新(IDE保存,浏览器不用刷
-
Node 自动化部署的方法
当我们在更新迭代 Node 项目的时候,我们需要做以下几步: git push 将代码提交至代码仓库 在服务器中执行 git pull 拉取最新代码 pm2 start 运行你的代码 这样做固然没错,但是一旦项目更新迭代过快,就需要不断的重复着上面的步骤,在各种 bash 面板中来回切换,很是麻烦. 这时候,Webhooks 闪亮登场! 对于 Webhooks, Github 给出的解释是: Webhooks allow you to build or set up integrations w
-
Node使用Selenium进行前端自动化操作的代码实现
前言: 最近项目中有类似的需求:需要对前端项目中某一个用户下的产品数据进行批量的处理.手动处理的流程大概是首先登录系统,获取到当前用户下的产品列表,点击产品列表的中产品项进入详情页,对该产品进行一系列的操作,然后保存退出.因为当前有20多万条数据,手动一条一条的处理不太现实,所以希望通过写脚本的方式来进行处理. 需求分析 其实这个需求还算比较简单,需要实现的点主要有三个,一是如何进行登录,获取登录信息,查询当前用户下的产品数据:二是如何知道当前数据是否处理完,然后退出当前的处理流程:三是如何异步
-
C# 利用Selenium实现浏览器自动化操作的示例代码
概述 Selenium是一款免费的分布式的自动化测试工具,支持多种开发语言,无论是C. java.ruby.python.或是C# ,你都可以通过selenium完成自动化测试.本文以一个简单的小例子,简述C# 利用Selenium进行浏览器的模拟操作,仅供学习分享使用,如有不足之处,还请指正. 涉及知识点 要实现本例的功能,除了要掌握Html ,JavaScript,CSS等基础知识,还涉及以下知识点: log4net:主要用于日志的记录和存储,本例采用log4net进行日志记录,便于过程跟踪
-
PyQt5内嵌浏览器注入JavaScript脚本实现自动化操作的代码实例
概要 应同学邀请,演示如何使用 PyQt5 内嵌浏览器浏览网页,并注入 Javascript 脚本实现自动化操作. 下面测试的是一个廉价机票预订网站(http://www.flyscoot.com/),关键点如下 使用 QWebEngineView 加载网页,并显示进度. 在默认配置(QWebEngineProfile)中植入 Javascript 内容,这样脚本会在所有打开的网页中执行,不论跳转到哪个网址. Javascript 脚本使用网址中的路径名,判断当前网页位置,从而决定执行哪种操作.
-
python+selenium的web自动化上传操作的实现
目录 一.关于上传操作 二.input标签 三.第三方库pywin32 四.第三方工具pyautogui 总结 一.关于上传操作 上传有两种情况: 如果是input可以直接输入路径的,那么直接使用send_keys(文件路径)输入路径即可: 非input标签的上传,则需要借助第三方工具:第三方库 pywin32.第三方工具pyautogui等等. 那这里针对以上两种情况分别介绍一下具体的解决方法. 二.input标签 定位到元素,然后直接使用send_keys(文件路径)输入路径,比较简单. f
-
搭建element-ui的Vue前端工程操作实例
一.安装npm镜像 (1)下载node.js, 配置node.js的环境变量 检测PATH环境变量是否配置了Node.js,点击开始=>运行=>输入"cmd" => 输入命令"path" 检查Node.js版本 在命令窗口输入:npm install -g cnpm –registry=https://registry.npm.taobao.org 二.安装全局vue-cli (1)npm install -g vue-cli 回车,验证是否安装成
-
Selenium实现微博自动化运营之关注、点赞、评论功能
Selenium 是什么? Selenium是一个用于Web应用程序测试的工具,可以模拟真正的用户操作,支持多种浏览器,如Firefox,Safari,Google Chrome,Opera等. Selenium 模拟的就是一个真实的用户的操作行为,我们完全不用担心 cookie 追踪和隐藏字段的干扰. 除了Selenium 外,还有Puppeteer 工具可以模拟用户操作,Python + Selenium + 第三方浏览器可以让我们处理多种复杂场景,包括网页动态加载.JS 响应.Post 表
-
python 利用PyAutoGUI快速构建自动化操作脚本
一.背景 大家好,我是安果! 我们经常遇到需要进行大量重复操作的时候,比如:网页上填表,对 web 版本 OA 进行操作,自动化测试或者给新系统首次添加数据等 这些操作的特点往往是:数据同构,大多是已经有了的结构化数据:操作比较呆板,都是同一个流程的点击.输入:数据量大,极大消耗操作人精力 那么能不能自动化呢? 二.自动化的方案 如果你在 web 上进行操作, Python 的 Selenium 可以满足要求.如果需要对 GUI 界面进行操作,你恐怕得试验下"按键精灵"能不能满足要求.
-
python自动化操作之动态验证码、滑动验证码的降噪和识别
目录 前言 一.动态验证码 二.滑动验证码 三.验证码的降噪 四.验证码的识别 总结 前言 python对动态验证码.滑动验证码的降噪和识别,在各种自动化操作中,我们经常要遇到沿跳过验证码的操作,而对于验证码的降噪和识别,的确困然了很多的人.这里我们就详细讲解一下不同验证码的降噪和识别. 一.动态验证码 动态验证码是服务端生成的,点击一次,就会更换一次,这就会造成很多人在识别的时候,会发现验证码一直过期 这是因为,如果你是把图片下载下来,进行识别的话,其实在下载的这个请求中,其实相当于点击了一次