C++中vector容器的注意事项总结
目录
- 容量(capacity)和大小(size)的区别
- 容器扩容的本质
- emplace_back()和push_back()的区别
- emplace()和insert()的区别
- 附:如果vector是空的,并且没有分配空间,切忌用下标进行访问,会出错!!!
- 总结
容量(capacity)和大小(size)的区别
vector 容器的容量(用 capacity 表示),指的是在不分配更多内存的情况下,容器可以保存的最多元素个数;而 vector 容器的大小(用 size 表示),指的是它实际所包含的元素个数。
对于一个 vector 对象来说,通过该模板类提供的 capacity() 成员函数,可以获得当前容器的容量;通过 size() 成员函数,可以获得容器当前的大小。例如:
#include <iostream>
#include <vector>
using namespace std;
int main()
{
std::vector<int>value{ 2,3,5,7,11,13,17,19,23,29,31,37,41,43,47 };
value.reserve(20);
cout << "value 容量是:" << value.capacity() << endl;
cout << "value 大小是:" << value.size() << endl;
return 0;
}
程序输出结果为:
value 容量是:20
value 大小是:15
结合该程序的输出结果,下图可以更好的说明 vector 容器容量和大小之间的关系:
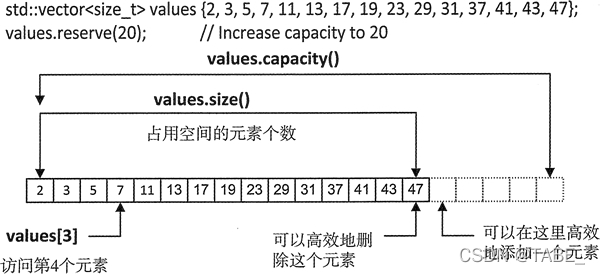
显然,vector 容器的大小不能超出它的容量,在大小等于容量的基础上,只要增加一个元素,就必须分配更多的内存。注意,这里的“更多”并不是 1 个。换句话说,当 vector 容器的大小和容量相等时,如果再向其添加(或者插入)一个元素,vector 往往会申请多个存储空间,而不仅仅只申请 1 个。
一旦 vector 容器的内存被重新分配,则和 vector 容器中元素相关的所有引用、指针以及迭代器,都可能会失效,最稳妥的方法就是重新生成。
容器扩容的本质
vector 容器扩容的过程需要经历以下 3 步:
- 完全弃用现有的内存空间,重新申请更大的内存空间(一般是原空间的1.5倍);
- 将旧内存空间中的数据,按原有顺序移动到新的内存空间中;
- 最后将旧的内存空间释放。
由此可见,vector 扩容是非常耗时的。为了降低再次分配内存空间时的成本,每次扩容时 vector 都会申请比用户需求量更多的内存空间(这也就是 vector 容量的由来,即 capacity>=size),以便后期使用。
emplace_back()和push_back()的区别
vector中可以用来从容器末尾添加元素的函数有 2 个,分别是 push_back() 和 emplace_back() 函数。
push_back()函数的功能是在 vector 容器尾部添加一个元素,用法也非常简单,比如:
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> values{};
values.push_back(1);
values.push_back(2);
for (int i = 0; i < values.size(); i++) {
cout << values[i] << " ";
}
return 0;
}
运行程序,输出结果为:
1 2
emplace_back()函数是 C++ 11 新增加的,其功能和 push_back() 相同,都是在 vector 容器的尾部添加一个元素。
emplace_back() 成员函数的用法也很简单,这里直接举个例子:
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> values{};
values.emplace_back(1);
values.emplace_back(2);
for (int i = 0; i < values.size(); i++) {
cout << values[i] << " ";
}
return 0;
}
运行结果为:
1 2
emplace_back() 和 push_back() 的区别,就在于底层实现的机制不同。push_back() 向容器尾部添加元素时,首先会创建这个元素,然后再将这个元素拷贝或者移动到容器中(如果是拷贝的话,事后会自行销毁先前创建的这个元素);而 emplace_back() 在实现时,则是直接在容器尾部创建这个元素,省去了拷贝或移动元素的过程。(可以看作是零拷贝的实现)
为了让大家清楚的了解它们之间的区别,我们创建一个包含类对象的 vector 容器,如下所示:
#include <vector>
#include <iostream>
using namespace std;
class testDemo
{
public:
testDemo(int num):num(num){
std::cout << "调用构造函数" << endl;
}
testDemo(const testDemo& other) :num(other.num) {
std::cout << "调用拷贝构造函数" << endl;
}
testDemo(testDemo&& other) :num(other.num) {
std::cout << "调用移动构造函数" << endl;
}
private:
int num;
};
int main()
{
cout << "emplace_back:" << endl;
std::vector<testDemo> demo1;
demo1.emplace_back(2);
cout << "push_back:" << endl;
std::vector<testDemo> demo2;
demo2.push_back(2);
}
运行结果为:
emplace_back:
调用构造函数
push_back:
调用构造函数
调用移动构造函数
在此基础上,读者可尝试将 testDemo 类中的移动构造函数注释掉,再运行程序会发现,运行结果变为:
emplace_back:
调用构造函数
push_back:
调用构造函数
调用拷贝构造函数
由此可以看出,push_back() 在底层实现时,会优先选择调用移动构造函数,如果没有才会调用拷贝构造函数。
显然完成同样的操作,push_back() 的底层实现过程比 emplace_back() 更繁琐,换句话说,emplace_back() 的执行效率比 push_back() 高。因此,在实际使用时,建议大家优先选用 emplace_back()。
emplace()和insert()的区别
insert() 函数的功能是在 vector 容器的指定位置插入一个或多个元素。
下面的例子,演示了如何使用 insert() 函数向 vector 容器中插入元素。
#include <iostream>
#include <vector>
#include <array>
using namespace std;
int main()
{
std::vector<int> demo{1,2};
//第一种格式用法
demo.insert(demo.begin() + 1, 3);//{1,3,2}
//第二种格式用法
demo.insert(demo.end(), 2, 5);//{1,3,2,5,5}
//第三种格式用法
std::array<int,3>test{ 7,8,9 };
demo.insert(demo.end(), test.begin(), test.end());//{1,3,2,5,5,7,8,9}
//第四种格式用法
demo.insert(demo.end(), { 10,11 });//{1,3,2,5,5,7,8,9,10,11}
for (int i = 0; i < demo.size(); i++) {
cout << demo[i] << " ";
}
return 0;
}
运行结果为:
1 3 2 5 5 7 8 9 10 11
emplace()是 C++ 11 标准新增加的成员函数,用于在 vector 容器指定位置之前插入一个新的元素。emplace() 每次只能插入一个元素,而不是多个。
该函数的语法格式如下:
iterator emplace (const_iterator pos, args...);
其中,pos 为指定插入位置的迭代器;args… 表示与新插入元素的构造函数相对应的多个参数;该函数会返回表示新插入元素位置的迭代器。
举个例子:
#include <vector>
#include <iostream>
using namespace std;
int main()
{
std::vector<int> demo1{1,2};
//emplace() 每次只能插入一个 int 类型元素
demo1.emplace(demo1.begin(), 3);
for (int i = 0; i < demo1.size(); i++) {
cout << demo1[i] << " ";
}
return 0;
}
运行结果为:
3 1 2
既然 emplace() 和 insert() 都能完成向 vector 容器中插入新元素,那么谁的运行效率更高呢?答案是 emplace()。在说明原因之前,通过下面这段程序,就可以直观看出两者运行效率的差异:
#include <vector>
#include <iostream>
using namespace std;
class testDemo
{
public:
testDemo(int num) :num(num) {
std::cout << "调用构造函数" << endl;
}
testDemo(const testDemo& other) :num(other.num) {
std::cout << "调用拷贝构造函数" << endl;
}
testDemo(testDemo&& other) :num(other.num) {
std::cout << "调用移动构造函数" << endl;
}
testDemo& operator=(const testDemo& other);
private:
int num;
};
testDemo& testDemo::operator=(const testDemo& other) {
this->num = other.num;
return *this;
}
int main()
{
cout << "insert:" << endl;
std::vector<testDemo> demo2{};
demo2.insert(demo2.begin(), testDemo(1));
cout << "emplace:" << endl;
std::vector<testDemo> demo1{};
demo1.emplace(demo1.begin(), 1);
return 0;
}
运行结果为:
insert:
调用构造函数
调用移动构造函数
emplace:
调用构造函数
注意,当拷贝构造函数和移动构造函数同时存在时,insert() 会优先调用移动构造函数。
可以看到,通过 insert() 函数向 vector 容器中插入 testDemo 类对象,需要调用类的构造函数和移动构造函数(或拷贝构造函数);而通过 emplace() 函数实现同样的功能,只需要调用构造函数即可。
简单的理解,就是 emplace() 在插入元素时,是在容器的指定位置直接构造元素,而不是先单独生成,再将其复制(或移动)到容器中。因此,在实际使用中,推荐大家优先使用 emplace()。
附:如果vector是空的,并且没有分配空间,切忌用下标进行访问,会出错!!!
int main()
{
vector<int>v;
v[0]=1;
return 0;
}
成功编译,但是运行的时候报错Process finished with exit code 139 (interrupted by signal 11: SIGSEGV)。因此,当vector为空的时候,一定要用push_back()添加值。
但是,如果在定义动态数组v之后,经过了resize 或reserve之后,就可以通过下标访问
vector<int>v;
// v.resize(5); //也可以
v.reserve(5);
v[0]=1;
resize的时候会给vector里面填充0,而reserve不会
vector<int> v1;
v1.reserve(5);
for(int i=0;i<v1.size();i++)
{
cout<<v1[i]<<" ";
}
cout<<endl;
vector<int> v2;
v2.resize(5);
for(int i=0;i<v2.size();i++)
{
cout<<v2[i]<<" ";
}
运行结果:

总结
到此这篇关于C++中vector容器注意事项的文章就介绍到这了,更多相关C++ vector容器注意内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C++中的vector容器对象学习笔记
C++中数组很坑,有没有类似Python中list的数据类型呢?类似的就是vector! vector 是同一种类型的对象的集合 ,每个对象都有一个对应的整数索引值.和 string 对象一样,标准库将负责管理与存储元素相关的内存. 我们把 vector 称为容器,是因为它可以包含其他对象 . 一个容器中的所有对象都必须是同一种类型的 . vector对象的定义和初始化 同样的,使用前,导入头文件#include <vector> 可以使用using声明:using std::vector;
-

C++ STL入门教程(1) vector向量容器使用方法
一.简介 Vectors 包含着一系列连续存储的元素,其行为和数组类似. 访问Vector中的任意元素或从末尾添加元素都可以在O(1)内完成,而查找特定值的元素所处的位置或是在Vector中插入元素则是O(N). 二.完整程序代码 /*请务必运行以下程序后对照阅读*/ #include <vector> #include <iostream> #include <algorithm> #include <stdexcept> using namespace
-
详解C++中的vector容器及用迭代器访问vector的方法
vector vector是相同类型对象的集合.集合中的每个对象有个对应的索引.vector常被称为容器(container). 为了使用vector,需要: #include <vector> using std::vector; vector是一个类模版(class template).C++有函数模版和类模版.模版本身不是函数或类,必须通过指定 类型让编译器去实例化(instantiation)它.比如vector<int> ivec. vector是模版,不是类型.从vec
-
C++中vector容器的常用操作方法实例总结
1 获得容器最后一个元素 ------ 使用 back或rbegin 取得 // back.rbegin 有常量和引用两种形式 std::vector<int> myVector; myVector.back()=3; std::vector<int>::reverse_iterator tailIter; tailIter=myVector.rbegin(); *tailIter=3 2 删除某元素 需要删除某位置的元素,应使用iterator遍历, 不应使用at(i) 方式遍
-
C++中vector容器的用法
在c++中,vector是一个十分有用的容器,下面对这个容器做一下总结. 1 基本操作 (1)头文件#include<vector>. (2)创建vector对象,vector<int> vec; (3)尾部插入数字:vec.push_back(a); (4)使用下标访问元素,cout<<vec[0]<<endl;记住下标是从0开始的. (5)使用迭代器访问元素. vector<int>::iterator it; for(it=vec.begi
-
C++容器vector实现通讯录功能
之前学习C语言的时候,用链表实现过通讯录的基本功能.最近写了一个C++版本的通讯录,参考代码如下所示. main.cpp /***************************************************** Copyright (C): 2017-2018 File name : main.cpp Author : Zhengqijun Date : 2017年02月12日 星期日 16时47分52秒 Description : 主函数 Funcion List : ma
-
C++中vector容器使用详细说明
在c++中,vector是一个十分有用的容器,下面通过本文给大家介绍C++中vector容器使用详细说明,具体介绍如下所示 1. 在C++中的详细说明 vector是C++标准模板库中的部分内容,它是一个多功能的,能够操作多种数据结构和算法的模板类和函数库. vector之所以被认为是一个容器,是因为它能够像容器一样存放各种类型的对象,简单地说,vector是一个能够存放任意类型的动态数组,能够增加和压缩数据. 2. 使用vector,必须在你的头文件中包含下面的代码: #include vec
-
C++ vector容器实现贪吃蛇小游戏
本文实例为大家分享了C++ vector容器 实现贪吃蛇,供大家参考,具体内容如下 使用vector容器实现贪吃蛇简化了很多繁琐操作,且相比之前我的代码已经做到了尽量的简洁 技术环节: 编译环境:windows VS2019 需求: 控制贪吃蛇吃食物,吃到一个食物蛇身变长一节,得分增加,撞墙或撞自己则游戏结束. 思路: 创建一个vector容器,容器内存储蛇的每节身体的结构变量,结构变量中保存蛇身体的xy坐标,通过使用vector成员方法不断添加和删除容器中的数据,实现蛇坐标的规律移动,吃到食物
-
C++中vector容器的注意事项总结
目录 容量(capacity)和大小(size)的区别 容器扩容的本质 emplace_back()和push_back()的区别 emplace()和insert()的区别 附:如果vector是空的,并且没有分配空间,切忌用下标进行访问,会出错!!! 总结 容量(capacity)和大小(size)的区别 vector 容器的容量(用 capacity 表示),指的是在不分配更多内存的情况下,容器可以保存的最多元素个数:而 vector 容器的大小(用 size 表示),指的是它实际所包含的
-
关于STL中vector容器的一些总结
1.vector的简单介绍 vector作为STL提供的标准容器之一,是经常要使用的,有很重要的地位,并且使用起来也是灰常方便.vector又被称为向量,vector可以形象的描述为长度可以动态改变的数组,功能和数组较为相似.实际上更专业的描述为:vector是一个多功能的,能够操作多种数据结构和算法的模板类和函数库,vector之所以被认为是一个容器,是因为它能够像容器一样存放各种类型的对象,简单地说,vector是一个能够存放任意类型的动态数组,能够增加和压缩数据.(注:STL的容器从实现的
-
C++ STL中vector容器的使用
目录 一.vector (1)区分size()和capacity() (2)迭代器失效 (3)区分const_iterator和constiterator (4)区分reserve()和resize() (5)push_back和emplace (6)关于原位构造(定位new+完美转发) 总结 一.vector (1)区分size()和capacity() size():返回容纳的元素个数 capacity():返回当前分配存储的容量 (2)迭代器失效 (3)区分const_iterator和c
-
C++ 中Vector常用基本操作
标准库vector类型是C++中使用较多的一种类模板,vector类型相当于一种动态的容器,在vector中主要有一些基本的操作,下面通过本文给大家介绍,具体内容如下所示: (1)头文件#include<vector>. (2)创建vector对象,vector<int> vec; (3)尾部插入数字:vec.push_back(a); (4)使用下标访问元素,cout<<vec[0]<<endl;记住下标是从0开始的. (5)使用迭代器访问元素. vect
-
C++中vector的用法实例解析
本文实例展示了C++中的vector用法,分享给大家供大家参考.具体如下: 一.概述 vector是C++标准模板库中的部分内容,它是一个多功能的,能够操作多种数据结构和算法的模板类和函数库.vector是一个容器,它能够存放各种类型的对象,简单地说,vector是一个能够存放任意类型的动态数组,可以动态改变大小. 例如: // c语言风格 int myHouse[100] ; // 采用vector vector<int> vecMyHouse(100); 当如上定义后,vecMyHouse
-
C++中vector和map的删除方法(推荐)
1.连续内存序列容器(vector,string,deque) 序列容器的erase方法返回值是指向紧接在被删除元素之后的元素的有效迭代器,可以根据这个返回值来安全删除元素. vector<int> c; for(vector<int>::iterator it = c.begin(); it != c.end();) { if(need_delete()) it = c.erase(it); else ++it; } 2.关联容器(set,multiset,map,multima
-
关于STL中list容器的一些总结
1.关于list容器 list是一种序列式容器.list容器完成的功能实际上和数据结构中的双向链表是极其相似的,list中的数据元素是通过链表指针串连成逻辑意义上的线性表,也就是list也具有链表的主要优点,即:在链表的任一位置进行元素的插入.删除操作都是快速的.list的实现大概是这样的:list的每个节点有三个域:前驱元素指针域.数据域和后继元素指针域.前驱元素指针域保存了前驱元素的首地址:数据域则是本节点的数据:后继元素指针域则保存了后继元素的首地址.其实,list和循环链表也有相似的地方