使用sharding-jdbc实现水平分库+水平分表的示例代码
前面的文章使用sharding-jdbc实现水平分表中详细记录了如何使用sharding-jdbc实现水平分表,即根据相应的策略,将一部分数据存入到表1中,一部分数据存入到表2中,逻辑上为同一张表,分表操作全部交由sharding-jdbc进行处理。
可能根据需要,还需要将一张表的数据拆分存入到多个数据库中,甚至多个数据库的多个表中,使用sharding-jdbc同样可以实现。
重复的篇幅则不再赘述,下面重点记录升级的过程。
分库分表策略:将id为偶数的存入到库1中,奇数存入到库2中,在每个库中,再根据学生的性别分别存到到表1和表2中。
新建两个数据库sharding_db1和sharding_db2,在两个数据库中在分别创建结构相同的两张表,student_1和student_2。
CREATE TABLE `NewTable` ( `ID` bigint(20) NOT NULL , `NAME` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL , `AGE` int(11) NOT NULL , `GENDER` int(1) NOT NULL , PRIMARY KEY (`ID`) );
相比前面文章中,将gender性别字段设置成了int类型,方便根据性别再进行分表。
修改配置文件
spring.main.allow-bean-definition-overriding=true
# 配置Sharding-JDBC的分片策略
# 配置数据源,给数据源起名g1,g2...此处可配置多数据源
spring.shardingsphere.datasource.names=g1,g2
# 配置数据源具体内容:连接池,驱动,地址,用户名,密码
spring.shardingsphere.datasource.g1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.g1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.g1.url=jdbc:mysql://localhost:3306/sharding_db1?characterEncoding=utf-8&useUnicode=true&useSSL=false&serverTimezone=UTC
spring.shardingsphere.datasource.g1.username=root
spring.shardingsphere.datasource.g1.password=123456
spring.shardingsphere.datasource.g2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.g2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.g2.url=jdbc:mysql://localhost:3306/sharding_db2?characterEncoding=utf-8&useUnicode=true&useSSL=false&serverTimezone=UTC
spring.shardingsphere.datasource.g2.username=root
spring.shardingsphere.datasource.g2.password=123456
# 配置数据库的分布,表的分布
spring.shardingsphere.sharding.tables.student.actual-data-nodes=g$->{1..2}.student_$->{1..2}
# 指定student表 主键gid 生成策略为 SNOWFLAKE
spring.shardingsphere.sharding.tables.student.key-generator.column=id
spring.shardingsphere.sharding.tables.student.key-generator.type=SNOWFLAKE
# 指定数据库分片策略 约定id值是偶数添加到sharding_db1中,奇数添加到sharding_db2中
spring.shardingsphere.sharding.tables.student.database-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.student.database-strategy.inline.algorithm-expression=g$->{id % 2 + 1}
# 指定表分片策略 约定gender值是0添加到student_1表,如果gender是1添加到student_2表
spring.shardingsphere.sharding.tables.student.table-strategy.inline.sharding-column=gender
spring.shardingsphere.sharding.tables.student.table-strategy.inline.algorithm-expression=student_$->{gender % 2 + 1}
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
配置多个数据源时,使用逗号隔开,分别配置其属性。除了配置表分片策略,还需配置库分配策略。
测试类
@SpringBootTest
class ShardingJdbcDemoApplicationTests {
@Autowired
private StudentMapper studentMapper;
@Test
public void test01() {
for (int i = 0; i < 15; i++) {
Student student = new Student();
student.setName("wuwl");
student.setAge(27);
student.setGender(i%2);
studentMapper.insert(student);
}
}
}
运行效果:

看样子是成功了,查看数据库数据。
sharding_db1.student_1:
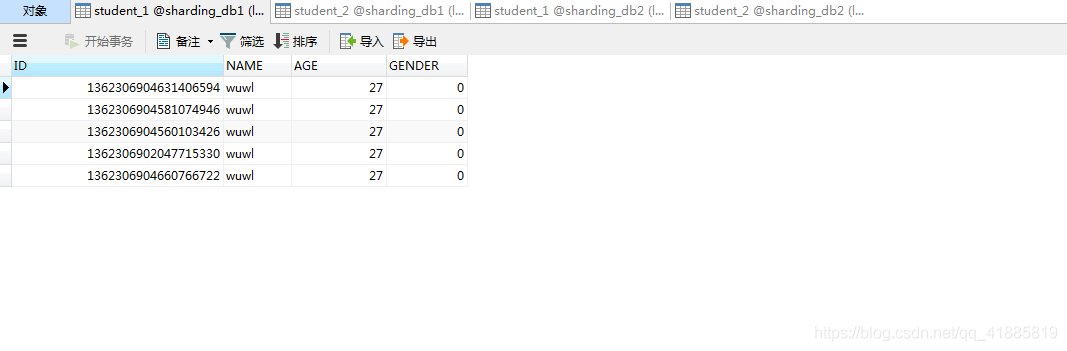
sharding_db1.student_2:

sharding_db2.student_1:
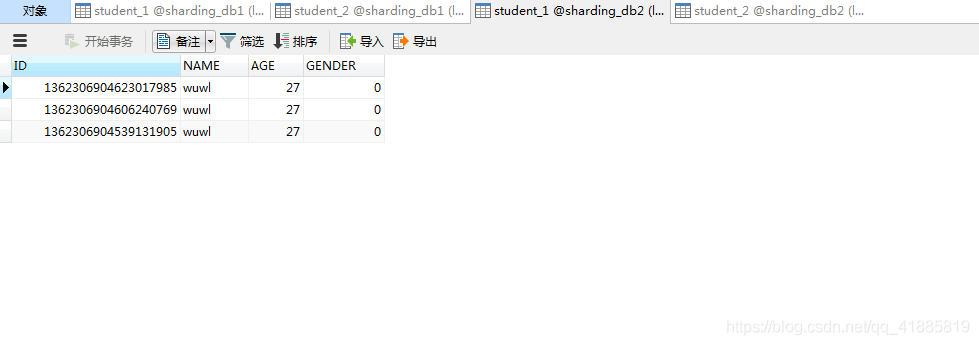
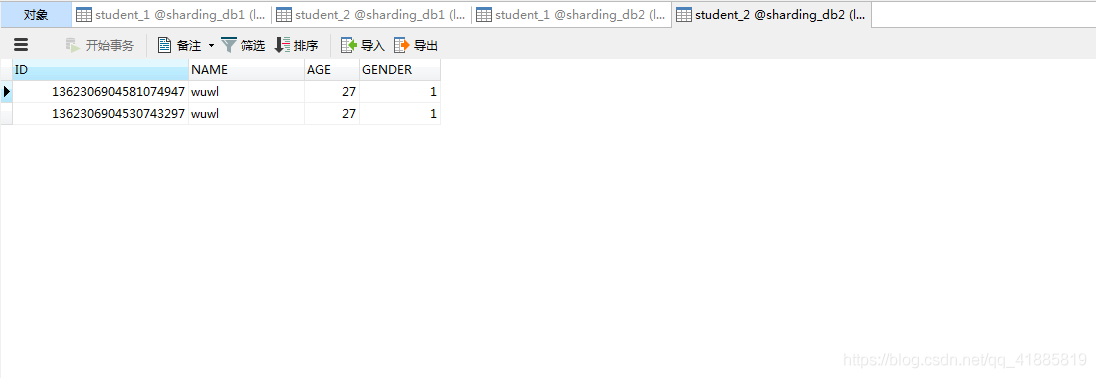
sharding_db2.student_2:
到此这篇关于使用sharding-jdbc实现水平分库+水平分表的示例代码的文章就介绍到这了,更多相关sharding-jdbc水平分库水平分表内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

使用sharding-jdbc实现水平分表的示例代码
目录 在mysql中新建数据库sharding_db,新增两张结构一样的表student_1和student_2. 添加依赖 编写配置文件 编写实体类 编写mapper接口 编写测试类 执行测试 在mysql中新建数据库sharding_db,新增两张结构一样的表student_1和student_2. CREATE TABLE `student_1` ( `ID` bigint(20) NOT NULL , `NAME` varchar(50) CHARACTER SET utf8mb4 CO
-
springboot实现以代码的方式配置sharding-jdbc水平分表
目录 关于依赖 shardingsphere-jdbc-core-spring-boot-starter shardingsphere-jdbc-core 数据源DataSource 原DataSource ShardingJdbcDataSource 完整的ShardingJdbcDataSource配置 分表策略 主要的类 其他的分表配置类 groovy行表达式说明 properties配置 Sharding-jdbc的坑 结语 多数项目可能是已经运行了一段时间,才开始使用sharding-
-
使用sharding-jdbc实现水平分库+水平分表的示例代码
前面的文章使用sharding-jdbc实现水平分表中详细记录了如何使用sharding-jdbc实现水平分表,即根据相应的策略,将一部分数据存入到表1中,一部分数据存入到表2中,逻辑上为同一张表,分表操作全部交由sharding-jdbc进行处理. 可能根据需要,还需要将一张表的数据拆分存入到多个数据库中,甚至多个数据库的多个表中,使用sharding-jdbc同样可以实现. 重复的篇幅则不再赘述,下面重点记录升级的过程. 分库分表策略:将id为偶数的存入到库1中,奇数存入到库2中,在每个库中
-
Mysql的水平分表与垂直分表的讲解
在我上一篇文章中说过,mysql语句的优化有局限性,mysql语句的优化都是围绕着索引去优化的,那么如果mysql中的索引也解决不了海量数据查询慢的状况,那么有了水平分表与垂直分表的出现(我就是记录一下自己的理解) 水平分表: 如上图所示:另外三张表表结构是一样的 只不过把数据进行分别存放在这三张表中,如果要insert 或者query 那么都需要对id进行取余 然后table名进行拼接,那么就是一张完整的table_name 但是如果我需要对name进行分表呢 或者对email呢? 那么就需
-
springboot+mybatis拦截器方法实现水平分表操作
目录 1.前言 2.MyBatis 允许使用插件来拦截的方法 3.Interceptor接口 4分表实现 4.1.大体思路 4.2.1 Mybatis如何找到我们新增的拦截服务 4.2.2 应该拦截什么样的对象 4.2.3 实现自定义拦截器 4.2.逐步实现 1.前言 业务飞速发展导致了数据规模的急速膨胀,单机数据库已经无法适应互联网业务的发展.由于MySQL采用 B+树索引,数据量超过阈值时,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降:高并发访问请求也使得集中式数
-
SQL Server 数据库分区分表(水平分表)详细步骤
1. 需求说明 将数据库Demo中的表按照日期字段进行水平分区分表.要求数据文件按一年一个文件存储,且分区的分割点会根据时间的增长自动添加(例如现在是2017年1月1日,将其作为一个分割点,即将2017年1月1日之前的数据存储到数据文件A中,将2017年1月1日的之后的数据存储到数据文件B中:当时间到2018年1月1日时,自动将2018年1月1日添加为一个新的分区分割点,并将2017年1月1日至2018年1月1日的数据存储在数据文件B中,将2018年1月1日之后的数据存储在一个新的数据文件C中,
-
Springboot2.x+ShardingSphere实现分库分表的示例代码
之前一篇文章中我们讲了基于Mysql8的读写分离(文末有链接),这次来说说分库分表的实现过程. 概念解析 垂直分片 按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用. 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务.而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库. 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案. 垂直分片往往需要对架构和设计进行调整.通常来讲,是来不及应对互联网业务需求快速变化
-
SpringBoot集成Sharding Jdbc使用复合分片的实践
目录 1.Sharing JDBC 简介 2.系统改造 2.1 对接外部系统的系统 2.2 内部系统间的调用 3.解决方案 4.代码实现 4.1 Sharding JDBC 配置 4.2 数据源操作类 4.3 分片测试类 4.4 测试结果 参考文章: 最近主要的工作重心是数据库的容量规划. 随着业务的逐渐增大,原有保存在单表的数据量也日益增强.数据库数据会随着业务的发展而不断增多,因此数据操作,如增删改查的开销也会越来越大.再加上物理服务器的资源有限(CPU.磁盘.内存.IO 等).最终数据库所
-
mybatis水平分表实现动态表名的项目实例
目录 一.水平分表 二.项目实现 目录结构 三.扩展 一.水平分表 当业务需求的数据量过大时,一个表格存储数据会非常之多,故时长采用水平分表的方式来减少每张表的数据量即是提升查询数据库时的效率. 水平分表时,各表的结构完全一样,表名不同. 例如:这里我们建了10张user表,每张表的结构完全一致,表名由0~9. 表中包含有id和name属性且都采用varchar的存储类型. 为什么id没有采用int自增的形式? 大型项目极有可能采用分布式数据库,若采用自增的方式,会导致id重复.且id也不一定只
-
SpringBoot 如何使用sharding jdbc进行分库分表
目录 基于4.0版本,Springboot2.1 在pom里确保有如下引用 里面我profiles.active了另一个 之后手工把表都建好 写个测试代码 需要注意一个坑 基于4.0版本,Springboot2.1 之前写过一篇使用sharding-jdbc进行分库分表的文章,不过当时的版本还比较早,现在已经不能用了.这一篇是基于最新版来写的. 新版已经变成了shardingsphere了,https://shardingsphere.apache.org/. 有点不同的是,这一篇,我们是采用多