selenium与xpath之获取指定位置的元素的实现
今天有点新的与大家分享,关于selenium与xpath之间爬数据获取指定位置的时候,方式不一样哦。
详情可以看我的代码,以b站来看好吧:
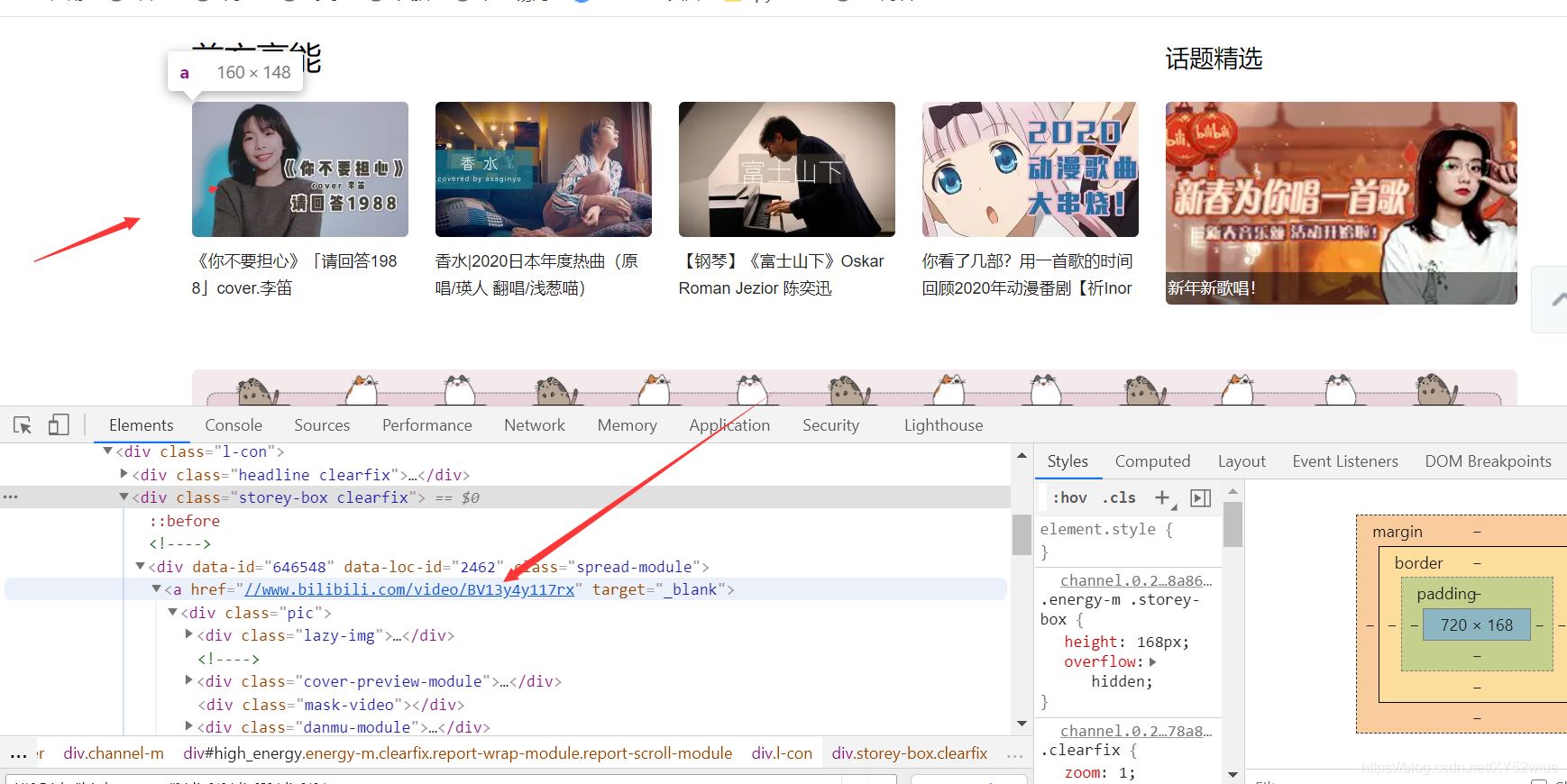
查看这href元素,如果是xpath,肯定这么写是没有问题的:
i.find_element_by_xpath('./a/@href')
但你再selenium里面这样写会报错,所以要改成这样
i.find_element_by_xpath('./a').get_attribute('href')
这样方可正确
这是一个小案例,关于爬取b站音乐视频,但我的技术水平有限,无法下载,找不到那个东东
大家如果知道如何下载可以在评论区留言,嘿嘿
import requests
from selenium.webdriver import Chrome,ChromeOptions
#后面越来越多喜欢用函数来实现了
def get_webhot(): #热搜函数
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
url ="https://www.bilibili.com/" # 微博的地址
res = requests.get(url)
#这个就是再后台上面运行那个浏览器,不在表面上占用你的
option = ChromeOptions()
option.add_argument('--headless')
option.add_argument("--no-sandbox")
#这里也要输入
browser = Chrome(options=option)
browser.get(url)
#解析那个web热搜前,按住ctrl+f会在下面出现一个框框,然后改就完事
browser.find_element_by_xpath('//*[@id="primaryChannelMenu"]/span[3]/div/a/span').click()
c = browser.find_elements_by_xpath('//*[@id="high_energy"]/div[1]/div[2]/div')
for i in c:
#这里一定要注意,在selenium中不能像xpath那样写('./a/@href')来获取指定的位置,要报错,只能这么获取,查了很久
detail_url = i.find_element_by_xpath('./a').get_attribute('href')
name = i.find_element_by_xpath('./a/p').get_attribute('title')
detail_page_text = requests.get(url=detail_url,headers = headers).text
print(detail_url,name)
#运行完事
get_webhot()
这是这个结果

到此这篇关于selenium与xpath之获取指定位置的元素的实现的文章就介绍到这了,更多相关selenium与xpath指定位置元素内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python Selenium XPath根据文本内容查找元素的方法
问题现象 元素的属性中没有id.name:虽然有class,但比较大众化,且位置也不固定:例如:页码中的下一页:那该如何找到该元素? <a class="paging">上一页</div> <a class="paging">1</div> <a class="paging">2</div> <a class="paging">下一页</
-

selenium与xpath之获取指定位置的元素的实现
今天有点新的与大家分享,关于selenium与xpath之间爬数据获取指定位置的时候,方式不一样哦. 详情可以看我的代码,以b站来看好吧: 查看这href元素,如果是xpath,肯定这么写是没有问题的: i.find_element_by_xpath('./a/@href') 但你再selenium里面这样写会报错,所以要改成这样 i.find_element_by_xpath('./a').get_attribute('href') 这样方可正确 这是一个小案例,关于爬取b站音乐视频,但我的技
-
R语言 如何获取指定位置的数据
R语言-获取指定位置的数据 R中采用数据对象+[ , ]的方式获取对应位置的数据,根据填入索引参数的不同类型可具体分为: 正整数.负整数.零.空格.逻辑值.名称 > matrix [,1] [,2] [,3] [,4] [,5] [1,] 1 5 9 13 17 [2,] 2 6 10 14 18 [3,] 3 7 11 15 19 [4,] 4 8 12 16 20 1.正整数索引 因为R中的起始位置为1,与一般的编程语言不同,所以这类索引最为常见. 需要注意的是,如果索引中存在重复值,R会继
-
java 实现获取指定位置后的第一个数字
目录 获取指定位置后的第一个数字 环境 场景 代码 获取一串数字中每一位数的小技巧 获取指定位置后的第一个数字 环境 java:1.7 场景 今天遇到这么一个需求: 10转增7.5股派1.5元(含税) 10派1.5元(含税) 不分配不转增 10转增3股 10派1.34元(含税) 10送2转增8股派0.3元 10送2.5转增1.5股 10送2股 会有类似上面的字符串,需要根据“送”,“增”和“派”来把后面的数字给切出来:再进行拼接. 比如: 字符串为“10送2转增8股派0.3元”,根据“送”来切,
-
在 javascript 中如何快速获取数组指定位置的元素
目录 前言 数组的 at() 方法 前言 在 JavaScript 中如果我们需要获取一个数组指定位置的元素,通常情况下,我们一般采用以下方法: 1.通过下标直接获取指定元素:arr[index], index 为非负数. let arr = [1, 4, 5, 8, 10] // 获取数组的第一个元素 let num1 = arr[0] // 获取数组的最后一个元素 let num2 = arr[arr.length - 1] // 获取数组的倒数第二个元素 let num3 = arr[ar
-
js从数组中删除指定值(不是指定位置)的元素实现代码
引用自百度知道里面的一个问答 例如数组{1,2,3,4,5} 要把数组里面的3删除得到{1,2,4,5} js代码: <script type="text/javascript"> Array.p Array.prototype.indexOf = function(val) { //prototype 给数组添加属性 for (var i = 0; i < this.length; i++) { //this是指向数组,this.length指的数组类元素的数量 i
-
在JS数组特定索引处指定位置插入元素的技巧
如何在JS数组特定索引处指定位置插入元素? 需求: 将一个元素插入到现有数组的特定索引处.听起来很容易和常见,但需要一点时间来研究它. // 原来的数组 var array = ["one", "two", "four"]; // splice(position, numberOfItemsToRemove, item) // 拼接函数(索引位置, 要删除元素的数量, 元素) array.splice(2, 0, "three"
-
Java之数组在指定位置插入元素实现
1.假设在已知数组中在指定位置添加一个元素,那么在这位置的数据元素就会被替换掉. 代码: public class InsertArray { public static void main(String[] args) { int index = 2; int value = 5; int[] array = new int[]{1,2,3,4}; array[index] = value; System.out.println(Arrays.toString(array)); } } 测试结
-
JS如何在数组指定位置插入元素
一.JavaScript splice() 方法 splice() 方法向/从数组中添加/删除项目,然后返回被删除的项目. 方法实例 //在数组指定位置插入 var fruits = ["Banana", "Orange", "Apple", "Mango"]; fruits.splice(2, 0, "Lemon", "Kiwi"); //输出结果 //Banana, Orange,
-
在JS数组特定索引处指定位置插入元素
很多与数组有关的任务听起来很简单,但实际情况并不总是如此,而开发人员在很多时候也用不到他.最近我碰到了这样一个需求: 将一个元素插入到现有数组的特定索引处.听起来很容易和常见,但需要一点时间来研究它. // 原来的数组 var array = ["one", "two", "four"]; // splice(position, numberOfItemsToRemove, item) // 拼接函数(索引位置, 要删除元素的数量, 元素) ar
-
使用selenium+chromedriver+xpath爬取动态加载信息
目录 安装selenium模块 说 明 selenium模块的使用 selenium 模块的常用方法 总 结 使用selenium实现动态渲染页面的爬取,selenium是浏览器自动化测试框架,是一个用于Web应用程序测试的工具,可以直接运行在浏览器当中,并可以驱动浏览器执行指定的动作,如点击.下拉.填充数据.删除cookie等操作,还可以获取浏览器当前页面的源代码,就像用户在浏览器中操作一样.该工具所支持的浏览器有IE浏览器.Mozilla Firefox以及Google Chrome等. 安