Python爬虫入门教程02之笔趣阁小说爬取
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
前文
01、python爬虫入门教程01:豆瓣Top电影爬取
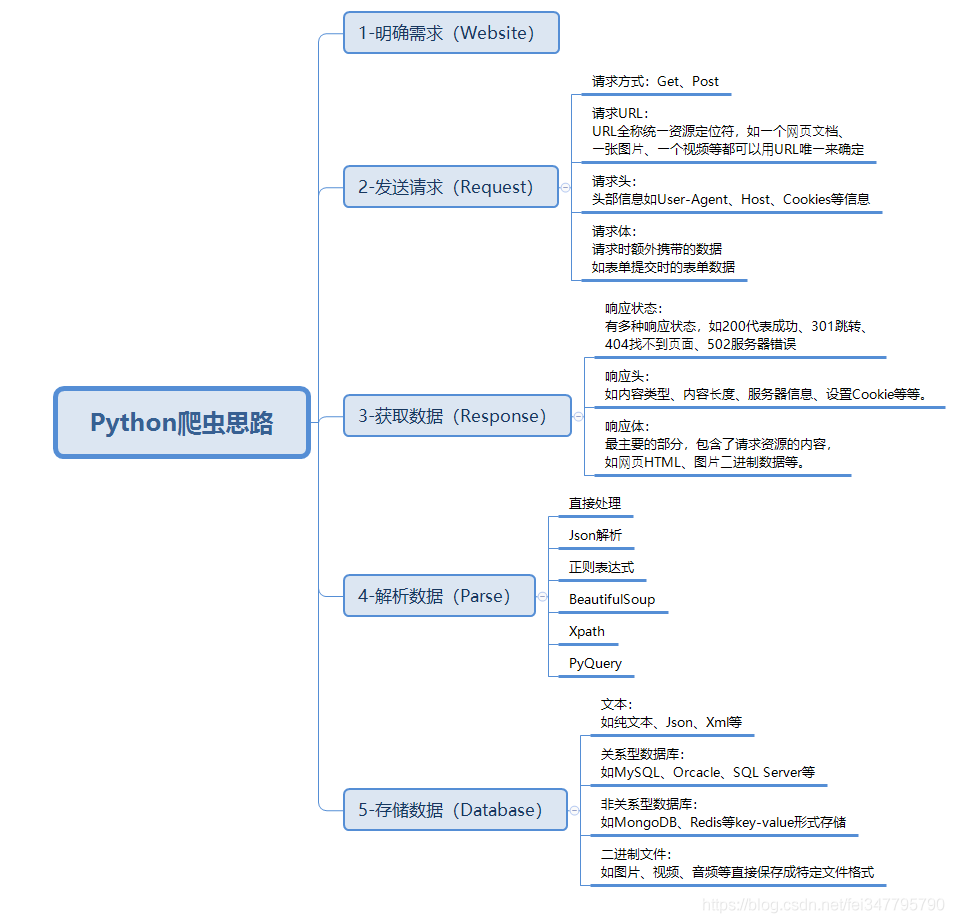
基本开发环境
- Python 3.6
- Pycharm
相关模块的使用
- request
- sparsel
安装Python并添加到环境变量,pip安装需要的相关模块即可。
单章爬取
一、明确需求
爬取小说内容保存到本地
- 小说名字
- 小说章节名字
- 小说内容
# 第一章小说url地址 url = 'http://www.biquges.com/52_52642/25585323.html'
url = 'http://www.biquges.com/52_52642/25585323.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response.text)
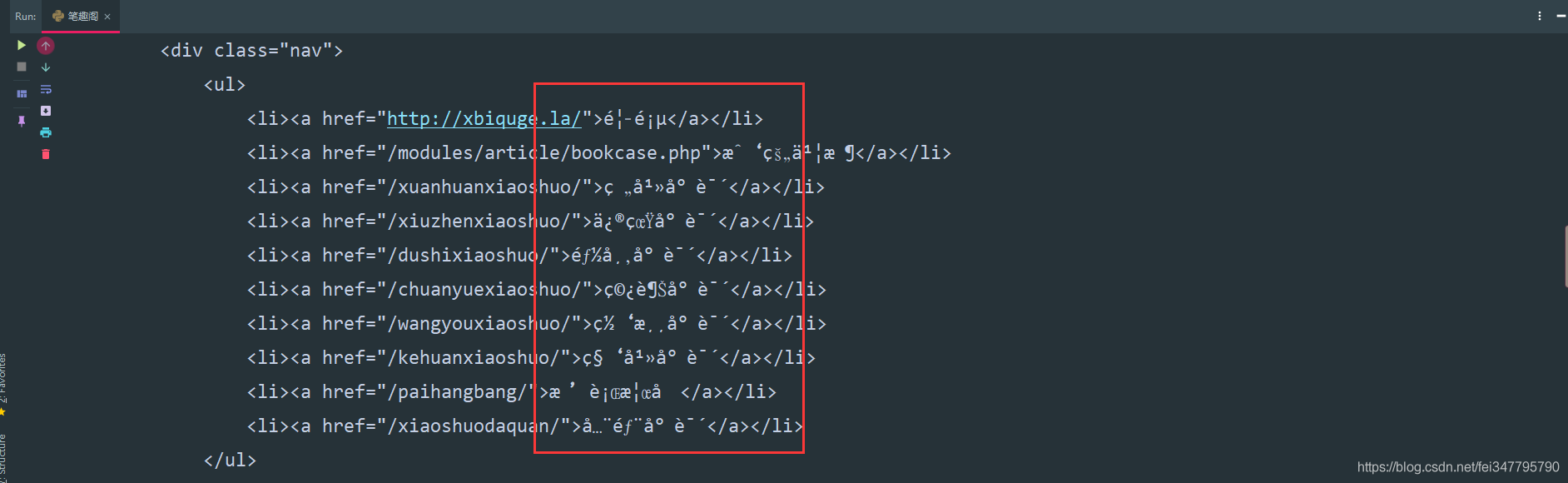
请求网页返回的数据中出现了乱码,这就需要我们转码了。
加一行代码自动转码。
response.encoding = response.apparent_encoding
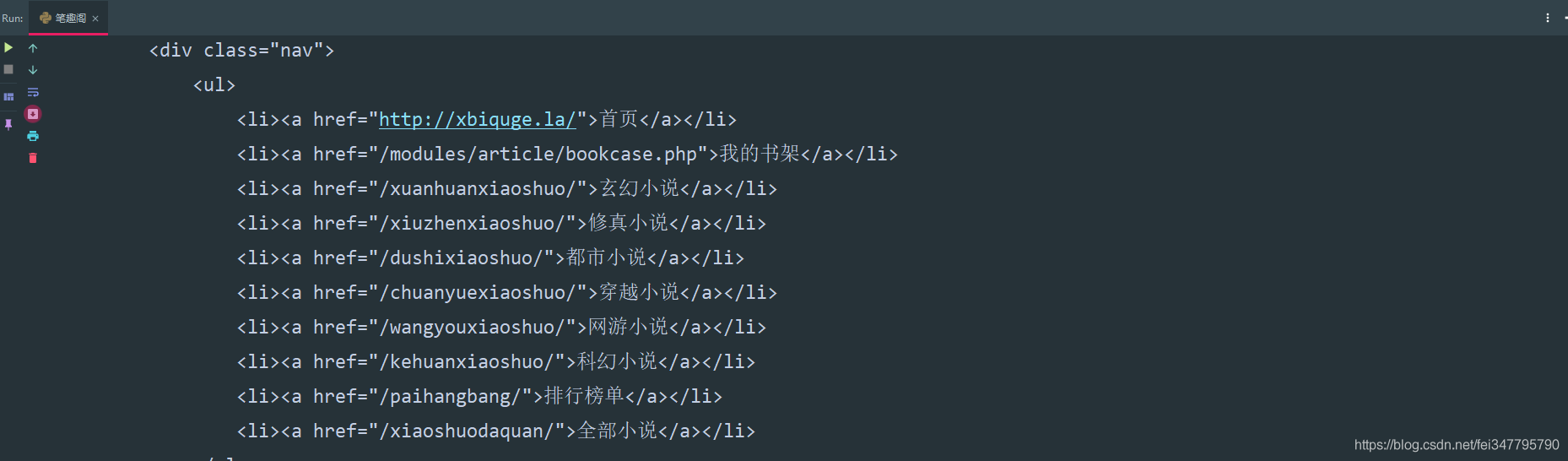
三、解析数据
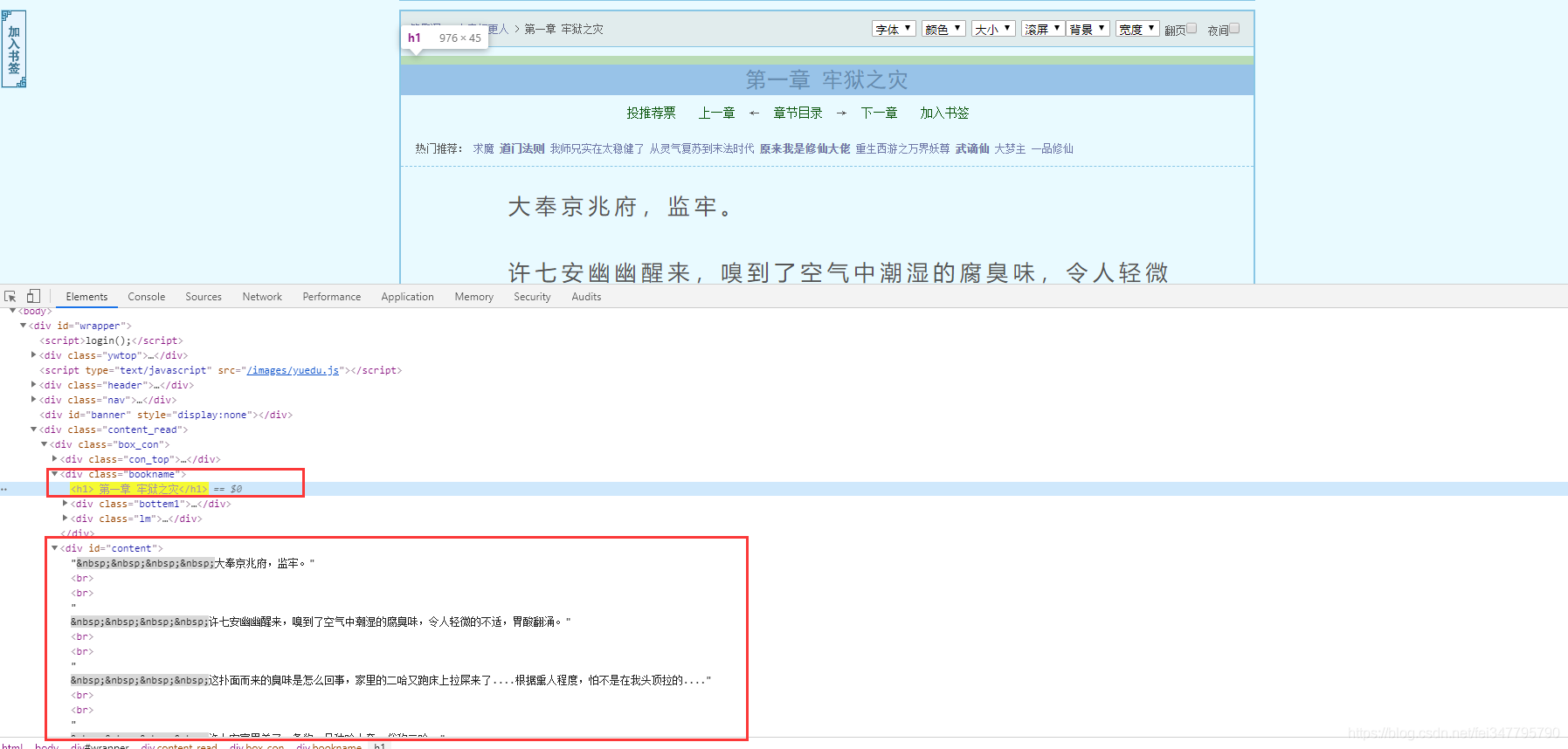
根据css选择器可以直接提取小说标题以及小说内容。
def get_one_novel(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 获取小说标题
title = selector.css('.bookname h1::text').get()
# 获取小说内容 返回的是list
content_list = selector.css('#content::text').getall()
# ''.join(列表) 把列表转换成字符串
content_str = ''.join(content_list)
print(title, content_str)
if __name__ == '__main__':
url = 'http://www.biquges.com/52_52642/25585323.html'
get_one_novel(url)
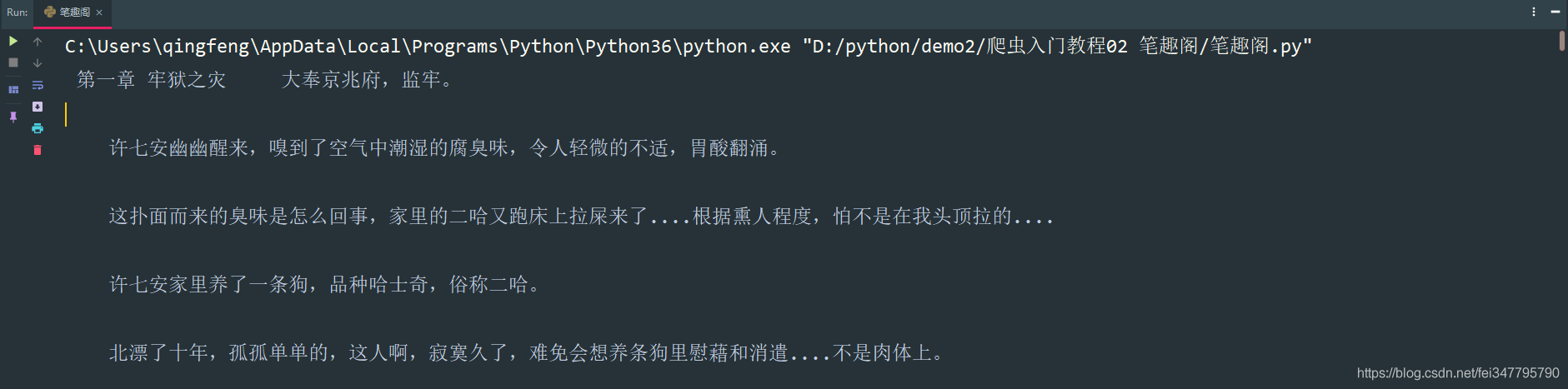
四、保存数据(数据持久化)
使用常用的保存方式: with open
def save(title, content):
"""
保存小说
:param title: 小说章节标题
:param content: 小说内容
:return:
"""
# 路径
filename = f'{title}\\'
# os 内置模块,自动创建文件夹
if os.makedirs(filename):
os.mkdir()
# 一定要记得加后缀 .txt mode 保存方式 a 是追加保存 encoding 保存编码
with open(filename + title + '.txt', mode='a', encoding='utf-8') as f:
# 写入标题
f.write(title)
# 换行
f.write('\n')
# 写入小说内容
f.write(content)

保存一章小说,就这样写完了,如果想要保存整本小说呢?
整本小说爬虫
既然爬取单章小说知道怎么爬取了,那么只需要获取小说所有单章小说的url地址,就可以爬取全部小说内容了。
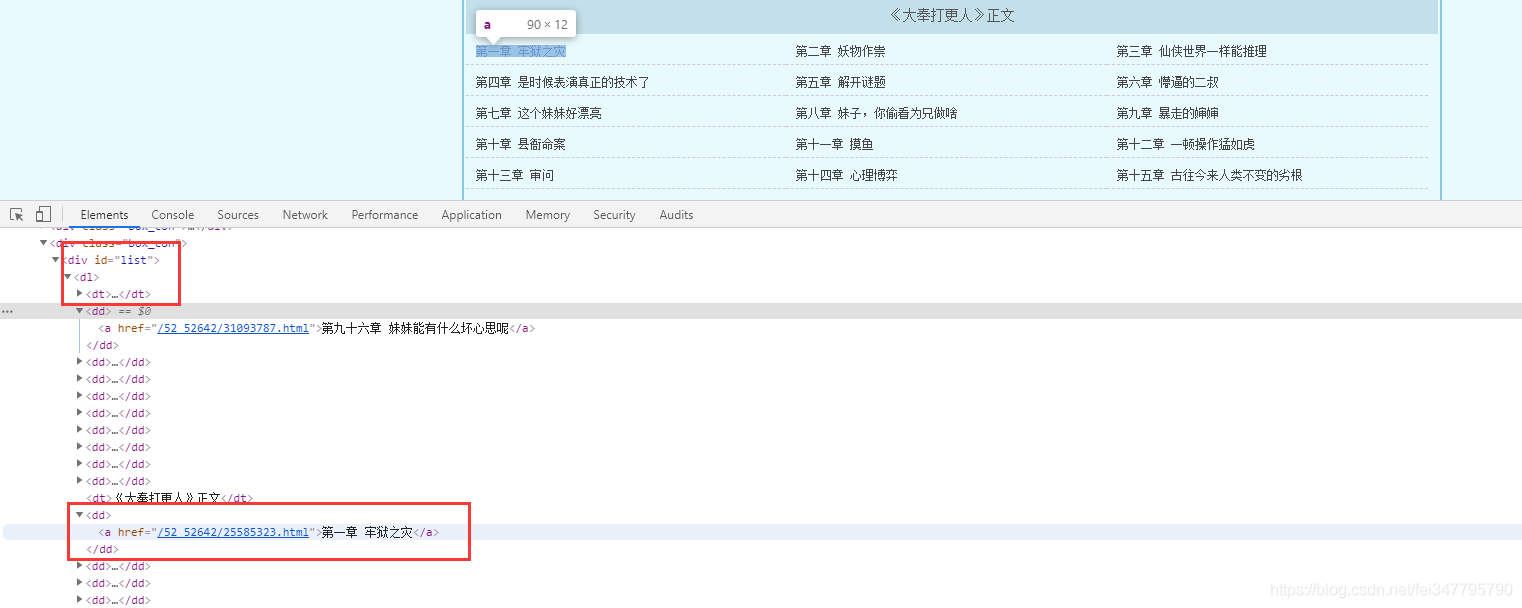
所有的单章的url地址都在 dd 标签当中,但是这个url地址是不完整的,所以爬取下来的时候,要拼接url地址。
def get_all_url(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 所有的url地址都在 a 标签里面的 href 属性中
dds = selector.css('#list dd a::attr(href)').getall()
for dd in dds:
novel_url = 'http://www.biquges.com' + dd
print(novel_url)
if __name__ == '__main__':
url = 'http://www.biquges.com/52_52642/index.html'
get_all_url(url)
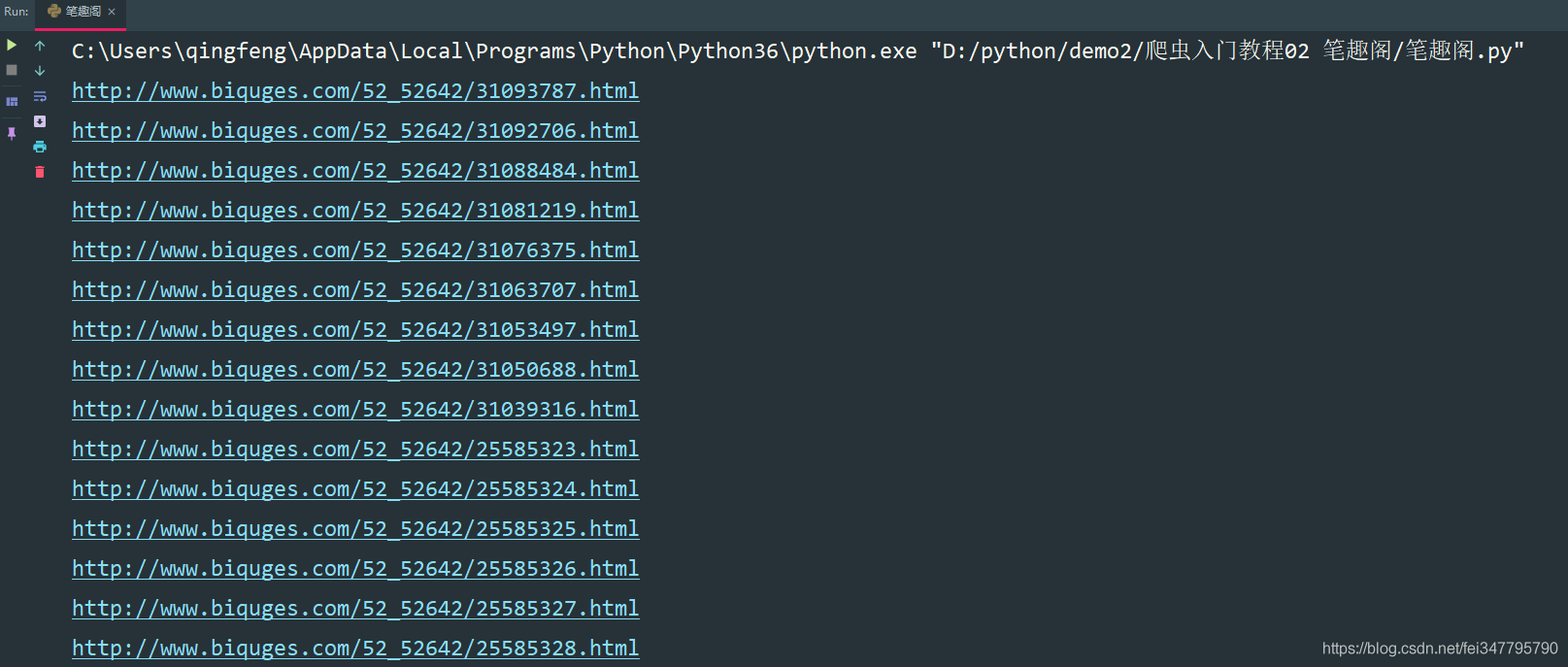
这样就获取了所有的小说章节url地址了。
爬取全本完整代码
import requests
import parsel
from tqdm import tqdm
def get_response(html_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
response.encoding = response.apparent_encoding
return response
def save(novel_name, title, content):
"""
保存小说
:param title: 小说章节标题
:param content: 小说内容
:return:
"""
filename = f'{novel_name}' + '.txt'
# 一定要记得加后缀 .txt mode 保存方式 a 是追加保存 encoding 保存编码
with open(filename, mode='a', encoding='utf-8') as f:
# 写入标题
f.write(title)
# 换行
f.write('\n')
# 写入小说内容
f.write(content)
def get_one_novel(name, novel_url):
# 调用请求网页数据函数
response = get_response(novel_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 获取小说标题
title = selector.css('.bookname h1::text').get()
# 获取小说内容 返回的是list
content_list = selector.css('#content::text').getall()
# ''.join(列表) 把列表转换成字符串
content_str = ''.join(content_list)
save(name, title, content_str)
def get_all_url(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 所有的url地址都在 a 标签里面的 href 属性中
dds = selector.css('#list dd a::attr(href)').getall()
# 小说名字
novel_name = selector.css('#info h1::text').get()
for dd in tqdm(dds):
novel_url = 'http://www.biquges.com' + dd
get_one_novel(novel_name, novel_url)
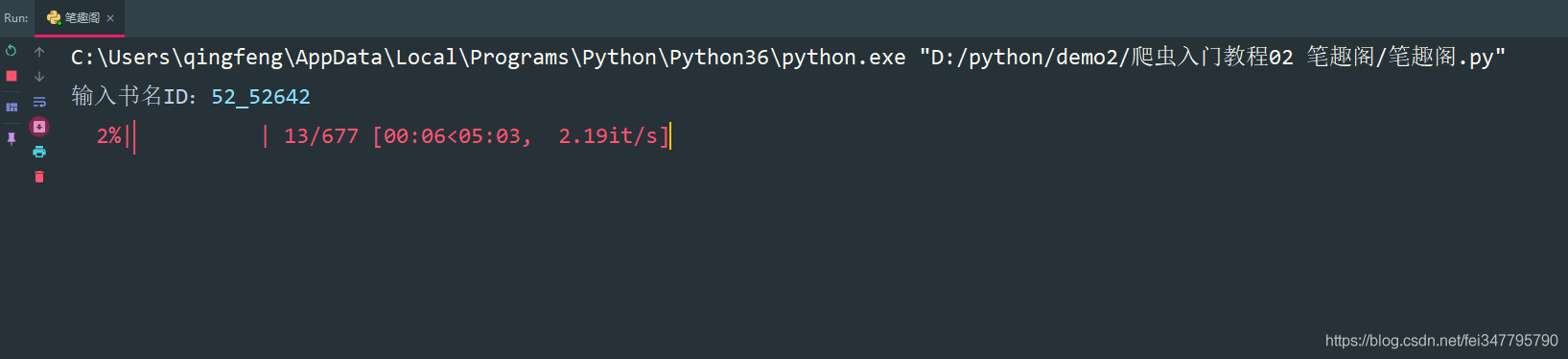
if __name__ == '__main__':
novel_id = input('输入书名ID:')
url = f'http://www.biquges.com/{novel_id}/index.html'
get_all_url(url)
到此这篇关于Python爬虫入门教程02之笔趣阁小说爬取的文章就介绍到这了,更多相关Python爬虫笔趣阁小说爬取内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫入门教程01之爬取豆瓣Top电影
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 基本开发环境 Python 3.6 Pycharm 相关模块的使用 requests parsel csv 安装Python并添加到环境变量,pip安装需要的相关模块即可. 爬虫基本思路 一.明确需求 爬取豆瓣Top250排行电影信息 电影名字 导演.主演 年份.国家.类型 评分.评价人数 电影简介 二.发送请求 Python中的大量开源的模块使得编码变的特别简单,我们写爬虫第一个要了解的模
-
Python爬虫自动化获取华图和粉笔网站的错题(推荐)
这篇博客对于考公人或者其他用华图或者粉笔做题的人比较友好,通过输入网址可以自动化获取华图以及粉笔练习的错题. 粉笔网站 我们从做过的题目组中获取错题 打开某一次做题组,我们首先进行抓包看看数据在哪里 我们发现现在数据已经被隐藏,事实上数据在这两个包中: https://tiku.fenbi.com/api/xingce/questions https://tiku.fenbi.com/api/xingce/solutions 一个为题目的一个为解析的.此url要通过传入一个题目组参数才能获取到当
-
python爬虫基础之urllib的使用
一.urllib 和 urllib2的关系 在python2中,主要使用urllib和urllib2,而python3对urllib和urllib2进行了重构,拆分成了urllib.request, urllib.parse, urllib.error,urllib.robotparser等几个子模块,这样的架构从逻辑和结构上说更加合理.urllib库无需安装,python3自带.python 3.x中将urllib库和urilib2库合并成了urllib库. urllib2.urlopen()
-
Python爬虫之Selenium库的使用方法
Selenium 是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等.这个工具的主要功能包括:测试与浏览器的兼容性--测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上.测试系统功能--创建回归测试检验软件功能和用户需求.支持自动录制动作和自动生成 .Net.Java.Perl等不同语言的测试
-
python基于爬虫+django,打造个性化API接口
简述 今天也是同事在做微信小程序的开发,需要音乐接口的测试,可是用网易云的开放接口比较麻烦,也不能进行测试,这里也是和我说了一下,所以就用爬虫写了个简单网易云歌曲URL的爬虫,把数据存入mysql数据库,再利用django封装装了一个简单的API接口,给同事测试使用. 原理 创建django项目,做好基础的配置,在views里写两个方法,一个是从mysql数据库中查数据然后封装成API,一个是爬虫方法,数据扒下来以后,通过django的ORM把数据插入到mysql数据库中. 这里的路由也是对应两
-
Python爬虫入门教程02之笔趣阁小说爬取
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 前文 01.python爬虫入门教程01:豆瓣Top电影爬取 基本开发环境 Python 3.6 Pycharm 相关模块的使用 request sparsel 安装Python并添加到环境变量,pip安装需要的相关模块即可. 单章爬取 一.明确需求 爬取小说内容保存到本地 小说名字 小说章节名字 小说内容 # 第一章小说url地址 url = 'http://www.biquges.co
-
python爬虫入门教程--优雅的HTTP库requests(二)
前言 urllib.urllib2.urllib3.httplib.httplib2 都是和 HTTP 相关的 Python 模块,看名字就觉得很反人类,更糟糕的是这些模块在 Python2 与 Python3 中有很大的差异,如果业务代码要同时兼容 2 和 3,写起来会让人崩溃. 好在,还有一个非常惊艳的 HTTP 库叫 requests,它是 GitHUb 关注数最多的 Python 项目之一,requests 的作者是 Kenneth Reitz 大神. requests 实现了 HTTP
-
python爬虫之爬取笔趣阁小说
前言 为了上班摸鱼方便,今天自己写了个爬取笔趣阁小说的程序.好吧,其实就是找个目的学习python,分享一下. 一.首先导入相关的模块 import os import requests from bs4 import BeautifulSoup 二.向网站发送请求并获取网站数据 网站链接最后的一位数字为一本书的id值,一个数字对应一本小说,我们以id为1的小说为示例. 进入到网站之后,我们发现有一个章节列表,那么我们首先完成对小说列表名称的抓取 # 声明请求头 headers = { 'Use
-
python爬虫之爬取笔趣阁小说升级版
python爬虫高效爬取某趣阁小说 这次的代码是根据我之前的 笔趣阁爬取 的基础上修改的,因为使用的是自己的ip,所以在请求每个章节的时候需要设置sleep(4~5)才不会被封ip,那么在计算保存的时间,每个章节会花费6-7秒,如果爬取一部较长的小说时,时间会特别的长,所以这次我使用了代理ip.这样就可以不需要设置睡眠时间,直接大量访问. 一,获取免费ip 关于免费ip,我选择的是站大爷.因为免费ip的寿命很短,所以尽量要使用实时的ip,这里我专门使用getip.py来获取免费ip,代码会爬取最
-
Python爬虫实例_城市公交网络站点数据的爬取方法
爬取的站点:http://beijing.8684.cn/ (1)环境配置,直接上代码: # -*- coding: utf-8 -*- import requests ##导入requests from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup import os headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,
-
python爬虫入门教程--正则表达式完全指南(五)
前言 正则表达式处理文本有如疾风扫秋叶,绝大部分编程语言都内置支持正则表达式,它应用在诸如表单验证.文本提取.替换等场景.爬虫系统更是离不开正则表达式,用好正则表达式往往能收到事半功倍的效果. 介绍正则表达式前,先来看一个问题,下面这段文本来自豆瓣的某个网页链接,我对内容进行了缩减.问:如何提取文本中所有邮箱地址呢? html = """ <style> .qrcode-app{ display: block; background: url(/pics/qrco
-
python爬虫入门教程--HTML文本的解析库BeautifulSoup(四)
前言 python爬虫系列文章的第3篇介绍了网络请求库神器 Requests ,请求把数据返回来之后就要提取目标数据,不同的网站返回的内容通常有多种不同的格式,一种是 json 格式,这类数据对开发者来说最友好.另一种 XML 格式的,还有一种最常见格式的是 HTML 文档,今天就来讲讲如何从 HTML 中提取出感兴趣的数据 自己写个 HTML 解析器来解析吗?还是用正则表达式?这些都不是最好的办法,好在,Python 社区在这方便早就有了很成熟的方案,BeautifulSoup 就是这一类问题
-
python爬虫入门教程之点点美女图片爬虫代码分享
继续鼓捣爬虫,今天贴出一个代码,爬取点点网「美女」标签下的图片,原图. # -*- coding: utf-8 -*- #--------------------------------------- # 程序:点点美女图片爬虫 # 版本:0.2 # 作者:zippera # 日期:2013-07-26 # 语言:Python 2.7 # 说明:能设置下载的页数 #--------------------------------------- import urllib2 import urll
-
python爬虫入门教程--快速理解HTTP协议(一)
前言 爬虫的基本原理是模拟浏览器进行 HTTP 请求,理解 HTTP 协议是写爬虫的必备基础,招聘网站的爬虫岗位也赫然写着熟练掌握HTTP协议规范,写爬虫还不得不先从HTTP协议开始讲起 HTTP协议是什么? 你浏览的每一个网页都是基于 HTTP 协议呈现的,HTTP 协议是互联网应用中,客户端(浏览器)与服务器之间进行数据通信的一种协议.协议中规定了客户端应该按照什么格式给服务器发送请求,同时也约定了服务端返回的响应结果应该是什么格式. 只要大家都按照协议规定方式发起请求和返回响应结果,任何人