Python pandas删除指定行/列数据的方法实例
目录
- 1.滤除缺失数据dropna()
- 1)滤除含有NaN值的所有行
- 2)滤除含有NaN值的所有列
- 3)滤除元素都是NaN值的行
- 4)滤除元素都是NaN值的列
- 5)滤除指定列中含有缺失的行
- 2.删除重复值 drop_duplicates()
- 1)keep=“first”
- 2)keep=“last”
- 3)keep=False
- 4)删除指定列中重复项对应的行
- 3.根据指定条件删除行列drop()
- 1).删除指定列
- 2).删除指定行
- 总结
1.滤除缺失数据dropna()
import pandas as pd
import numpy as np
df=pd.DataFrame({"record":[np.nan,"亚健康|潘光|45岁","疾病|张思",np.nan],"date":[np.nan,20210102,20210103,20210104]},index=["one","two","three","four"])

1)滤除含有NaN值的所有行
df.dropna()#默认axis=0

2)滤除含有NaN值的所有列
df.dropna(axis=1)

3)滤除元素都是NaN值的行
df.dropna(axis=0,how="all")

4)滤除元素都是NaN值的列

5)滤除指定列中含有缺失的行
df.dropna(subset=["record"],axis=0)

以上如果需要在原数据上直接做更改,需设置参数inplace=True
2.删除重复值 drop_duplicates()
df=pd.DataFrame({'state':[1,1,2,2,1,2,2],'pop':['a','b','c','d','b','c','d']})

语法:drop_duplicates(subset,keep,inplace),其中参数 keep:{‘first’,‘last’,False},默认’first’
first:保留第一次出现的重复项,删除第二次及之后出现的重复项。
last:保留最后一次出现的重复项,删除之前出现的重复项。
"false":删除所有重复项。
1)keep=“first”
df.drop_duplicates(keep="first")

2)keep=“last”
df.drop_duplicates(keep="last")
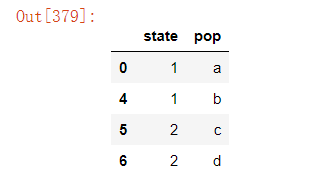
3)keep=False
df.drop_duplicates(keep=False)
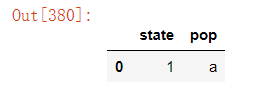
4)删除指定列中重复项对应的行
df.drop_duplicates(subset=["state"],keep="first")
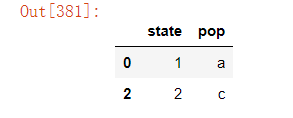
以上如果需要在原数据上直接做更改,需设置参数inplace=True
3.根据指定条件删除行列drop()
df=pd.DataFrame(np.arange(16).reshape(4,4),columns=["one","two","three","four"])
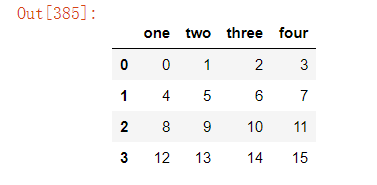
1).删除指定列
df.drop(["one"],axis=1)

另外,也可通过del df["one"]来实现删除指定列,但该方法不推荐,因为这默认直接在源数据上做更改。
2).删除指定行
df.drop([0],axis=0)
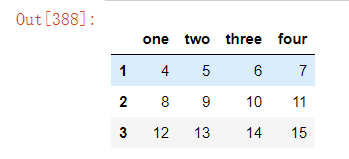
以上如果需要在原数据上直接做更改,需设置参数inplace=True
总结
到此这篇关于Python pandas删除指定行/列数据的文章就介绍到这了,更多相关python pandas删除指定行/列内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

pandas删除指定行详解
在处理pandas的DataFrame中,如果想像excel那样筛选,只要其中的某一行或者几行,可以使用isin()方法来实现,只需要将需要的行值以列表方式传入即可,还可传入字典,进行指定筛选. pandas.DataFrame中删除包涵特定字符串所在的行:https://www.jb51.net/article/159052.htm 以上所述是小编给大家介绍的pandas删除指定行详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支
-
pandas删除行删除列增加行增加列的实现
创建df: >>> df = pd.DataFrame(np.arange(16).reshape(4, 4), columns=list('ABCD'), index=list('1234')) >>> df A B C D 1 0 1 2 3 2 4 5 6 7 3 8 9 10 11 4 12 13 14 15 1,删除行 1.1,drop 通过行名称删除: df = df.drop(['1', '2']) # 不指定axis默认为0 df.drop(['1',
-
pandas DataFrame行或列的删除方法的实现示例
此文我们继续围绕DataFrame介绍相关操作. 平时在用DataFrame时候,删除操作用的不太多,基本是从源DataFrame中筛选数据,组成一个新的DataFrame再继续操作. 1. 删除DataFrame某一列 这里我们继续用上一节产生的DataFrame来做例子,原DataFrame如下: 我们使用drop()函数,此函数有一个列表形参labels,写的时候可以加上labels=[xxx],也可以不加,列表内罗列要删除行或者列的名称,默认是行名称,如果要删除列,则要增加参数axis=
-
pandas.DataFrame删除/选取含有特定数值的行或列实例
1.删除/选取某列含有特殊数值的行 import pandas as pd import numpy as np a=np.array([[1,2,3],[4,5,6],[7,8,9]]) df1=pd.DataFrame(a,index=['row0','row1','row2'],columns=list('ABC')) print(df1) df2=df1.copy() #删除/选取某列含有特定数值的行 #df1=df1[df1['A'].isin([1])] #df1[df1['A'].
-
Python pandas删除指定行/列数据的方法实例
目录 1.滤除缺失数据dropna() 1)滤除含有NaN值的所有行 2)滤除含有NaN值的所有列 3)滤除元素都是NaN值的行 4)滤除元素都是NaN值的列 5)滤除指定列中含有缺失的行 2.删除重复值 drop_duplicates() 1)keep=“first” 2)keep=“last” 3)keep=False 4)删除指定列中重复项对应的行 3.根据指定条件删除行列drop() 1).删除指定列 2).删除指定行 总结 1.滤除缺失数据dropna() import pandas
-
Pandas:Series和DataFrame删除指定轴上数据的方法
如下所示: import numpy as np import pandas as pd from pandas import Series,DataFrame 一.drop方法:产生新对象 1.Series o = Series([1,3,4,7],index=['d','c','b','a']) print(o.drop(['d','b'])) c 3 a 7 dtype: int64 2.DataFrame data = {'水果':['苹果','梨','草莓'], '数量':[3,2,5
-
Sql Server数据把列根据指定内容拆分数据的方法实例
今天由于工作需要,需要把数据把列根据指定的内容拆分数据 其中一条数据实例 select id , XXXX FROM BIZ_PAPER where id ='4af210ec675927fa016772bf7dd025b0' 拆分方法: select t3.id ,t3.XXXX as XXXX from ( select A.id , B.XXXX from ( SELECT id, XXXX = CONVERT(xml,'<root><v>' + REPLACE(XXXX
-
python+pandas生成指定日期和重采样的方法
python 日期的范围.频率.重采样以及频率转换 pandas有一整套的标准时间序列频率以及用于重采样.频率推断.生成固定频率日期范围的工具. 生成指定日期范围的范围 pandas.date_range()用于生成指定长度的DatatimeIndex: 1)默认情况下,date_range会按着时间间隔为天的方式生成从给定开始到结束时间的时间戳数组: 2)如果只指定开始或结束时间,还需要periods标定时间长度. import pandas as pd pd.date_range('2017
-
python pandas获取csv指定行 列的操作方法
pandas获取csv指定行,列 house_info = pd.read_csv('house_info.csv') 1:取行的操作: house_info.loc[3:6]类似于python的切片操作 2:取列操作: house_info['price'] 这是读取csv文件时默认的第一行索引 3:取两列 house_info[['price',tradetypename']] 取多个列也是同理的,注意里面是一个list的列表,不然会报错误: 4:增加列: house_Info['adre
-
pandas删除某行或某列数据的实现示例
目录 1.drop()函数 2.del函数 首先,创建一个DataFrame格式数据作为举例数据. # 创建一个DataFrame格式数据 data = {'a': ['a0', 'a1', 'a2'], 'b': ['b0', 'b1', 'b2'], 'c': [i for i in range(3)], 'd': 4} df = pd.DataFrame(data) print('举例数据情况:\n', df) 注:DataFrame是最常用的pandas对象,使用pandas读取数据文件
-
Pandas.DataFrame删除指定行和列(drop)的实现
目录 DataFrame指定的行删除 按行名指定(行标签) 按行号指定 未设置行名的注意事项 DataFrame指定的列删除 按列名指定(列标签) 按列号指定 多行多列的删除 使用drop()方法删除pandas.DataFrame的行和列. 在0.21.0版之前,请使用参数labels和axis指定行和列.从0.21.0开始,可以使用index或columns. 在此,将对以下内容进行说明. DataFrame指定的行删除 按行名指定(行标签) 按行号指定 未设置行名的注意事项 DataFra
-
Python pandas替换指定数据的方法实例
目录 一.构造dataframe 二.替换指定数据(fillna.isin.replace) 1.用"sz"列的同行数据将"bj"列的空值替换掉 2.在1的基础上,将"sz"列为2或者6的数据替换成-4 三.替换函数replace()详解 1.全局替换元素 2.通过指定条件替换元素 3.通过模糊条件替换指定元素 总结 一.构造dataframe import pandas as pd import numpy as np df=pd.DataFr
-
Python Pandas删除替换并提取其中的缺失值NaN(dropna,fillna,isnull)
目录 前言 Pandas中缺少值NaN的介绍 将缺失值作为Pandas中的缺少值NaN 缺少值NaN的删除方法 删除所有值均缺失的行/列 删除至少包含一个缺失值的行/列 根据不缺少值的元素数量删除行/列 删除特定行/列中缺少值的列/行 pandas.Series 替换(填充)缺失值 用通用值统一替换 为每列替换不同的值 用每列的平均值,中位数,众数等替换 替换为上一个或下一个值 指定连续更换的最大数量 pandas.Series 提取缺失值 提取特定行/列中缺少值的列/行 提取至少包含一个缺失值