Python pandas之多级索引取值详解
目录
- 数据需求
- 需求拆解
- 需求处理
- 方法一
- 方法二
- 总结
最近发现周围的很多小伙伴们都不太乐意使用pandas,转而投向其他的数据操作库,身为一个数据工作者,基本上是张口pandas,闭口pandas了,故而写下此系列以让更多的小伙伴们爱上pandas。
平台:
windows 10
python 3.8
pandas 1.2.4
数据需求
给定一份多级索引数据,查找指定值。

需求拆解
数据提取在pandas中,或者说在python中就是索引式提取,在单层索引中采用.loc或.iloc方法已经非常常见了,然而在索引层次多了之后却有点不知所措,也只需要将各个索引看成整体进行提取就行。
需求处理
方法一
这里先给出一个比较笨拙的方法,先将索引进行重置为列数据,通过列取得bool条件再进行提取
datac.reset_index(inplace=True) datac[(datac['School'] == 'S_2') & (datac['Class'] == 'C_3')]
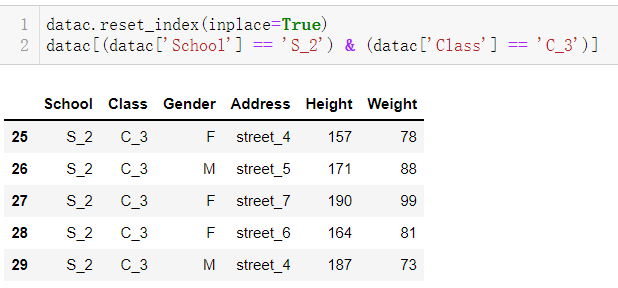
可以看到通过该类方法可以成功取到对应值
当然也可以采用.query方法进行条件筛选
datac.reset_index(inplace=True)
datac.query("School == 'S_1' and Class == 'C_3'")

方法二
既然为多级索引,pandas也会有对应的取值方式,既可以用链式调用的方式,也可以通过元组进行提取,首先看看多级索引的输出值:

是一个MultiIndex类型数据,其元素都是元组,即也能通过元组的方式进行索引调取
这两种都一个共同的特点,从左到右,要先外层再内层,否则会报KeyError错误
# 链式调用 datac.loc['S_1'].loc['C_1']

# 元组作为索引调用
datac.loc[('S_3', 'C_1'), :]

tips:
1.多层索引,即列名上方有层次结构也可以按这种方式进行提取。
2.想越过外层索引提取内层索引需要交换索引顺序才能顺利提取。
# swaplevel 交换索引层级
datac.swaplevel(axis=0).loc[('C_1')] # axis=0: index

总结
功夫再高,也怕菜刀。本例使用方法比较常规,旨在巩固基础知识,当下次遇到能够想起可以直接索引取值而不用将索引重置为列值,以高效完成数据提取任务。
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
python pandas中索引函数loc和iloc的区别分析
目录 前言 1.直接使用行或者列标签 2.loc函数 3.iloc函数 总结 前言 使用pandas进行数据分析的时候,我们经常需要对DataFrame的行或者列进行索引.使用pandas进行索引的方法主要有三种:直接使用行或者列标签.loc函数和iloc函数. 举个简单的例子: import numpy as np import pandas as pd df = pd.DataFrame({"Fruits":["apple","pear",&
-
python中pandas.DataFrame的简单操作方法(创建、索引、增添与删除)
前言 最近在网上搜了许多关于pandas.DataFrame的操作说明,都是一些基础的操作,但是这些操作组合起来还是比较费时间去正确操作DataFrame,花了我挺长时间去调整BUG的.我在这里做一些总结,方便你我他.感兴趣的朋友们一起来看看吧. 一.创建DataFrame的简单操作: 1.根据字典创造: In [1]: import pandas as pd In [3]: aa={'one':[1,2,3],'two':[2,3,4],'three':[3,4,5]} In [4]: bb=
-

Python Pandas 获取列匹配特定值的行的索引问题
给定一个带有列"BoolCol"的DataFrame,如何找到满足条件"BoolCol" == True的DataFrame的索引 目前有迭代的方式来做到这一点: for i in range(100,3000): if df.iloc[i]['BoolCol']== True: print i,df.iloc[i]['BoolCol'] 这虽然可行,但不是标准的 Pandas 方式.经过一番研究,我目前正在使用这个代码: df[df['BoolCol'] == T
-
Python 中pandas索引切片读取数据缺失数据处理问题
引入 numpy已经能够帮助我们处理数据,能够结合matplotlib解决我们数据分析的问题,那么pandas学习的目的在什么地方呢? numpy能够帮我们处理处理数值型数据,但是这还不够 很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等 比如:我们通过爬虫获取到了存储在数据库中的数据 比如:之前youtube的例子中除了数值之外还有国家的信息,视频的分类(tag)信息,标题信息等 所以,numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我
-
浅谈python已知元素,获取元素索引(numpy,pandas)
目前搜索到的方法有: np.where('元素') 还有就是pandas的方法: df.index('元素') 但是第二个方法的问题就是会报错,嗯,这就比较尴尬了,查询了网上的解决方案,有这样的: 此外使用 df[df['列名'].isin([相应的值])] 这个命令会输出等于该值的行. 此外如果想快速找到dataframe最后几行的话,可以使用的方法是tail,可以获取若干行的值 以上这篇浅谈python已知元素,获取元素索引(numpy,pandas)就是小编分享给大家的全部内容了,希望能给
-
Python3.5 Pandas模块缺失值处理和层次索引实例详解
本文实例讲述了Python3.5 Pandas模块缺失值处理和层次索引.分享给大家供大家参考,具体如下: 1.pandas缺失值处理 import numpy as np import pandas as pd from pandas import Series,DataFrame df3 = DataFrame([ ["Tom",np.nan,456.67,"M"], ["Merry",34,345.56,np.nan], [np.nan,np
-
Python pandas之多级索引取值详解
目录 数据需求 需求拆解 需求处理 方法一 方法二 总结 最近发现周围的很多小伙伴们都不太乐意使用pandas,转而投向其他的数据操作库,身为一个数据工作者,基本上是张口pandas,闭口pandas了,故而写下此系列以让更多的小伙伴们爱上pandas. 平台: windows 10 python 3.8 pandas 1.2.4 数据需求 给定一份多级索引数据,查找指定值. 需求拆解 数据提取在pandas中,或者说在python中就是索引式提取,在单层索引中采用.loc或.iloc方法已经非
-
Python Pandas学习之series的二元运算详解
目录 二元运算 series 的二元运算 series 上的二元运算方法 二元运算 二元运算是指由两个元素形成第三个元素的一种规则,例如数的加法及乘法;更一般地,由两个集合形成第三个集合的产生方法或构成规则称为二次运算. 二元运算(Binary operation)作用于两个对象的运算.如任意二数相加或相乘而得另一数:任意二集合相交或相并而得另一集合:任意一个多行矩阵与一个多列矩阵相乘而得另一矩阵:任意二函数合成而为另一函数,以上加.乘.交.并,积及合成均属二元运算 . series 的二元运
-
对python pandas 画移动平均线的方法详解
数据文件 66001_.txt 内容格式: date,jz0,jz1,jz2,jz3,jz4,jz5 2012-12-28,0.9326,0.8835,1.0289,1.0027,1.1067,1.0023 2012-12-31,0.9435,0.8945,1.0435,1.0031,1.1229,1.0027 2013-01-04,0.9403,0.8898,1.0385,1.0032,1.1183,1.0030 ... ... pd_roll_mean1.py # -*- coding: u
-
微信小程序:数据存储、传值、取值详解
小程序界面传值 父级界面:A界面 子级界面:B界面 一.url传值 详细的配置参数可以查看组件导航:navigator,这里不再做过多的解释. 1. 正向传值:A界面 –>B界面 用 navigator标签或 wx.navigator传值,A界面向B界面传id值 A界面获取id值传向B界面如果需要传多个参数, 用 & 链接即可 // 方法一:navigator标签传值 <navigator url="/page/index/index?id=110" >传值&
-
对python pandas读取剪贴板内容的方法详解
我使用的Python3.5,32版本win764位系统,pandas0.19版本,使用df=pd.read_clipboard()的时候读不到数据,百度查找解决方法,找到了一个比较靠谱的 打开site-packages\pandas\io\clipboard.py 在 text = clipboard_get() 后面一行 加入这句: text = text.decode('UTF-8') 保存,然后就可以使用了 df=pd.read_clipboard() #变成正常的了 下次可以在其他地方复
-
python pandas修改列属性的方法详解
使用astype如下: df[[column]] = df[[column]].astype(type) type即int.float等类型. 示例: import pandas as pd data = pd.DataFrame([[1, "2"], [2, "2"]]) data.columns = ["one", "two"] print(data) # 当前类型 print("----\n修改前类型:&quo
-
python基础知识之索引与切片详解
目录 基本索引 嵌套索引 切片 numpy.array 索引 一维 numpy.array 索引 二维 pandas Series 索引 pandas DataFrame 索引 填坑 总结 基本索引 In [4]: sentence = 'You are a nice girl'In [5]: L = sentence.split()In [6]: LOut[6]: ['You', 'are', 'a', 'nice', 'girl'] # 从0开始索引In [7]: L[2]Out[7]: '
-
Python Pandas数据合并pd.merge用法详解
目录 前言 语法 参数 1.连接键 2.索引连接 3.多连接键 4.连接方法 5.连接指示 总结 前言 实现类似SQL的join操作,通过pd.merge()方法可以自由灵活地操作各种逻辑的数据连接.合并等操作 可以将两个DataFrame或Series合并,最终返回一个合并后的DataFrame 语法 pd.merge(left, right, how = 'inner', on = None, left_on = None, right_on = None, left_index = Fal
-
微信小程序数据存储与取值详解
在小程序开发的过程,经常要需要这个页面输入的数据,在下一个页面中进行取值赋值. 比如: 在A页面input输入框,输入电话号码,点击添加.需要在B页面电话区域中,显示刚刚输入的电话号码. 因为这是两个页面,就需要先存储,再取值.微信小程序提供了数据存储的API,wx.setStorage(OBJECT) 可以将数据存储在本地缓存中指定的 key 中,如果重复会覆盖掉原来该 key 对应的内容. 思路是,在A页面,使用bindinput获取input输入的值,赋值给一个变量(自定义),点击添加按钮
-
Python 马氏距离求取函数详解
马氏距离区别于欧式距离,如百度知道中所言: 马氏距离(Mahalanobis distance)是由印度统计学家马哈拉诺比斯(P. C. Mahalanobis)提出的,表示点与一个分布之间的距离.它是一种有效的计算两个未知样本集的相似度的方法.与 欧氏距离不同的是,它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的),并且是尺度无关的(scale-invariant),即独立于测量尺度.对于一个均值为μ, 协方差矩阵为Σ的多变量向量,其马氏距离为s