python使用梯度下降算法实现一个多线性回归
python使用梯度下降算法实现一个多线性回归,供大家参考,具体内容如下
图示:


import pandas as pd
import matplotlib.pylab as plt
import numpy as np
# Read data from csv
pga = pd.read_csv("D:\python3\data\Test.csv")
# Normalize the data 归一化值 (x - mean) / (std)
pga.AT = (pga.AT - pga.AT.mean()) / pga.AT.std()
pga.V = (pga.V - pga.V.mean()) / pga.V.std()
pga.AP = (pga.AP - pga.AP.mean()) / pga.AP.std()
pga.RH = (pga.RH - pga.RH.mean()) / pga.RH.std()
pga.PE = (pga.PE - pga.PE.mean()) / pga.PE.std()
def cost(theta0, theta1, theta2, theta3, theta4, x1, x2, x3, x4, y):
# Initialize cost
J = 0
# The number of observations
m = len(x1)
# Loop through each observation
# 通过每次观察进行循环
for i in range(m):
# Compute the hypothesis
# 计算假设
h=theta0+x1[i]*theta1+x2[i]*theta2+x3[i]*theta3+x4[i]*theta4
# Add to cost
J += (h - y[i])**2
# Average and normalize cost
J /= (2*m)
return J
# The cost for theta0=0 and theta1=1
def partial_cost_theta4(theta0,theta1,theta2,theta3,theta4,x1,x2,x3,x4,y):
h = theta0 + x1 * theta1 + x2 * theta2 + x3 * theta3 + x4 * theta4
diff = (h - y) * x4
partial = diff.sum() / (x2.shape[0])
return partial
def partial_cost_theta3(theta0,theta1,theta2,theta3,theta4,x1,x2,x3,x4,y):
h = theta0 + x1 * theta1 + x2 * theta2 + x3 * theta3 + x4 * theta4
diff = (h - y) * x3
partial = diff.sum() / (x2.shape[0])
return partial
def partial_cost_theta2(theta0,theta1,theta2,theta3,theta4,x1,x2,x3,x4,y):
h = theta0 + x1 * theta1 + x2 * theta2 + x3 * theta3 + x4 * theta4
diff = (h - y) * x2
partial = diff.sum() / (x2.shape[0])
return partial
def partial_cost_theta1(theta0,theta1,theta2,theta3,theta4,x1,x2,x3,x4,y):
h = theta0 + x1 * theta1 + x2 * theta2 + x3 * theta3 + x4 * theta4
diff = (h - y) * x1
partial = diff.sum() / (x2.shape[0])
return partial
# 对theta0 进行求导
# Partial derivative of cost in terms of theta0
def partial_cost_theta0(theta0, theta1, theta2, theta3, theta4, x1, x2, x3, x4, y):
h = theta0 + x1 * theta1 + x2 * theta2 + x3 * theta3 + x4 * theta4
diff = (h - y)
partial = diff.sum() / (x2.shape[0])
return partial
def gradient_descent(x1,x2,x3,x4,y, alpha=0.1, theta0=0, theta1=0,theta2=0,theta3=0,theta4=0):
max_epochs = 1000 # Maximum number of iterations 最大迭代次数
counter = 0 # Intialize a counter 当前第几次
c = cost(theta0, theta1, theta2, theta3, theta4, x1, x2, x3, x4, y) ## Initial cost 当前代价函数
costs = [c] # Lets store each update 每次损失值都记录下来
# Set a convergence threshold to find where the cost function in minimized
# When the difference between the previous cost and current cost
# is less than this value we will say the parameters converged
# 设置一个收敛的阈值 (两次迭代目标函数值相差没有相差多少,就可以停止了)
convergence_thres = 0.000001
cprev = c + 10
theta0s = [theta0]
theta1s = [theta1]
theta2s = [theta2]
theta3s = [theta3]
theta4s = [theta4]
# When the costs converge or we hit a large number of iterations will we stop updating
# 两次间隔迭代目标函数值相差没有相差多少(说明可以停止了)
while (np.abs(cprev - c) > convergence_thres) and (counter < max_epochs):
cprev = c
# Alpha times the partial deriviative is our updated
# 先求导, 导数相当于步长
update0 = alpha * partial_cost_theta0(theta0, theta1, theta2, theta3, theta4, x1, x2, x3, x4, y)
update1 = alpha * partial_cost_theta1(theta0, theta1, theta2, theta3, theta4, x1, x2, x3, x4, y)
update2 = alpha * partial_cost_theta2(theta0, theta1, theta2, theta3, theta4, x1, x2, x3, x4, y)
update3 = alpha * partial_cost_theta3(theta0, theta1, theta2, theta3, theta4, x1, x2, x3, x4, y)
update4 = alpha * partial_cost_theta4(theta0, theta1, theta2, theta3, theta4, x1, x2, x3, x4, y)
# Update theta0 and theta1 at the same time
# We want to compute the slopes at the same set of hypothesised parameters
# so we update after finding the partial derivatives
# -= 梯度下降,+=梯度上升
theta0 -= update0
theta1 -= update1
theta2 -= update2
theta3 -= update3
theta4 -= update4
# Store thetas
theta0s.append(theta0)
theta1s.append(theta1)
theta2s.append(theta2)
theta3s.append(theta3)
theta4s.append(theta4)
# Compute the new cost
# 当前迭代之后,参数发生更新
c = cost(theta0, theta1, theta2, theta3, theta4, x1, x2, x3, x4, y)
# Store updates,可以进行保存当前代价值
costs.append(c)
counter += 1 # Count
# 将当前的theta0, theta1, costs值都返回去
#return {'theta0': theta0, 'theta1': theta1, 'theta2': theta2, 'theta3': theta3, 'theta4': theta4, "costs": costs}
return {'costs':costs}
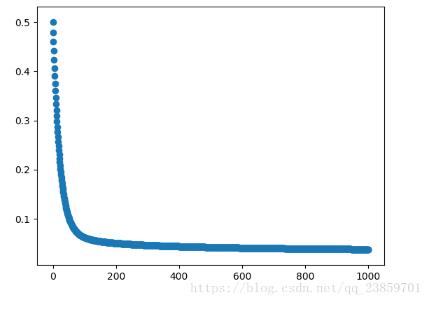
print("costs =", gradient_descent(pga.AT, pga.V,pga.AP,pga.RH,pga.PE)['costs'])
descend = gradient_descent(pga.AT, pga.V,pga.AP,pga.RH,pga.PE, alpha=.01)
plt.scatter(range(len(descend["costs"])), descend["costs"])
plt.show()
损失函数随迭代次数变换图:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python梯度下降法的简单示例
梯度下降法的原理和公式这里不讲,就是一个直观的.易于理解的简单例子. 1.最简单的情况,样本只有一个变量,即简单的(x,y).多变量的则可为使用体重或身高判断男女(这是假设,并不严谨),则变量有两个,一个是体重,一个是身高,则可表示为(x1,x2,y),即一个目标值有两个属性. 2.单个变量的情况最简单的就是,函数hk(x)=k*x这条直线(注意:这里k也是变化的,我们的目的就是求一个最优的 k).而深度学习中,我们是不知道函数的,也就是不知道上述的k. 这里讨论单变量的情况: 在不知道
-
python实现梯度下降法
本文实例为大家分享了python实现梯度下降法的具体代码,供大家参考,具体内容如下 使用工具:Python(x,y) 2.6.6 运行环境:Windows10 问题:求解y=2*x1+x2+3,即使用梯度下降法求解y=a*x1+b*x2+c中参数a,b,c的最优值(监督学习) 训练数据: x_train=[1, 2], [2, 1],[2, 3], [3, 5], [1,3], [4, 2], [7, 3], [4, 5], [11, 3], [8, 7] y_train=[7, 8, 10,
-

Python语言描述随机梯度下降法
1.梯度下降 1)什么是梯度下降? 因为梯度下降是一种思想,没有严格的定义,所以用一个比喻来解释什么是梯度下降. 简单来说,梯度下降就是从山顶找一条最短的路走到山脚最低的地方.但是因为选择方向的原因,我们找到的的最低点可能不是真正的最低点.如图所示,黑线标注的路线所指的方向并不是真正的地方. 既然是选择一个方向下山,那么这个方向怎么选?每次该怎么走? 先说选方向,在算法中是以随机方式给出的,这也是造成有时候走不到真正最低点的原因. 如果选定了方向,以后每走一步,都是选择最陡的方向,直到最低点.
-
python梯度下降算法的实现
本文实例为大家分享了python实现梯度下降算法的具体代码,供大家参考,具体内容如下 简介 本文使用python实现了梯度下降算法,支持y = Wx+b的线性回归 目前支持批量梯度算法和随机梯度下降算法(bs=1) 也支持输入特征向量的x维度小于3的图像可视化 代码要求python版本>3.4 代码 ''' 梯度下降算法 Batch Gradient Descent Stochastic Gradient Descent SGD ''' __author__ = 'epleone' import
-
python实现梯度下降算法
梯度下降(Gradient Descent)算法是机器学习中使用非常广泛的优化算法.当前流行的机器学习库或者深度学习库都会包括梯度下降算法的不同变种实现. 本文主要以线性回归算法损失函数求极小值来说明如何使用梯度下降算法并给出python实现.若有不正确的地方,希望读者能指出. 梯度下降 梯度下降原理:将函数比作一座山,我们站在某个山坡上,往四周看,从哪个方向向下走一小步,能够下降的最快. 在线性回归算法中,损失函数为 在求极小值时,在数据量很小的时候,可以使用矩阵求逆的方式求最优的θ值.但当数
-
python+numpy+matplotalib实现梯度下降法
这个阶段一直在做和梯度一类算法相关的东西,索性在这儿做个汇总, 一.算法论述 梯度下降法(gradient descent)别名最速下降法(曾经我以为这是两个不同的算法-.-),是用来求解无约束最优化问题的一种常用算法.下面以求解线性回归为题来叙述: 设:一般的线性回归方程(拟合函数)为:(其中的值为1) 则这一组向量参数选择的好与坏就需要一个机制来评估,据此我们提出了其损失函数为(选择均方误差): 我们现在的目的就是使得损失函数取得最小值,即目标函数为: 如果的值取到了0,意味着我们构造出了
-
python实现随机梯度下降法
看这篇文章前强烈建议你看看上一篇python实现梯度下降法: 一.为什么要提出随机梯度下降算法 注意看梯度下降法权值的更新方式(推导过程在上一篇文章中有) 也就是说每次更新权值都需要遍历整个数据集(注意那个求和符号),当数据量小的时候,我们还能够接受这种算法,一旦数据量过大,那么使用该方法会使得收敛过程极度缓慢,并且当存在多个局部极小值时,无法保证搜索到全局最优解.为了解决这样的问题,引入了梯度下降法的进阶形式:随机梯度下降法. 二.核心思想 对于权值的更新不再通过遍历全部的数据集,而是选择其中
-
基于随机梯度下降的矩阵分解推荐算法(python)
SVD是矩阵分解常用的方法,其原理为:矩阵M可以写成矩阵A.B与C相乘得到,而B可以与A或者C合并,就变成了两个元素M1与M2的矩阵相乘可以得到M. 矩阵分解推荐的思想就是基于此,将每个user和item的内在feature构成的矩阵分别表示为M1与M2,则内在feature的乘积得到M:因此我们可以利用已有数据(user对item的打分)通过随机梯度下降的方法计算出现有user和item最可能的feature对应到的M1与M2(相当于得到每个user和每个item的内在属性),这样就可以得到通
-
python实现随机梯度下降(SGD)
使用神经网络进行样本训练,要实现随机梯度下降算法.这里我根据麦子学院彭亮老师的讲解,总结如下,(神经网络的结构在另一篇博客中已经定义): def SGD(self, training_data, epochs, mini_batch_size, eta, test_data=None): if test_data: n_test = len(test_data)#有多少个测试集 n = len(training_data) for j in xrange(epochs): random.shuf
-
Python编程实现线性回归和批量梯度下降法代码实例
通过学习斯坦福公开课的线性规划和梯度下降,参考他人代码自己做了测试,写了个类以后有时间再去扩展,代码注释以后再加,作业好多: import numpy as np import matplotlib.pyplot as plt import random class dataMinning: datasets = [] labelsets = [] addressD = '' #Data folder addressL = '' #Label folder npDatasets = np.zer