python逆向微信指数爬取实现步骤
目录
- 微信指数爬取
- 1.MAC系统Appium的环境搭建
- 1. homebrew的安装
- 2. 通过brew安装node
- 3. 安装npm
- 4. 安装android-sdk-macosx
- 5. 安装jdk
- 6. 环境变量配置
- 7. 安装appium-doctor
- 8. 安装appium命令行版
- 9. 安装mitmproxy
- 10.安装网易mumu安卓模拟器
- 2.微信指数小程序爬取
- 1.启动appium 在终端输入
- 2.启动网易mumu安卓模拟器并安装微信
- 3. 查看adb连接的设备
- 4. 模拟器安装mitmproxy证书
- 5.通过抓包发现微信指数小程序生成search_key的接口
- 6.编写appium模拟点击微信进入微信指数小程序触发search_key指令代码
- 总结:
微信指数爬取
Appium + mitmproxy + 网易mumu安卓模拟器实现微信指数小程序爬取
通过appium实现将指令传输给手机进行相关的操作,mitmproxy运行Python脚本过滤出相关的请求,安卓模拟器取代真机使项目可以更好的落地。
1.MAC系统Appium的环境搭建
1. homebrew的安装
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
2. 通过brew安装node
brew install node
检查node是否安装成功
node -v
3. 安装npm
sudo bash sudo curl -L https://npmjs.org/install.sh | sh
检查npm是否安装完成
npm -v
4. 安装android-sdk-macosx
链接: android-sdk-macosx.
下载完成因sdk缺少对应的platform-tools和build-tools 执行命令在弹出窗口进行勾选下载platform-tools和build-tools
5. 安装jdk
去官网下载:下载地址为直接下载dmg去安装
链接:JDK
6. 环境变量配置
可参考以下配置
cd ~
vi .bash_profile
JAVA_HOME=/Library/java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home CLASSPAHT=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar PATH=$JAVA_HOME/bin:$PATH: export JAVA_HOME export CLASSPATH export PATH export ANDROID_HOME=/Users/admin/Desktop/android-sdk-macosx export PATH=$PATH:$ANDROID_HOME/tools export PATH=$PATH:$ANDROID_HOME/platform-tools
source .bash_profile
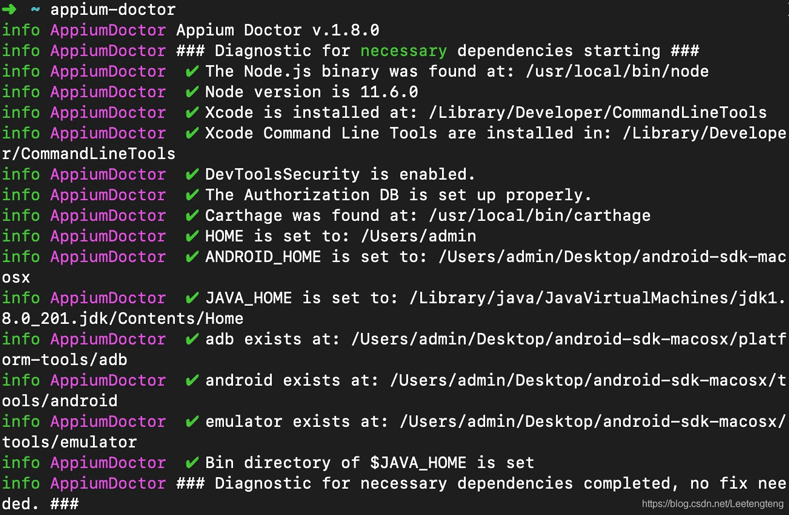
7. 安装appium-doctor
检查已有的环境是否都已成功
npm install -g appium-doctor
安装完成appium-doctor 在终端输入appium-doctor命令自动检查appium所依赖的包是否有缺失
8. 安装appium命令行版
npm install -g appium
appium -v 查看版本号
9. 安装mitmproxy
(抓包,中间人代理工具、支持SSL)
brew install mitmproxy
具体用法自行研究 本文只是简单的使用
10.安装网易mumu安卓模拟器
官网直接下载 有Mac版的
2.微信指数小程序爬取
1.启动appium 在终端输入
appium
2.启动网易mumu安卓模拟器并安装微信

3. 查看adb连接的设备
adb devices
首次需要先连接到模拟器 网易mumu端口号为7555 终端输入
adb connect 127.0.0.1:7555

4. 模拟器安装mitmproxy证书
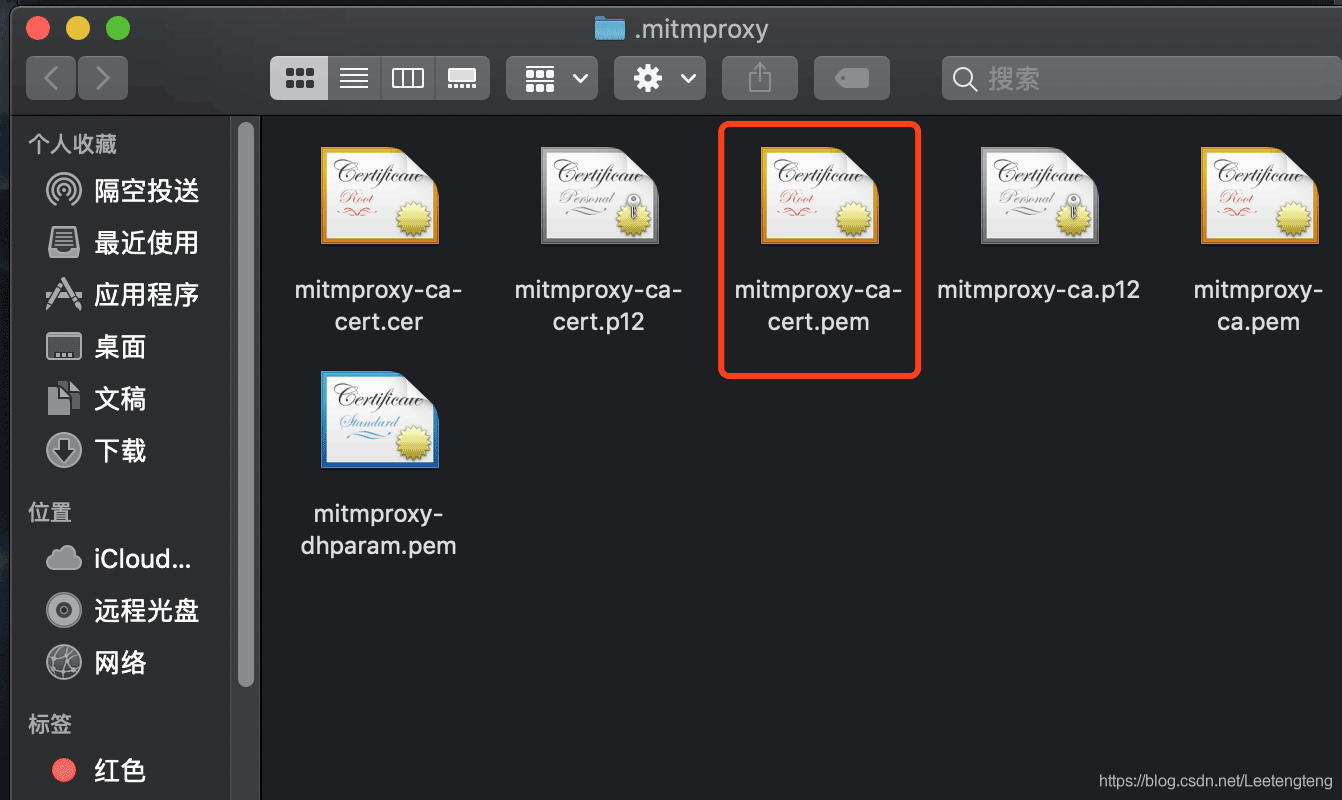
将该证书打开在钥匙串中找到修改全部信任
然后在模拟器中安装 打开模拟器的设置—安全—从SD卡安装
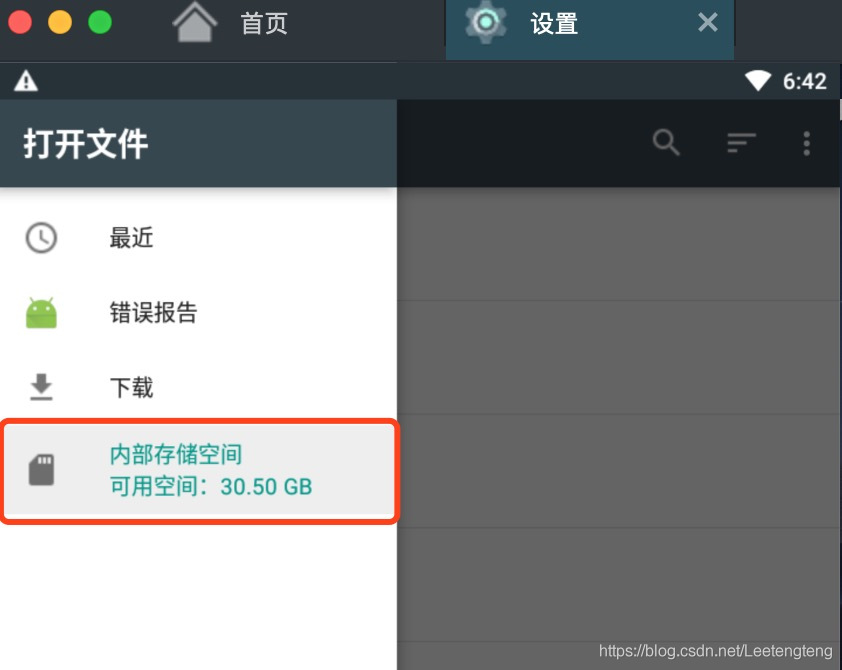
打开内部存储空间—MuMu共享文件夹—将信任的证书拖进去即可

5.通过抓包发现微信指数小程序生成search_key的接口
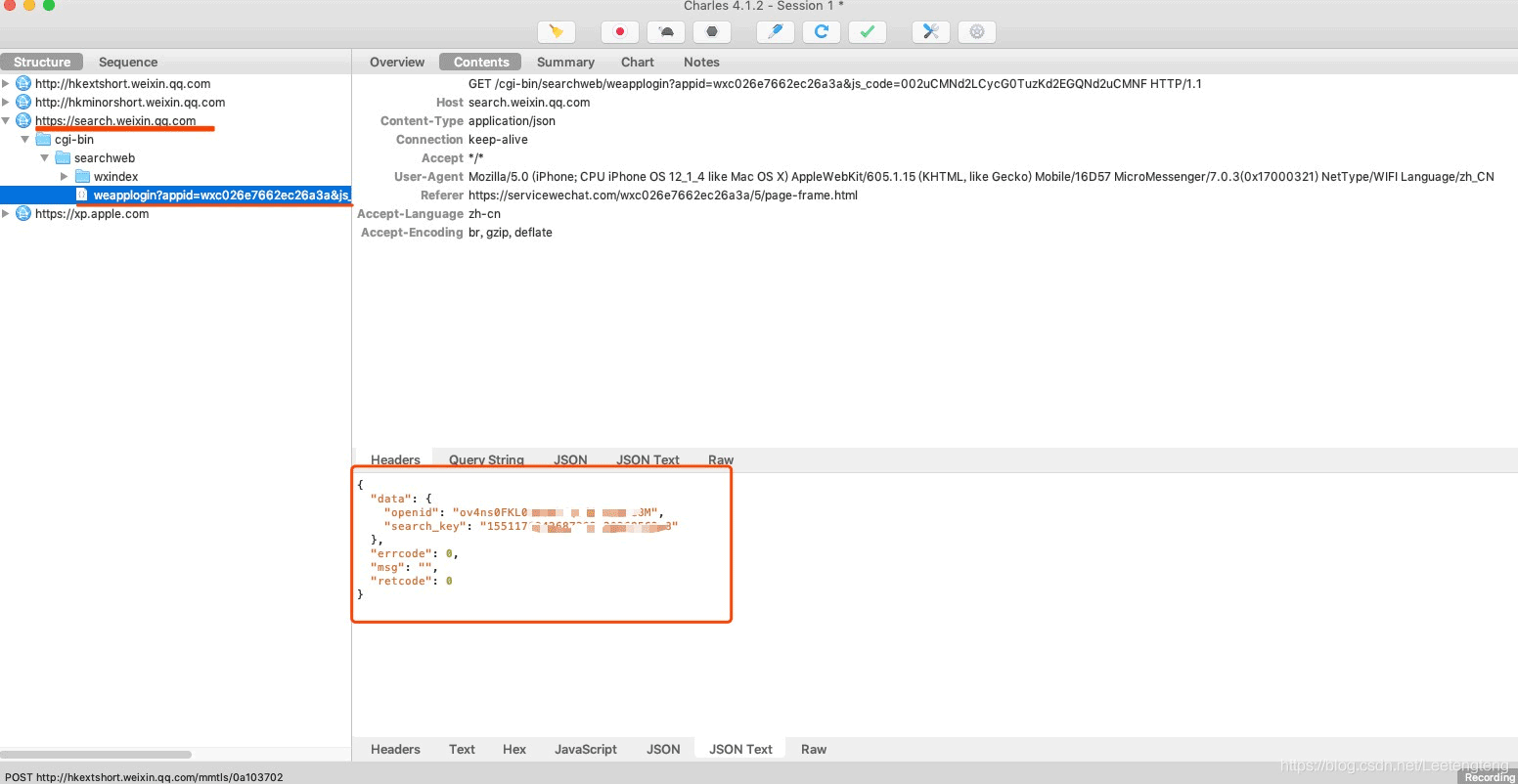
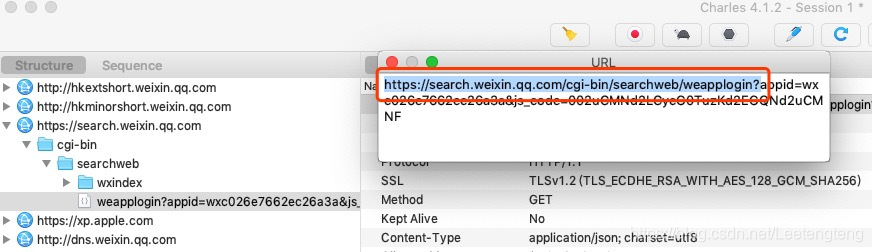
编写Python脚本过滤出该请求并将该请求的响应内容(search_key)写入Mongo库
import json
import time
import sys
from pymongo import MongoClient
def response(flow):
client = MongoClient("xx.xx.xx.xx",27017)
db = client["Spider"]
url = "https://search.weixin.qq.com/cgi-bin/searchweb/weapplogin"
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
search_key = data.get("data").get("search_key")
with open("./search_key.txt",'w+') as f:
f.write(search_key)
'''
search_key 博主是入库然后scrapy爬虫从库中读search_key进行请求 具体怎么用自己按情况即可
'''
使用mitmdump -s xxx.py 执行Python脚本
mitmdump -s test.py
先手动点击进入微信指数小程序触发生成search_key的接口 此时mitmproxy运行python程序按照代码对该请求进行过滤并将响应中的search_key取出写入到本地文件

到了这一步大家应该已经知道微信指数小程序的爬取方式了 在这里说下生成search_key接口的触发规则:首次进入微信指数小程序 2.三十分钟search_key失效
6.编写appium模拟点击微信进入微信指数小程序触发search_key指令代码
import time
from appium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pymongo import MongoClient
PLATFORM='Android'
deviceName='emulator-5554'
# app_package和app_activity可以通过adb shell进行获取
app_package='com.tencent.mm'
app_activity='.ui.LauncherUI'
driver_server='http://127.0.0.1:4723/wd/hub'
class Moments():
def __init__(self):
self.desired_caps={
'platformName':PLATFORM,
'deviceName':deviceName,
'appPackage':app_package,
'appActivity':app_activity,
'noReset': "True",
}
self.driver=webdriver.Remote(driver_server,self.desired_caps)
self.wait=WebDriverWait(self.driver,300)
def login(self):
# 允许获取xx
yunxu1 = self.wait.until(EC.presence_of_element_located((By.ID,'com.android.packageinstaller:id/permission_allow_button')))
yunxu1.click()
time.sleep(5)
# 允许获取xxx
yunxu2 = self.wait.until(EC.presence_of_element_located((By.ID,'com.android.packageinstaller:id/permission_allow_button')))
yunxu2.click()
time.sleep(5)
# 登陆按钮
login = self.wait.until(EC.presence_of_element_located((By.ID,'com.tencent.mm:id/d75')))
login.click()
time.sleep(3)
# 手机号
phone = self.wait.until(EC.presence_of_element_located((By.ID,'com.tencent.mm:id/hz')))
phone.send_keys("xxxxxx")
time.sleep(3)
# 下一步
nextButton = self.wait.until(EC.presence_of_element_located((By.ID,'com.tencent.mm:id/alr')))
nextButton.click()
time.sleep(2)
# 密码
passButton = self.wait.until(EC.presence_of_element_located((By.ID,"com.tencent.mm:id/hz")))
passButton.send_keys("xxxxx")
time.sleep(2)
# 登陆
login2 = self.wait.until(EC.presence_of_element_located((By.ID,'com.tencent.mm:id/alr')))
login2.click()
time.sleep(6)
# 不允许获取通讯录
notButton = self.wait.until(EC.presence_of_element_located((By.ID,"com.tencent.mm:id/an2")))
notButton.click()
time.sleep(5)
def test(self):
'''
登陆之后 依次点击发现 小程序 微信指数 触发接口
'''
time.sleep(10)
self.driver.tap([(428,1214),(471,1251)],100)
time.sleep(5)
# 发现页小程序的坐标
self.driver.tap([(85,787),(148,816)],100)
time.sleep(5)
self.driver.tap([(114,237),(206,269)],100)
time.sleep(20)
self.driver.tap([(644,42),(708,85)],100)
def main(self):
# 首次登陆
self.login()
self.test()
M=Moments()
M.main()
郑重声明:首次登陆以后的每次操作只需要执行test方法点击到发现—小程序—微信指数即可,可以通过noReset:True设置每次不重新安装app,所以不必每次都登陆账号导致增加不必要的操作
通过uiautomatorviewer获取appium页面元素进行定位

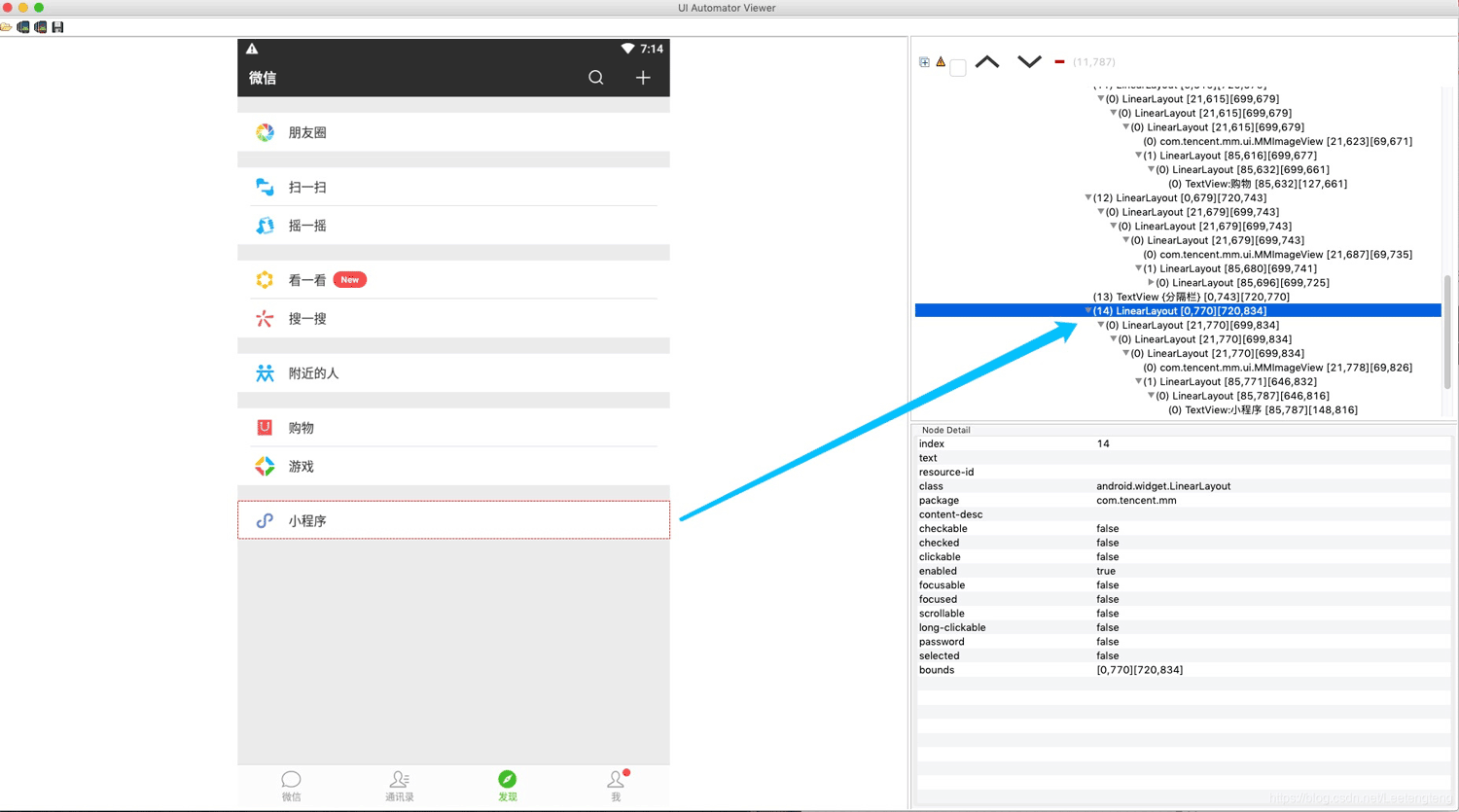
总结:
通过appium将模拟点击的指令操控模拟器进行点击进入微信指数的小程序触发search_key接口的生成,然后通过mitmdump -s xx.py程序进行过滤出相应请求将响应中的search_key进行持久化 爬取数据的时候还是使用scrapy (直接使用模拟器爬取不是好的方法)。方案可能不是最好的但是比直接破解微信登录接口、js_code(生成search_key的必要参数) 要好很多了
以上就是python逆向微信指数爬取实现步骤的详细内容,更多关于python逆向微信指数爬取的资料请关注我们其它相关文章!
相关推荐
-
基于Python采集爬取微信公众号历史数据
鲲之鹏的技术人员将在本文介绍一种通过模拟操作微信App的方式采集指定公众号的所有历史数据的方法. 通过我们抓包分析发现,微信公众号的历史数据是通过HTTP协议加载的,对应的API接口如下图所示,其中有四个关键参数(__biz.appmsg_token.pass_ticket以及Cookie). 为了能够拿到这四个参数,我们需要模拟操作App,让其产生这些参数,然后我们再抓包获取.对于模拟App操作,前面我们曾介绍过通过Python模拟安卓App的方法(详见http://www.site-digg
-
Python批量查询关键词微信指数实例方法
教你用Python批量查询关键词微信指数. 前期准备安装好Python开发环境及Fiddler抓包工具.前期准备安装好Python开发环境及Fiddler抓包工具. 首先打开Fiddler软件,点击Tools,在下拉菜单选择Options,然后选中HTTPS,进行HTTPS设置,如下图所示: 再进行connections设置,如下图所示: 手机配置主要是使电脑和手机处于同一个局域网,打开手机WLAN设置,开启手动代理,然后设置代理服务器主机名和代理服务器端口.代理服务器主机名为电脑IPv4地址,
-

Python实现微信好友数据爬取及分析
前言 随着微信的普及,越来越多的人开始使用微信.微信渐渐从一款单纯的社交软件转变成了一个生活方式,人们的日常沟通需要微信,工作交流也需要微信.微信里的每一个好友,都代表着人们在社会里扮演的不同角色. 今天这篇文章会基于Python对微信好友进行数据分析,这里选择的维度主要有:性别.头像.签名.位置,主要采用图表和词云两种形式来呈现结果,其中,对文本类信息会采用词频分析和情感分析两种方法.常言道:工欲善其事,必先利其器也.在正式开始这篇文章前,简单介绍下本文中使用到的第三方模块: itchat:微
-
Python爬虫实现“盗取”微信好友信息的方法分析
本文实例讲述了Python爬虫实现"盗取"微信好友信息的方法.分享给大家供大家参考,具体如下: 刚起床,闲来无聊,找点事做,看了朋友圈一篇爬取微信好友信息的文章,突发奇想,偷偷看看女朋友微信有些啥....于是就下手了....[阴险] 1.准备工作: 运行平台:Windows Python版本:Python3.6 IDE:Sublime Text Python库:wxpy, 2.开发流程:(电脑没电了,要撑不住了啦~之后具体分析) 3.直接上代码: # 微信好友信息爬取+数据可视化 #
-
python爬虫中抓取指数的实例讲解
有一些数据我们是没法直观的查看的,需要通过抓取去获得.听到指数这个词,有的小伙伴们觉得很复杂,似乎只在股票的时候才听说的,比如一些数据的涨跌分析都是比较棘手的问题.不过指数对于我们的数据分析还是很有帮助的,今天小编就python爬虫中抓取指数得方法给大家带来讲解. 刚好这几天需要用到这个爬虫,结果发现baidu指数的请求有点变化,所以就改了改: import requests import sys import time word_url = 'http://index.baidu.com/ap
-
用 Python 爬了爬自己的微信朋友(实例讲解)
最近几天干啥都不来劲,昨晚偶然了解到 Python 里的 itchat 包,它已经完成了 wechat 的个人账号 API 接口,使爬取个人微信信息更加方便.鉴于自己很早之前就想知道诸如自己微信好友性别比例都来自哪个城市之类的问题,于是乎玩心一起,打算爬一下自己的微信. 作者:Alfred 首先,在终端安装一下 itchat 包. 安装完成后导入包,再登陆自己的微信.过程中会生产一个登陆二维码,扫码之后即可登陆.登陆成功后,把自己好友的相关信息爬下来. 有了上面的 friends 数据,我们就可
-
python逆向微信指数爬取实现步骤
目录 微信指数爬取 1.MAC系统Appium的环境搭建 1. homebrew的安装 2. 通过brew安装node 3. 安装npm 4. 安装android-sdk-macosx 5. 安装jdk 6. 环境变量配置 7. 安装appium-doctor 8. 安装appium命令行版 9. 安装mitmproxy 10.安装网易mumu安卓模拟器 2.微信指数小程序爬取 1.启动appium 在终端输入 2.启动网易mumu安卓模拟器并安装微信 3. 查看adb连接的设备 4. 模拟器安
-
python趣味挑战之爬取天气与微博热搜并自动发给微信好友
一.系统环境 1.python 3.8.2 2.webdriver(用于驱动edge) 3.微信电脑版 4.windows10 二.爬取中国天气网 因为中国天气网的网页是动态生成的,所以不能直接爬取到数据,需要先使用webdriver打开网页并渲染完成,然后保存网页源代码,使用beautifulsoup分析数据.爬取的数据包括实时温度.最高温度与最低温度.污染状况.风向和湿度.紫外线状况.穿衣指南八项数据. def getZZWeatherAndSendMsg(): HTML1='http://
-
python爬虫之Appium爬取手机App数据及模拟用户手势
目录 Appium 模拟操作 屏幕滑动 屏幕点击 屏幕拖动 屏幕拖拽 文本输入 动作链 实战:爬取微博首页信息 Appium 在前文的讲解中,我们学会了如何安装Appium,以及一些基础获取App元素内容的方式.但认真看过前文的读者,肯定在博主获取元素的时候观察到了一个现象. 那就是手机App的内容并不是一次性加载出来的,比如大多数Android手机列表ListView,都是异步加载,也就是你滑动到那个位置,它才会显示出它的内容. 也就是说,我们前面爬取微博首页全部信息的时候,如果你不滑动先加载
-
Python爬虫小例子——爬取51job发布的工作职位
概述 不知从何时起,Python和爬虫就如初恋一般,情不知所起,一往而深,相信很多朋友学习Python,都是从爬虫开始,其实究其原因,不外两方面:其一Python对爬虫的支持度比较好,类库众多.其二Pyhton的语法简单,入门容易.所以两者形影相随,不离不弃,本文主要以一个简单的小例子,简述Python在爬虫方面的简单应用,仅供学习分享使用,如有不足之处,还请指正. 涉及知识点 本例主要爬取51job发布的工作职位,用到的知识点如下: 开发环境及工具:主要用到Python3.7 ,IDE为PyC
-
python爬虫使用正则爬取网站的实现
本文章的所有代码和相关文章, 仅用于经验技术交流分享,禁止将相关技术应用到不正当途径,滥用技术产生的风险与本人无关. 本文章是自己学习的一些记录.欢迎各位大佬点评! 首先 今天是第一天写博客,感受到了博客的魅力,博客不仅能够记录每天的代码学习情况,并且可以当作是自己的学习笔记,以便在后面知识点不清楚的时候前来复习.这是第一次使用爬虫爬取网页,这里展示的是爬取豆瓣电影top250的整个过程,欢迎大家指点. 这里我只爬取了电影链接和电影名称,如果想要更加完整的爬取代码,请联系我.qq 1540741
-
使用python tkinter开发一个爬取B站直播弹幕工具的实现代码
项目地址 https://github.com/jonssonyan... 开发工具 python 3.7.9 pycharm 2019.3.5 代码 import threading import time import tkinter.simpledialog from tkinter import END, simpledialog, messagebox import requests class Danmu(): def __init__(self, room_id): # 弹幕url
-
Python趣味爬虫之爬取爱奇艺热门电影
一.首先我们要找到目标 找到目标先分析一下网页很幸运这个只有一个网页,不需要翻页. 二.F12查看网页源代码 找到目标,分析如何获取需要的数据.找到href与电影名称 三.进行代码实现,获取想要资源. ''' 操作步骤 1,获取到url内容 2,css选择其选择内容 3,保存自己需要数据 ''' #导入爬虫需要的包 import requests from bs4 import BeautifulSoup #requests与BeautifulSoup用来解析网页的 import time #设
-
Python爬虫实战之爬取某宝男装信息
目录 知识点介绍 实现步骤 1. 分析目标网站 2. 获取单个商品界面 3. 获取多个商品界面 4. 获取商品信息 5. 保存到MySQL数据库 完整代码 知识点介绍 本次爬取用到的知识点有: 1. selenium 2. pymysql 3 pyquery 实现步骤 1. 分析目标网站 1. 打开某宝首页, 输入"男装"后点击"搜索", 则跳转到"男装"的搜索界面. 2. 空白处"右击"再点击"检查"审
-
Python爬虫DOTA排行榜爬取实例(分享)
1.分析网站 打开开发者工具,我们观察到排行榜的数据并没有在doc里 doc文档 在Javascript里我么可以看到下面代码: ajax的post方法异步请求数据 在 XHR一栏里,我们找到所请求的数据 json存储的数据 请求字段为: post请求字段 2.伪装浏览器,并将json数据存入excel里面 获取信息 将数据保存到excel中 3.结果展示 以上这篇Python爬虫DOTA排行榜爬取实例(分享)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
python利用urllib实现爬取京东网站商品图片的爬虫实例
本例程使用urlib实现的,基于python2.7版本,采用beautifulsoup进行网页分析,没有第三方库的应该安装上之后才能运行,我用的IDE是pycharm,闲话少说,直接上代码! # -*- coding: utf-8 -* import re import os import urllib import urllib2 from bs4 import BeautifulSoup def craw(url,page): html1=urllib2.urlopen(url).read(