Python Pivot table透视表使用方法解析
Pivot 及 Pivot_table函数用法
Pivot和Pivot_table函数都是对数据做透视表而使用的。其中的区别在于Pivot_table可以支持重复元素的聚合操作,而Pivot函数只能对不重复的元素进行聚合操作。
在一般的日常业务中,因为Pivot_table的功能更为强大,Pivot能做的不能做的Pivot_table都可做。所以只需要记住Pivot_table函数用法就好了。
Pivot函数的使用演示
#%%
import pandas as pd
df01 = pd.DataFrame(
{
"年份":[2019,2019,2019,2020,2020,2020],
"平台":["京东","淘宝","拼多多","京东","淘宝","拼多多"],
"销量":[100,200,300,400,500,600]
}
)
df01
#%%
pd.pivot(df01,
index = "年份",
columns = "平台",
values = "销量")
#%%
聚合后结果

Pivot_table函数的使用演示
注释:index指定什么元素作为index显示,columns指定列,values指定统计的值。一般values都为int后者float类型的值。aggfunc为聚合函数可以指定(mean,sum,Min,Max等统计运算等函数,如果不指定默认为mean均值)
df02 = pd.DataFrame(
{
"年份":[2019,2019,2019,2019,2020,2020,2020,2020],
"平台":["京东","淘宝","淘宝","拼多多","京东","淘宝","拼多多","拼多多"],
"销量":[100,200,300,400,500,600,700,800]
}
)
df02
#%%
#pivot_table用的很多.因为可以对重复的元素进行聚合操作.而pivot函数只能对不重复的行进行运算
pd.pivot_table(df02,
index="年份",
columns="平台",
values="销量",
aggfunc=sum #聚合函数来对销量进行运算.可以指定最大,最小,平均值等函数.默认为mean平均值
)
#%%
聚合结果
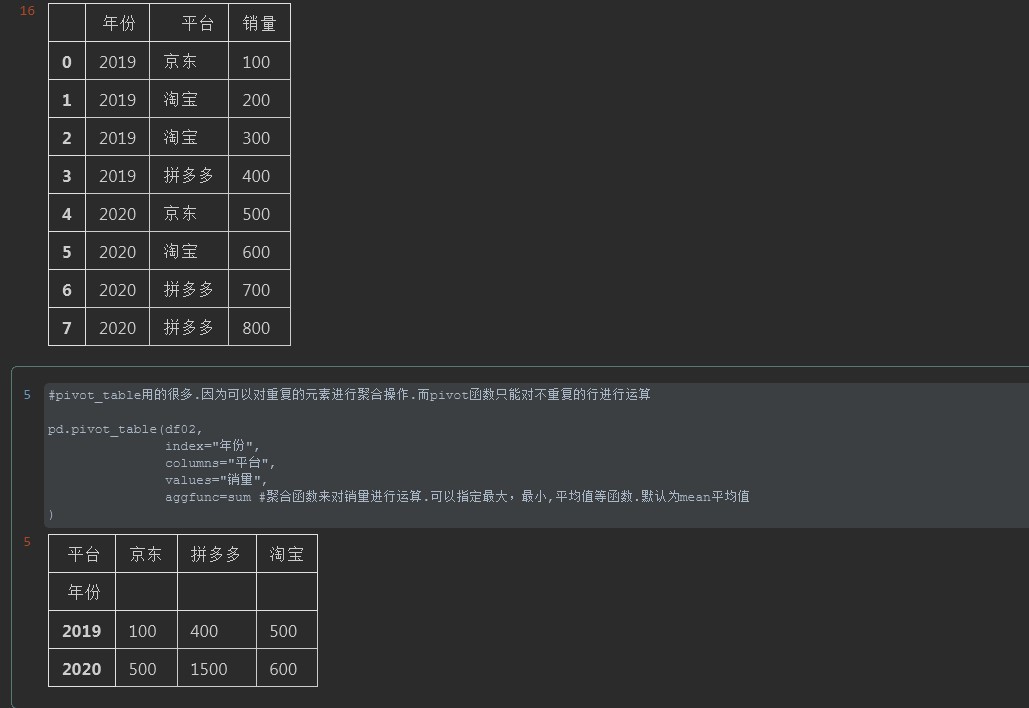
对比结果:这里要强调一点的是,2020年平台为拼多多的数据出现了2次,而且2次的值不同。在pivot函数中是无法对这种重复平台的数据进行聚合的,但是Pivot_table则可以。
另外通过聚合函数aggfunc指定sum求和,可以把2次的值累加统计。
Pivot_table函数真实案例演示
1. 读取表格数据
#%%
df = pd.read_excel("./datas/result_datas.xlsx",
).convert_dtypes() #读取数据并自动转化type
df.dtypes
#%%
df.head(3)
#%%

2. 通过Pivot_table函数透视合并数据并对金额和数量做统计
因为涉及到敏感信息,因此服务卡卡号等敏感信息部分遮掩不显示。但是通过部分结果也可以看出是按照号码进行升序排序的
#按照自定义指定index,columns,values值
result = pd.pivot_table(df,
index = ["姓名","服务卡卡号","明细","规格"],
values = ["理赔金额(元)","数量"],
aggfunc=sum
)
result = result.sort_values("服务卡卡号") #按照指定values值排序
result
#%%
#输出到文件
result.to_excel("./datas/output_datas.xlsx")
print("Done!!!")

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
行转列之SQL SERVER PIVOT与用法详解
在数据库操作中,有些时候我们遇到需要实现"行转列"的需求,例如一下的表为某店铺的一周收入情况表: WEEK_INCOME(WEEK VARCHAR(10),INCOME DECIMAL) 我们先插入一些模拟数据: INSERT INTO WEEK_INCOME SELECT '星期一',1000 UNION ALL SELECT '星期二',2000 UNION ALL SELECT '星期三',3000 UNION ALL SELECT '星期四',4000 UNION ALL SE
-
Pandas 重塑(stack)和轴向旋转(pivot)的实现
import numpy as np import pandas as pd from pandas import Series,DataFrame 一.重塑 stack:将数据的列索引旋转为行索引 unstack:将数据的行索引旋转为列索引 df = DataFrame({'水果':['苹果','梨','草莓'], '数量':[3,4,5], '价格':[4,5,6]}) print(df) 价格 数量 水果 0 4 3 苹果 1 5 4 梨 2 6 5 草
-

Pandas透视表(pivot_table)详解
介绍 也许大多数人都有在Excel中使用数据透视表的经历,其实Pandas也提供了一个类似的功能,名为pivot_table.虽然pivot_table非常有用,但是我发现为了格式化输出我所需要的内容,经常需要记住它的使用语法.所以,本文将重点解释pandas中的函数pivot_table,并教大家如何使用它来进行数据分析. 如果你对这个概念不熟悉,wikipedia上对它做了详细的解释.顺便说一下,你知道微软为PivotTable(透视表)注册了商标吗?其实以前我也不知道.不用说,下面我将讨论
-
pandas pivot_table() 按日期分多列数据的方法
如下所示: date 20170307 20170308 iphone4 2 0 iphone5 2 1 iphone6 0 1 先生成DF数据. >>> df = pd.DataFrame.from_dict([['ip4','20170307',1],['ip4','20170307',1],['ip5','20170307',1],['ip5','20170307',1],['ip6','20170308',1],['ip5','20170308',1]]) >>>
-
SQL知识点之列转行Unpivot函数
前言 这是总结SQL知识点的第二篇文章,一次只总结一个知识点,尽量说明白.上次我们谈到行转列,用的是Pivot函数,这次我们来谈谈Unpivot函数.(这里是用的数据库是SQLSERVER,与其他数据库是类似的,大家放心看就好) 先看一个小问题CustomerCustomer 在这张图中,表示的是顾客用不同手机号给Phone1.Phone2.Phone3拨打电话的情况,但是机灵的你,想变个花样来看看,比如下面这样的. UnpivotUnpivot 大家想想看如何实现呢?想下,2分钟后再看哟 先创
-
SQL基础教程之行转列Pivot函数
前言 未来的一个月时间中,会总结一系列SQL知识点,一次只总结一个知识点,尽量说明白,下面来说说SQL 中常用Pivot 函数(这里是用的数据库是SQLSERVER,与其他数据库是类似的,大家放心看就好) 让我们先从一个虚构的场景中来着手吧 万国来朝,很多供应商每天都汇报各自的收入情况.先来创建一个DailyIncome 表 create table DailyIncome(VendorId nvarchar(10), IncomeDay nvarchar(10), IncomeAmount i
-
C#实现Excel动态生成PivotTable
Excel 中的透视表对于数据分析来说,非常的方便,而且很多业务人员对于Excel的操作也是非常熟悉的,因此用Excel作为分析数据的界面,不失为一种很好的选择.那么如何用C#从数据库中抓取数据,并在Excel 动态生成PivotTable呢?下面结合实例来说明. 一般来说,数据库的设计都遵循规范化的原则,从而减少数据的冗余,但是对于数据分析来说,数据冗余能够提高数据加载的速度,因此为了演示透视表,这里现在数据库中建立一个视图,将需要分析的数据整合到一个视图中.如下图所示: 数据源准备好后,我们
-
Python Pivot table透视表使用方法解析
Pivot 及 Pivot_table函数用法 Pivot和Pivot_table函数都是对数据做透视表而使用的.其中的区别在于Pivot_table可以支持重复元素的聚合操作,而Pivot函数只能对不重复的元素进行聚合操作. 在一般的日常业务中,因为Pivot_table的功能更为强大,Pivot能做的不能做的Pivot_table都可做.所以只需要记住Pivot_table函数用法就好了. Pivot函数的使用演示 #%% import pandas as pd df01 = pd.Data
-
Python制作数据分析透视表的方法详解
目录 1.pivot_table函数index属性 2.pivot_table函数values属性 3.pivot_table函数aggfunc属性 4.pivot_table函数columns属性 透视表是一种可以对数据动态排布并且分类汇总的表格格式,在常用的python的数据分析非标准库pandas中体现为pivot_table模块. pivot_table数据透视表可以灵活的定制数据分析需求进行汇总,当然在Excel办公操作中早就存在了数据透视表的工具.如今,数据透视表被应用在python
-
用Python实现数据的透视表的方法
在处理数据时,经常需要对数据分组计算均值或者计数,在Microsoft Excel中,可以通过透视表轻易实现简单的分组运算.而对于更加复杂的分组运算,Python中pandas包可以帮助我们实现. 1 数据 首先引入几个重要的包: import pandas as pd import numpy as np from pandas import DataFrame,Series 通过代码构造数据集: data=DataFrame({'key1':['a','b','c','a','c','a',
-
一文搞懂Python中pandas透视表pivot_table功能详解
目录 一.概述 1.1 什么是透视表? 1.2 为什么要使用pivot_table? 二.如何使用pivot_table 2.1 读取数据 2.2Index 2.3Values 2.4Aggfunc 2.5Columns 一文看懂pandas的透视表pivot_table 一.概述 1.1 什么是透视表? 透视表是一种可以对数据动态排布并且分类汇总的表格格式.或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table. 1.2 为什么要使用
-
一文搞懂Python中pandas透视表pivot_table功能
目录 一.概述 1.1 什么是透视表? 1.2 为什么要使用pivot_table? 二.如何使用pivot_table 2.1 读取数据 2.2Index 2.3Values 2.4Aggfunc 2.5Columns 一文看懂pandas的透视表pivot_table 一.概述 1.1 什么是透视表? 透视表是一种可以对数据动态排布并且分类汇总的表格格式.或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table. 1.2 为什么要使用
-
python查询sqlite数据表的方法
本文实例讲述了python查询sqlite数据表的方法.分享给大家供大家参考.具体实现方法如下: import sqlite3 as db conn = db.connect('mytest.db') conn.row_factory = db.Row cursor = conn.cursor() cursor.execute("select * from person") rows = cursor.fetchall() for row in rows: print("%s
-
python中删除某个元素的方法解析
这篇文章主要介绍了python中删除某个元素的方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 python中关于删除list中的某个元素,一般有三种方法:remove.pop.del 1.remove: 删除单个元素,删除首个符合条件的元素,按值删除 举例说明: >>> str=[1,2,3,4,5,2,6] >>> str.remove(2) >>> str [1, 3, 4, 5, 2,
-
python循环嵌套的多种使用方法解析
这篇文章主要介绍了python循环嵌套的多种使用方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 使用循环嵌套来获取100以内的质数 #!/usr/bin/python # -*- coding: UTF-8 -*- num=[]; i=2 for i in range(2,100): j=2 for j in range(2,i): if(i%j==0): break else: num.append(i) print(num) 使用嵌
-
python函数不定长参数使用方法解析
这篇文章主要介绍了python函数不定长参数使用方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 pathon中的函数可以使用不定长参数,可以用参数*args接收单个出现的参数,接收后存成一个元组:用**kwargs接收以键值对形式出现的参数,接收后存丰一个字典.下面的小程序能说明这个问题 代码如下: def print_info(*args,**kwargs): for i in args: print(i) for i in kwar
-
Python实现数据透视表详解
目录 1.groupby + agg 2. crosstab 3.groupby + pivot pivot_table 总结 用Python里的Pandas可以实现,虽然感觉Excel更方便 1.groupby + agg 不够直观,不好看 对贷款年份,贷款种类创建数据透视 train_data.groupby(['year_of_loan', 'class']).agg(d_roat =('isDefault', 'mean')) 2. crosstab pandas.crosstab(in