redis中Hash字典操作的方法
目录
- 1.Redis操作之Hash操作
- redis hash字典操作
1.Redis操作之Hash操作
redis支持五大数据类型,只支持第一层,也就说字典的value值,必须是字符串
如果value值想存字典,必须用json转换一下,转成字符串
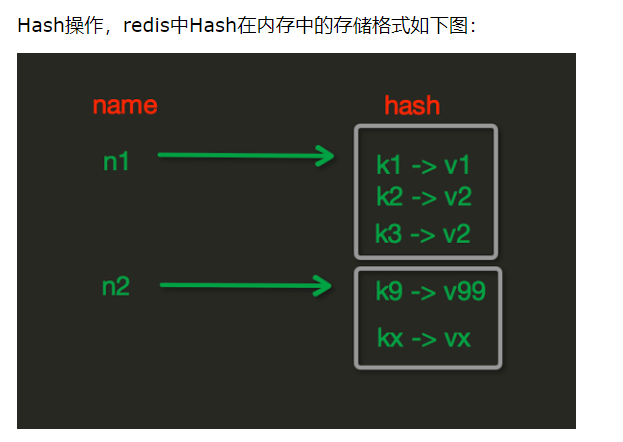
redis hash字典操作
reids:{
k1:'dafdadfasf',
m1:{
'key2':value2,
'key1':value1,
}
}
1.hset(name, key, value),插入值
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
# 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value
# 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
# 设置值# conn.hset('m1','cao','曹蕊')
2.hmset(name, mapping),批量插入值
# 在name对应的hash中批量设置键值对
# 参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
# 如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
# 批量插入设置值# conn.hmset('m2', {'cao': 100, 'bai': 101})
3.hget(name,key),取值
# 在name对应的hash中获取根据key获取value
# 取值,根据大字典的key,再去查key
print(conn.hget('m2','cao'))
4.hmget(name, keys, *args) 批量取值
# 在name对应的hash中获取多个key的值
# 参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3
# 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')
print(conn.hmget('m2','cao','bai'))print(conn.hmget('m2',['cao','bai']))
hlen(name)
# 获取name对应的hash中键值对的个数
# print(conn.hlen('m2'))
hkeys(name)
# 获取name对应的hash中所有的key的值
# print(conn.hkeys('m2'))
hvals(name)
# 获取name对应的hash中所有的value的值
# print(conn.hvals('m2'))
hexists(name, key)
# 检查name对应的hash是否存在当前传入的key
# print(conn.hexists('m2','cao'))
hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
print(re.hdel('xxx','sex','name'))
# conn.hdel('m2','key1','key2')
# 这样可以# conn.hdel('m2',*['key1','key2'])# 这样不行# conn.hdel('m2',['key1','key2'])
hincrby用来统计一个东西的数量的频繁增加(name, key, amount=1)
hincrby应用场景:
统计文章阅读数:key是文章id,value是文章阅读数,有一个阅读者,数字加一,固定一个时间,将数据同步到数据库,一定要写日志,避免出错,还能查找到
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)
conn.hincrby('m1','key3')
hincrbyfloat(name, key, amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(浮点数)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
hgetall(name)——慎用,一次性取出数据前需要先hlen看下长度
# 获取name对应hash的所有键值
print(re.hgetall('xxx').get(b'name'))
# 根据key把所有的值取出来
# print(conn.hgetall('m2'))
hscan_iter(name, match=None, count=None),增量迭代取值
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据
# 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# for item in r.hscan_iter('xx'):
# print item
应用场景:
比如我redis中字典有10000w条数据,全部都打印出来
hscan——指定游标,然后取多少值
for i in range(1000):
conn.hset('m2','key%s'%i,'value%s'%i)
指定每次取10条,直到取完
ret=conn.hscan_iter('m2',count=100)
不要用这种方式,一下全部取出,redis可能会被撑爆,或者先用len查看下长度再决定使用getall或者其他
ret=conn.hgetall('m2')
hscan(name, cursor=0, match=None, count=None)——指定游标,然后取多少数据
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而防止内存被撑爆
# 参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
到此这篇关于redis中Hash字典操作的方法的文章就介绍到这了,更多相关redis Hash字典操作内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python redis存入字典序列化存储教程
在python中通过redis hset存储字典时,必须主动把字典通过json.dumps()序列化为字符串后再存储, 不然hget获取后将无法通过json.loads()反序列化为字典 序列化存储 r = redis_conn() r.hset('wait_task', 'one', json.dumps({'project': 'india', 'total_size': '15.8 MB'})) r.hset('wait_task', 'two', json.dumps({'project
-
SpringBoot+Redis实现数据字典的方法
前言 我们在日常的开发过程中针对一些字段采用整型的方式去代替某些具体的含义,比如性别0代表男,1代表女.如果只是一些不会变更的转译我们可以采用常量或者枚举类的方式来实现,但是事实上我们也会遇到那种可能需要变更的,显然这种场景下使用枚举类这种方式是不合理的,那么如何动态地去进行转译呢? 正文 数据字典 数据字典(Data dictionary)是一种用户可以访问的记录数据库和应用程序元数据的目录.主动数据字典是指在对数据库或应用程序结构进行修改时,其内容可以由DBMS自动更新的数据字典.被动数据字
-

Redis数据结构之链表与字典的使用
今天我们来聊一聊Redis中的链表与字典,具体如下: 链表 关于链表的基础概念其实你在学习Redis之前一定积累了不少,所以本文将默认你已经掌握了链表相关的基础知识,而Redis的链表其实也就是普通的链表~ 因为Redis是使用C语言编写的,因此Redis的数据结构的定义都是使用C语法定义的,你不需要完全理解下方C语言声明结构体的语法,但我认为依靠大家的Java知识也能理解这就像是在Java中定义了一个链表对象 Redis链表节点的结构 typedef struct listNode { str
-
redis中Hash字典操作的方法
目录 1.Redis操作之Hash操作 redis hash字典操作 1.Redis操作之Hash操作 redis支持五大数据类型,只支持第一层,也就说字典的value值,必须是字符串 如果value值想存字典,必须用json转换一下,转成字符串 redis hash字典操作 reids:{ k1:'dafdadfasf', m1:{ 'key2':value2, 'key1':value1, } } 1.hset(name, key, value),插入值 # name对应的hash中设置一个
-
Python中的字典及其使用方法
目录 一.使用字典 1.访问字典中的值 2.在字典中添加键值对 3.修改字典中的值 4.删除字典中的键值对 5.由类似对象组成的字典 二.遍历字典 1.遍历字典中的所有键值对 2.遍历字典中的所有键 3.遍历字典中的所有值 三.嵌套 1.字典列表 2.在字典中嵌套列表 3.在字典中嵌套字典 前言: 本文的主要内容是介绍Python中字典及其使用,包括使用字典(添加.删除.修改等操作).遍历字典以及字典与列表之间的嵌套使用,文中附有代码以及相应的运行结果辅助理解. 一.使用字典 在Python中,
-
Android编程实现在adapter中进行数据操作的方法
本文实例讲述了Android编程实现在adapter中进行数据操作的方法.分享给大家供大家参考,具体如下: package com.cvte.apkclassify; import java.util.ArrayList; import android.content.Context; import android.content.pm.ApplicationInfo; import android.content.pm.PackageInfo; import android.content.p
-
python中的字典操作及字典函数
字典 dict_fruit = {'apple':'苹果','banana':'香蕉','cherry':'樱桃','avocado':'牛油果','watermelon':'西瓜'} 字典的操作 #字典的遍历方式 #默认遍历(遍历key) for value in dict_fruit: print(value) ''''' 遍历出的值: watermelon apple cherry avocado banana ''' #使用key遍历(与默认遍历一样) for key in dict_f
-
redis中的事务操作案例分析
本文实例讲述了redis中的事务操作.分享给大家供大家参考,具体如下: redis与mysql的事务 Redis支持简单的事务 简单使用 讲张三的100圆钱转账给lisi: set zhangsan 800 set lisi 100 multi decrby zhangsan 100 incrby lisi 100 exec 失败的两种情况 在mutil后面的语句中, 语句出错可能有2种情况,还是以转账的情况来分析: (1)语法就有问题 127.0.0.1:6379> multi OK 127.
-
Vue中四种操作dom方法保姆级讲解
目录 前言 一.通过ref拿到dom的引用 适用场景 示例代码 二.通过父容器的ref遍历拿到dom引用 适用场景 示例代码 三.通过子组件emit传递ref 适用场景 示例代码 四.通过:ref将dom引用放到数组中 适用场景 示例代码 前言 最近主管提出了许多优化用户体验的要求,其中很多涉及 dom 操作.本文将 Vue3 中常见的 dom 操作总结了一下. 一.通过ref拿到dom的引用 <template> <div class="ref-container"
-
redis中opsForList().range()的使用方法详解
目录 结论(具体测试数据请往下看) 1.环境 redis 2.测试代码: 3.测试数据(假设List长度为N) 4.测试从索引倒数开始 4.1.stringRedisTemplate.opsForList().range(key, -4, -1) 4.2.stringRedisTemplate.opsForList().range(key, -3, -1) 4.3.stringRedisTemplate.opsForList().range(key, -3, -2) 4.4.stringRedi
-
redis中hash表内容删除的方法代码
hash: Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象. Redis 中每个hash可以存储 232 - 1键值对(40多亿). 实例: 127.0.0.1:6379> HMSET runoobkey name "redis tutorial" description "redis basic commands for caching" likes 20 visitors 23000 OK 127.
-
redis中hash数据结构及说明
目录 hash的数据结构 ziplist底层实现 字典 底层实现 扩容 缩容 总结 hash的数据结构 hash底层数据结构的实现包括两种:ziplist和字典当 保存的所有键值对字符串长度小于 64 字节并且键值对数量小于 512 时使用ziplist ,否则使用字典的方式 ziplist底层实现 ziplist是为了提高存储效率而设计的一种特殊编码的双向链表.它可以存储字符串或者整数,存储整数时是采用整数的二进制而不是字符串形式存储. 他能在O(1)的时间复杂度下完成list两端的push和
-
Java中图像锐化操作的方法详解
一.该图像锐化的思想: 本文的图像锐化是将图像中的R,G,B的值分别从原图像中提出,然后将分别将这三个R,G,B的值分别与卷积核进行卷积,最终再将最后的三个卷积的结果合成为一个像素值,从而实现图像的锐化效果. 二.整体的图像锐化的代码为: package com.yf1105; import java.awt.Color; import java.awt.Graphics; import java.awt.image.BufferedImage; import java.io.File; imp