MySQL分区之指定各分区路径详解
目录
- 介绍
- 一、MYISAM存储引擎
- 二、INNODB存储引擎
- 三、子分区
- 1.子分区
- 2.子分区再分
- 总结
介绍
可以针对分区表的每个分区指定各自的存储路径,对于innodb存储引擎的表只能指定数据路径,因为数据和索引是存储在一个文件当中,对于MYISAM存储引擎可以分别指定数据文件和索引文件,一般也只有RANGE、LIST分区、sub子分区才有可能需要单独指定各个分区的路径,HASH和KEY分区的所有分区的路径都是一样。RANGE分区指定路径和LIST分区是一样的,这里就拿LIST分区来做讲解。
一、MYISAM存储引擎
CREATE TABLE th (id INT, adate DATE)
engine='MyISAM'
PARTITION BY LIST(YEAR(adate))
(
PARTITION p1999 VALUES IN (1995, 1999, 2003)
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx',
PARTITION p2000 VALUES IN (1996, 2000, 2004)
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx',
PARTITION p2001 VALUES IN (1997, 2001, 2005)
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx',
PARTITION p2002 VALUES IN (1998, 2002, 2006)
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx'
);
注意:MYISAM存储引擎的数据文件和索引文件是分库存储所以可以为数据文件和索引文件定义各自的路径,INNODB存储引擎只能定义数据路径。
二、INNODB存储引擎
CREATE TABLE thex (id INT, adate DATE)
engine='InnoDB'
PARTITION BY LIST(YEAR(adate))
(
PARTITION p1999 VALUES IN (1995, 1999, 2003)
DATA DIRECTORY = '/data/data',
PARTITION p2000 VALUES IN (1996, 2000, 2004)
DATA DIRECTORY = '/data/data',
PARTITION p2001 VALUES IN (1997, 2001, 2005)
DATA DIRECTORY = '/data/data',
PARTITION p2002 VALUES IN (1998, 2002, 2006)
DATA DIRECTORY = '/data/data'
);
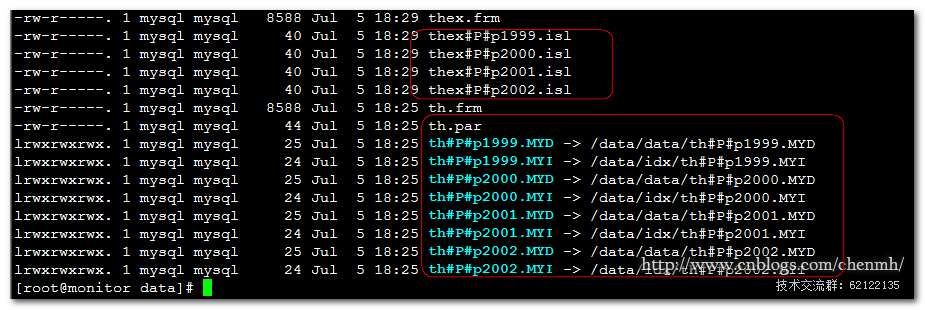
指定路径之后在原来的路径中innodb生成了4个指向数据存储的路径文件,myisam生成了一个th.par文件指明该表是分区表,同时数据文件和索引文件指向了实际的存储路径。
三、子分区
1.子分区
CREATE TABLE tb_sub_dir (id INT, purchased DATE)
ENGINE='MYISAM'
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) ) (
PARTITION p0 VALUES LESS THAN (1990)
(
SUBPARTITION s0
DATA DIRECTORY = '/data/data_sub1'
INDEX DIRECTORY = '/data/idx_sub1',
SUBPARTITION s1
DATA DIRECTORY = '/data/data_sub1'
INDEX DIRECTORY = '/data/idx_sub1'
),
PARTITION p1 VALUES LESS THAN (2000)
(
SUBPARTITION s2
DATA DIRECTORY = '/data/data_sub2'
INDEX DIRECTORY = '/data/idx_sub2',
SUBPARTITION s3
DATA DIRECTORY = '/data/data_sub2'
INDEX DIRECTORY = '/data/idx_sub2'
),
PARTITION p2 VALUES LESS THAN MAXVALUE
(
SUBPARTITION s4
DATA DIRECTORY = '/data/data_sub3'
INDEX DIRECTORY = '/data/idx_sub3',
SUBPARTITION s5
DATA DIRECTORY = '/data/data_sub3'
INDEX DIRECTORY = '/data/idx_sub3'
)
);
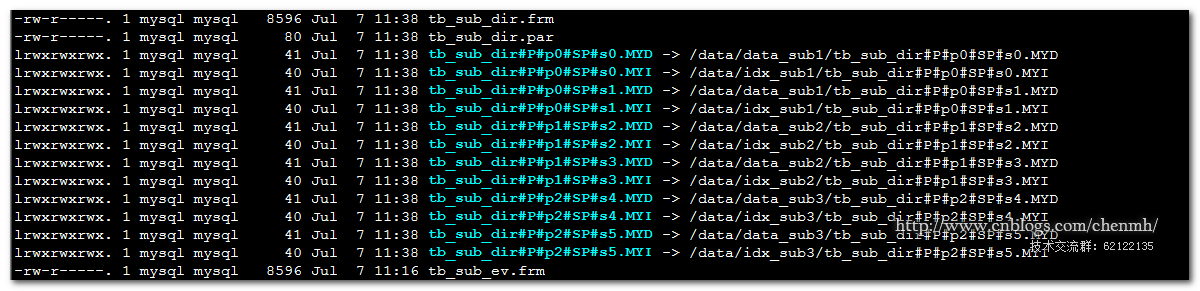
2.子分区再分
CREATE TABLE tb_sub_dirnew (id INT, purchased DATE)
ENGINE='MYISAM'
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) ) (
PARTITION p0 VALUES LESS THAN (1990)
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx'
(
SUBPARTITION s0
DATA DIRECTORY = '/data/data_sub1'
INDEX DIRECTORY = '/data/idx_sub1',
SUBPARTITION s1
DATA DIRECTORY = '/data/data_sub1'
INDEX DIRECTORY = '/data/idx_sub1'
),
PARTITION p1 VALUES LESS THAN (2000)
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx'
(
SUBPARTITION s2
DATA DIRECTORY = '/data/data_sub2'
INDEX DIRECTORY = '/data/idx_sub2',
SUBPARTITION s3
DATA DIRECTORY = '/data/data_sub2'
INDEX DIRECTORY = '/data/idx_sub2'
),
PARTITION p2 VALUES LESS THAN MAXVALUE
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx'
(
SUBPARTITION s4
DATA DIRECTORY = '/data/data_sub3'
INDEX DIRECTORY = '/data/idx_sub3',
SUBPARTITION s5
DATA DIRECTORY = '/data/data_sub3'
INDEX DIRECTORY = '/data/idx_sub3'
)
);
也可以给个分区指定路径后再给子分区指定路径,但是这样没有意义,因为数据的存在都是由子分区决定的。
注意:
1.指定的路径必须存在,否则分区无法创建成功
2.MYISAM存储引擎的数据文件和索引文件是分库存储所以可以为数据文件和索引文件定义各自的路径,INNODB存储引擎只能定义数据路径
分区系列文章:
RANGE分区:https://www.jb51.net/article/244269.htm
COLUMN分区:https://www.jb51.net/article/96515.htm
LIST分区:https://www.jb51.net/article/244256.htm
HASH分区:https://www.jb51.net/article/244277.htm
KEY分区:https://www.jb51.net/article/244282.htm
子分区:https://www.jb51.net/article/244294.htm
指定各分区路径:https://www.jb51.net/article/244296.htm
分区索引以及分区介绍总结:https://www.jb51.net/article/244300.htm
总结
通过给各个分区指定各自的磁盘可以有效的提高读写性能,在条件允许的情况下是一个不错的方法。
到此这篇关于MySQL分区之指定各分区路径的文章就介绍到这了,更多相关MySQL指定各分区路径 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL分区表的正确使用方法
MySQL分区表概述 我们经常遇到一张表里面保存了上亿甚至过十亿的记录,这些表里面保存了大量的历史记录. 对于这些历史数据的清理是一个非常头疼事情,由于所有的数据都一个普通的表里.所以只能是启用一个或多个带where条件的delete语句去删除(一般where条件是时间). 这对数据库的造成了很大压力.即使我们把这些删除了,但底层的数据文件并没有变小.面对这类问题,最有效的方法就是在使用分区表.最常见的分区方法就是按照时间进行分区. 分区一个最大的优点就是可以非常高效的进行历史数据的清理. 1.
-
mysql中如何判断是否支持分区
mysql可以通过下面语句判断是否支持分区: SHOW VARIABLES LIKE '%partition%'; 如果输出: have_partitioning YES 表示支持分区. 或者通过: SHOW PLUGINS; 显示所有插件,如果有partition ACTIVE STORAGE ENGINE GPL 插件则表明支持分区 ps:什么是数据库分区 前段时间写过一篇关于mysql分表的的文章,下面来说一下什么是数据库分区,以mysql为例.mysql数据库中的数据是以文件的形势存
-
mysql的分区技术详细介绍
一.概述 当 MySQL的总记录数超过了100万后,会出现性能的大幅度下降吗?答案是肯定的,但是,性能下降>的比率不一而同,要看系统的架构.应用程序.还有>包括索引.服务器硬件等多种因素而定.当有网友问我这个问题的时候,我最常见的回答>就是:分表,可以根据id区间或者时间先后顺序等多种规则来分表.分表很容易,然而由此所带来的应用程序甚至是架构方面的改动工作却不>容小觑,还包括将来的扩展性等. 在以前,一种解决方案就是使用 MERGE 类型,这是一个非常方便的做饭.架构和程序基本上不
-
基于MySQL分区性能的详细介绍
一, 分区概念 分区允许根据指定的规则,跨文件系统分配单个表的多个部分.表的不同部分在不同的位置被存储为单独的表.MySQL从5.1.3开始支持Partition. 分区和手动分表对比 手动分表 分区 多张数据表 一张数据表 重复数据的风险 没有数据重复的风险 写入多张表 写入一张表 没有统一的约束限制 强制的约束限制 MySQL支持RANGE,LIST,HASH,KEY分区类型,其中以RANGE最为常用: Range(范围)–这种模式允许将数据划分不同范围.例如可以将一个表通过年
-
创建mysql表分区的方法
表分区是最近才知道的哦 ,以前自己做都是分表来实现上亿级别的数据了,下面我来给大家介绍一下mysql表分区创建与使用吧,希望对各位同学会有所帮助.表分区的测试使用,主要内容来自于其他博客文章以及mysql5.1的参考手册mysql测试版本:mysql5.5.28mysql物理存储文件(有mysql配置的datadir决定存储路径)格式简介数据库engine为MYISAM frm表结构文件,myd表数据文件,myi表索引文件.INNODB engine对应的表物理存储文件innodb的数据库的物理
-
mysql使用教程之分区表的使用方法(删除分区表)
MySQL使用分区表的好处: 1,可以把一些归类的数据放在一个分区中,可以减少服务器检查数据的数量加快查询.2,方便维护,通过删除分区来删除老的数据.3,分区数据可以被分布到不同的物理位置,可以做分布式有效利用多个硬盘驱动器. MySQL可以建立四种分区类型的分区: RANGE 分区:基于属于一个给定连续区间的列值,把多行分配给分区. LIST 分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择. www.jb51.net HASH分区:基于用户
-
MySql数据分区操作之新增分区操作
如果想在已经建好的表上进行分区,如果使用alter添加分区的话,mysql会提示错误: 复制代码 代码如下: ERROR 1505 <HY000> Partition management on a not partitioned table is not possible 正确的方法是新建一个具有分区的表,结构一致,然后用insert into 分区表 select * from 原始表; 测试创建分区表文件 复制代码 代码如下: CREATE TABLE tr (id INT, name
-
MySQL的表分区详解
一.什么是表分区通俗地讲表分区是将一大表,根据条件分割成若干个小表.mysql5.1开始支持数据表分区了.如:某用户表的记录超过了600万条,那么就可以根据入库日期将表分区,也可以根据所在地将表分区.当然也可根据其他的条件分区. 二.为什么要对表进行分区为了改善大型表以及具有各种访问模式的表的可伸缩性,可管理性和提高数据库效率.分区的一些优点包括: 1).与单个磁盘或文件系统分区相比,可以存储更多的数据. 2).对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的
-

MySQL分区之指定各分区路径详解
目录 介绍 一.MYISAM存储引擎 二.INNODB存储引擎 三.子分区 1.子分区 2.子分区再分 总结 介绍 可以针对分区表的每个分区指定各自的存储路径,对于innodb存储引擎的表只能指定数据路径,因为数据和索引是存储在一个文件当中,对于MYISAM存储引擎可以分别指定数据文件和索引文件,一般也只有RANGE.LIST分区.sub子分区才有可能需要单独指定各个分区的路径,HASH和KEY分区的所有分区的路径都是一样.RANGE分区指定路径和LIST分区是一样的,这里就拿LIST分区来做讲
-
mysql表名忽略大小写配置方法详解
linux下mysql默认是要区分表名大小写的.mysql是否区分大小写设置是由参数lower_case_table_names决定的,其中: 1)lower_case_table_names = 0 区分大小写(即对大小写不敏感),默认是这种设置.这样设置后,在mysql里创建的表名带不带大写字母都没有影响,都可以正常读出和被引用. 2)lower_case_table_names = 1 不区分大小写(即对大小写敏感).这样设置后,表名在硬盘上以小写保存,MySQL将所有表名转换为小写存
-
MySQL数据类型中DECIMAL的用法实例详解
MySQL数据类型中DECIMAL的用法实例详解 在MySQL数据类型中,例如INT,FLOAT,DOUBLE,CHAR,DECIMAL等,它们都有各自的作用,下面我们就主要来介绍一下MySQL数据类型中的DECIMAL类型的作用和用法. 一般赋予浮点列的值被四舍五入到这个列所指定的十进制数.如果在一个FLOAT(8, 1)的列中存储1. 2 3 4 5 6,则结果为1. 2.如果将相同的值存入FLOAT(8, 4) 的列中,则结果为1. 2 3 4 6. 这表示应该定义具有足够位数的浮点列以便
-
JDBC连接mysql处理中文时乱码解决办法详解
JDBC连接mysql处理中文时乱码解决办法详解 近日,整合的项目需要跟一个比较老版本的mysql服务器连接,使用navicat查看,发现此mysql服务器貌似没有设置默认编码,而且从操作此mysql的部分php文件看,应该是使用的gb2312的编码,但是,直接使用jdbc操作,从库中读取出来的中文全都是乱码. 一开始,使用类似entity.setDepartName(new String(rs.getString("hg").getBytes("gbk"), &q
-
MySQL数据备份之mysqldump的使用详解
mysqldump常用于MySQL数据库逻辑备份. 1.各种用法说明 A. 最简单的用法: mysqldump -uroot -pPassword [database name] > [dump file] 上述命令将指定数据库备份到某dump文件(转储文件)中,比如: mysqldump -uroot -p123 test > test.dump 生成的test.dump文件中包含建表语句(生成数据库结构哦)和插入数据的insert语句. B. --opt 如果加上--opt参数则生成的du
-
Mysql优化order by语句的方法详解
本篇文章我们将了解ORDER BY语句的优化,在此之前,你需要对索引有基本的了解,不了解的老少爷们可以先看一下我之前写过的索引相关文章.现在让我们开始吧. MySQL中的两种排序方式 1.通过有序索引顺序扫描直接返回有序数据 因为索引的结构是B+树,索引中的数据是按照一定顺序进行排列的,所以在排序查询中如果能利用索引,就能避免额外的排序操作.EXPLAIN分析查询时,Extra显示为Using index. 2.Filesort排序,对返回的数据进行排序 所有不是通过索引直接返回排序结果的操作都
-
对python for 文件指定行读写操作详解
1.os.mknod("test.txt") #创建空文件 2.fp = open("test.txt",w) #直接打开一个文件,如果文件不存在则创建文件 3.关于open 模式: 详情: w:以写方式打开, a:以追加模式打开 (从 EOF 开始, 必要时创建新文件) r+:以读写模式打开 w+:以读写模式打开 (参见 w ) a+:以读写模式打开 (参见 a ) rb:以二进制读模式打开 wb:以二进制写模式打开 (参见 w ) ab:以二进制追加模式打开 (
-
android studio 打包自动生成版本号与日期,apk输入路径详解
一. 打开项目选择如图示1 (build.gradle 项目位置) 二. 1. build.gradle 文件添加内容如下.gradle是[com.android.tools.build:gradle:3.0.0 以下版本] android{ defaultConfig {...} 自动追加版本号和版本名称 android.applicationVariants.all { variant->variant.outputs.each { output-> output.outputFile =
-
Mysql联表update数据的示例详解
1.MySQL UPDATE JOIN语法 在MySQL中,可以在 UPDATE语句 中使用JOIN子句执行跨表更新.MySQL UPDATE JOIN的语法如下: UPDATE T1, T2, [INNER JOIN | LEFT JOIN] T1 ON T1.C1 = T2. C1 SET T1.C2 = T2.C2, T2.C3 = expr WHERE condition 更详细地看看MySQL UPDATE JOIN语法: 首先,在UPDATE子句之后,指定主表(T1)和希望主表连接表
-
mysql中decimal数据类型小数位填充问题详解
前言 在开发过程中,我们往往会用到decimal数据类型.因为decimal是MySQL中存在的精准数据类型. MySQL中的数据类型有:float,double等非精准数据类型和decimal这种精准. 区别:float,double等非精准类型,在DB中保存的是近似值. Decimal则以字符串的形式保存精确的原始数值. decimal介绍: decimal(a,b) 其中:a指定指定小数点左边和右边可以存储的十进制数字的最大个数,最大精度38.b指定小数点右边可以存储的十进制数字的最大个数