Python实现计算AUC的示例代码
目录
- 为什么这样一个指标可以衡量分类效果
- auc理解
- AUC计算
- 方法一
- 方法二
- 实现及验证
AUC(Area under curve)是机器学习常用的二分类评测手段,直接含义是ROC曲线下的面积,如下图:

要理解这张图的含义,得先理解下面这个表:
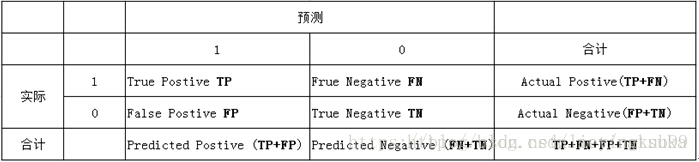
表中列代表预测分类,行代表实际分类:
- 实际1,预测1:真正类(tp)
- 实际1,预测0:假负类(fn)
- 实际0,预测1:假正类(fp)
- 实际0,预测0:真负类(tn)
- 真实负样本总数=n=fp+tn
- 真实正样本总数=p=tp+fn
在第一张图中,
横坐标false positive rate 代表假正类率,由fp/n计算得到,
意为 在实际负样本中出现预测正样本的概率。
纵坐标true positive rate 代表真正类率,由tp/p计算得到,
意为 在实际正样本中出现预测正样本的概率。
为什么这样一个指标可以衡量分类效果
先来看看如何得到这条曲线:
1. 通过分类器得到每个样本的预测概率,对其从高到低进行排序
2. 从高到低,分别以每一个预测概率作为阈值,大于该阈值的认定其为1,小于的为0,计算fp rate和tp rate。
对于一个有分类效果(效果比随机要好)的分类器,刚开始将高概率作为阈值时,阈值以上的真正样本占全部正样本的比例(tp rate)>阈值以上的假正样本占全部负样本的比例(fp rate)。
auc理解
auc就是:随机抽出一对样本(一个正样本,一个负样本),然后用训练得到的分类器来对这两个样本进行预测,预测得到正样本的概率大于负样本概率的概率。
AUC计算
方法一
在有M个正样本,N个负样本的数据集里。一共有M*N对样本(一对样本即,一个正样本与一个负样本)。统计这M*N对样本里,正样本的预测概率大于负样本的预测概率的个数。

举个例子:

假设有4条样本。2个正样本,2个负样本,那么M*N=4。
即总共有4个样本对。分别是:
(D,B),(D,A),(C,B),(C,A)。
在(D,B)样本对中,正样本D预测的概率大于负样本B预测的概率(也就是D的得分比B高),记为1
同理,对于(C,B)。正样本C预测的概率小于负样本C预测的概率,记为0.
那么auc如下:

假如出现得分一致的时候:

同样本是4个样本对,对于样本对(C,B)其I值为0.5。
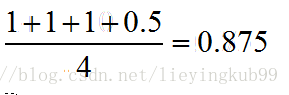
方法二
利公式:
● 对预测概率从高到低排序
● 对每一个概率值设一个rank值(最高的概率的rank为n,第二高的为n-1)
● rank实际上代表了该score(预测概率)超过的样本的数目
为了求的组合中正样本的score值大于负样本,如果所有的正样本score值都是大于负样本的,那么第一位与任意的进行组合score值都要大,我们取它的rank值为n,但是n-1中有M-1是正样例和正样例的组合这种是不在统计范围内的(为计算方便我们取n组,相应的不符合的有M个),所以要减掉,那么同理排在第二位的n-1,会有M-1个是不满足的,依次类推,故得到后面的公式M*(M+1)/2,我们可以验证在正样本score都大于负样本的假设下,AUC的值为1
● 除以M*N

举例说明:

排序。按概率排序后得到:
按照上面的公式,只把正样本的序号加起来也就是只把样本C,D的rank值加起来后减去一个常数项:

得到:

如果出现得分一样的情况:

假如有4个取值概率为0.5,而且既有正样本也有负样本的情况。计算的时候,其实原则就是相等得分的rank取平均值。具体来说如下:
先排序:

这里需要注意的是:相等概率得分的样本,无论正负,谁在前,谁在后无所谓。
由于只考虑正样本的rank值:
对于正样本A,其rank值为7
对于正样本B,其rank值为6
对于正样本E,其rank值为(5+4+3+2)/4
对于正样本F,其rank值为(5+4+3+2)/4

实现及验证
采用sklearn中的库函数验证:
import numpy as np
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
#---自己按照公式实现
def auc_calculate(labels,preds,n_bins=100):
postive_len = sum(labels)
negative_len = len(labels) - postive_len
total_case = postive_len * negative_len
pos_histogram = [0 for _ in range(n_bins)]
neg_histogram = [0 for _ in range(n_bins)]
bin_width = 1.0 / n_bins
for i in range(len(labels)):
nth_bin = int(preds[i]/bin_width)
if labels[i]==1:
pos_histogram[nth_bin] += 1
else:
neg_histogram[nth_bin] += 1
accumulated_neg = 0
satisfied_pair = 0
for i in range(n_bins):
satisfied_pair += (pos_histogram[i]*accumulated_neg + pos_histogram[i]*neg_histogram[i]*0.5)
accumulated_neg += neg_histogram[i]
return satisfied_pair / float(total_case)
if __name__ == '__main__':
y = np.array([1,0,0,0,1,0,1,0,])
pred = np.array([0.9, 0.8, 0.3, 0.1,0.4,0.9,0.66,0.7])
fpr, tpr, thresholds = roc_curve(y, pred, pos_label=1)
print("-----sklearn:",auc(fpr, tpr))
print("-----py脚本:",auc_calculate(y,pred))

AUC的优点:
它不受类别不平衡问题的影响,不同的样本比例不会影响AUC的评测结果。在训练时,可以直接使用AUC作为损失函数。
到此这篇关于Python实现计算AUC的示例代码的文章就介绍到这了,更多相关Python计算AUC内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
AUC计算方法与Python实现代码
-AUC计算方法 -AUC的Python实现方式 AUC计算方法 AUC是ROC曲线下的面积,它是机器学习用于二分类模型的评价指标,AUC反应的是模型对样本的排序能力.它的统计意义是从所有正样本随机抽取一个正样本,从所有负样本随机抽取一个负样本,当前score使得正样本排在负样本前面的概率. AUC的计算主要以下几种方法: 1.计算ROC曲线下的面积.这是比较直接的一种方法,可以近似计算ROC曲线一个个小梯形的面积.几乎不会用这种方法 2.从AUC统计意义去计算.所有的正负样本对中,正样本排在负
-
python计算auc的方法
1.安装scikit-learn 1.1 Scikit-learn 依赖 Python (>= 2.6 or >= 3.3), NumPy (>= 1.6.1), SciPy (>= 0.9). 分别查看上述三个依赖的版本: python -V 结果: Python 2.7.3 python -c 'import scipy; print scipy.version.version' scipy版本结果: 0.9.0 python -c "import numpy; pr
-
python计算auc指标实例
1.安装scikit-learn 1.1Scikit-learn 依赖 Python (>= 2.6 or >= 3.3), NumPy (>= 1.6.1), SciPy (>= 0.9). 分别查看上述三个依赖的版本, python -V 结果:Python 2.7.3 python -c 'import scipy; print scipy.version.version' scipy版本结果:0.9.0 python -c "import numpy; print
-

利用Python画ROC曲线和AUC值计算
前言 ROC(Receiver Operating Characteristic)曲线和AUC常被用来评价一个二值分类器(binary classifier)的优劣.这篇文章将先简单的介绍ROC和AUC,而后用实例演示如何python作出ROC曲线图以及计算AUC. AUC介绍 AUC(Area Under Curve)是机器学习二分类模型中非常常用的评估指标,相比于F1-Score对项目的不平衡有更大的容忍性,目前常见的机器学习库中(比如scikit-learn)一般也都是集成该指标的计算,但
-
利用python画出AUC曲线的实例
以load_breast_cancer数据集为例,模型细节不重要,重点是画AUC的代码. 直接上代码: from sklearn.datasets import load_breast_cancer from sklearn import metrics from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split import pylab as p
-
Python实现计算AUC的示例代码
目录 为什么这样一个指标可以衡量分类效果 auc理解 AUC计算 方法一 方法二 实现及验证 AUC(Area under curve)是机器学习常用的二分类评测手段,直接含义是ROC曲线下的面积,如下图: 要理解这张图的含义,得先理解下面这个表: 表中列代表预测分类,行代表实际分类: 实际1,预测1:真正类(tp) 实际1,预测0:假负类(fn) 实际0,预测1:假正类(fp) 实际0,预测0:真负类(tn) 真实负样本总数=n=fp+tn 真实正样本总数=p=tp+fn 在第一张图中, 横坐
-
Python实现计算信息熵的示例代码
目录 一:数据集准备 二:信息熵计算 三:完整源码分享 四:方法补充 一:数据集准备 如博主使用的是: 多层感知机(MLP)实现考勤预测二分类任务(sklearn)对应数据集 导入至工程下 二:信息熵计算 1 导包 from math import log import pandas as pd 2 读取数据集 dataSet = pd.read_csv('dataSet.csv', header=None).values.tolist() 3 数据统计 numEntries = len(dat
-
Python实现计算AUC的三种方式总结
目录 介绍 实现代码 方法补充 介绍 AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1.又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间.AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值. auc计算方式:参考Python实现计算AUC的示例代码 实现代码 import numpy as np from sklearn.metrics import roc_auc_sc
-
python 实时调取摄像头的示例代码
调取摄像头的实现 import numpy as np import cv2 cap = cv2.VideoCapture(0) #参数为0时调用本地摄像头:url连接调取网络摄像头:文件地址获取本地视频 while(True): ret,frame=cap.read() #灰度化 gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY) cv2.imshow('frame',gray) #普通图片 cv2.imshow('frame',frame) if cv2.
-
python实现自幂数的示例代码
1.什么是自幂数? 前文介绍过 python 实现水仙花数,其实水仙花数为自幂数的一种,即,3位自幂数. 自幂数是指一个 n 位数,它的每个位上的数字的 n 次幂之和等于它本身.(例如:当n为3时,有1^3 + 5^3 + 3^3 = 153,153即是n为3时的一个自幂数) 自幂数-百度百科 2.自幂数包括: 一位自幂数:独身数 0-9 两位自幂数:没有 三位自幂数:水仙花数 153,370,371,407 四位自幂数:四叶玫瑰数 1634,8208,9474 五位自幂数:五角星数 54748
-
Python实现端口扫描器的示例代码
目录 socket概念 socket基本用法 创建tcp套接字 实现端口扫描 socket概念 socket又称套接字,可以看做是不同主机之间的进程进⾏双向通信的端点,简单的说就是通信的两⽅的⼀种约定,⽤套接字中的相关函数来完成通信过程,发出网络请求或者应答网络请求. socket起源于Unix,⽽Unix/Linux基本哲学之⼀就是"⼀切皆⽂件",对于⽂件⽤"打开"."读写"."关闭"模式来操作.而socket就是该模式的⼀
-
Python实战之外星人入侵游戏示例代码
目录 0.前言 1.效果展示 2.实现代码 2.1 image 2.2 alien_invasion.py 2.3 alien.py 2.4 bullet.py 2.5 button.py 2.6 game_stats.py 2.7 scoreboarf.py 2.8 settings.py 2.9 ship.py 0.前言 最近学习的python第一个项目实战,<外星人入侵>,成功实现所有功能,给大家提供源代码 环境安装:python 3.7+ pygame 安装 pygame pip in
-
Python实现生命游戏的示例代码(tkinter版)
目录 生命游戏(Game of Life) 游戏概述 生存定律 图形结构 代码实现 运行界面 使用简介 后续改进 生命游戏(Game of Life) 由剑桥大学约翰·何顿·康威设计的计算机程序.美国趣味数学大师马丁·加德纳(Martin Gardner,1914-2010)通过<科学美国人>杂志,将康威的生命游戏介绍给学术界之外的广大渎者,一时吸引了各行各业一大批人的兴趣,这时细胞自动机课题才吸引了科学家的注意. 游戏概述 用一个二维表格表示“生存空间”,空间的每个方格中都可放置一个生命细胞
-
Python实现梯度下降法的示例代码
目录 1.首先读取数据集 2.初始化相关参数 3.定义计算代价函数–>MSE 4.梯度下降 5.执行 1.首先读取数据集 导包并读取数据,数据自行任意准备,只要有两列,可以分为自变量x和因变量y即可即可. import numpy as np import matplotlib.pyplot as plt data = np.loadtxt("data.csv", delimiter=",") x_data = data[:, 0] y_data = data
-
Python实现简易计算器的示例代码
目录 实现流程 计算器布局 计算机执行 代码展示 运行展示 上次我用我学习的python做一个简易的计算器,我对计算器进行了,更改优化,变成了一个真正的计算器 实现流程 1.计算机布局 2.计算机执行 首先导入模块: Tkinter 作为 Python GUI 开发工具之一,它具有 GUI 软件包的必备的常用功能.比如,它提供了十多种不同类型的窗口控件.窗口布局管理器.事件处理机制等,加之其开发效率高.代码简洁易读 import tkinter as tk #Python3标准安装包中自带tki