Python 的矩阵传播机制Broadcasting和矩阵运算
目录
- 一、Python的矩阵传播机制(Broadcasting)
- 二、下面展示什么是python的传播机制
- 三、利用numpy的内置函数对矩阵进行操作
- 四、定义自己的函数来处理矩阵
- 五、总结
一、Python的矩阵传播机制(Broadcasting)
我们知道在深度学习中经常要操作各种矩阵(matrix) 。回想一下,我们在操作数组(list)的时候,经常习惯于用**for循环(for-loop)**来对数组的每一个元素进行操作。例如:
my_list = [1,2,3,4] new_list = [] for each in my_list: new_list.append(each*2) print(new_list) # 输出 [2,3,4,5]
如果是矩阵呢:
my_matrix = [[1,2,3,4], [5,6,7,8]] new_matrix = [[],[]] for i in range(2): for j in range(4): new_matrix[i].append(my_matrix[i][j]*2) print(new_matrix)# 输出 [[2, 4, 6, 8], [10, 12, 14, 16]]
实际上,上面的做法是十分的低效的!数据量小的话还不明显,如果数据量大了,尤其是深度学习中我们处理的矩阵往往巨大,那用for循环去跑一个矩阵,可能要你几个小时甚至几天。
Python考虑到了这一点,这也是本文主要想介绍的**“Python的broadcasting”即传播机制**。
先说一句,python中定义矩阵、处理矩阵,我们一般都用numpy这个库。
二、下面展示什么是python的传播机制
import numpy as np# 先定义一个3×3矩阵 A:
A = np.array(
[[1,2,3],
[4,5,6],
[7,8,9]])
print("A:\n",A)
print("\nA*2:\n",A*2) # 直接用A乘以2
print("\nA+10:\n",A+10) # 直接用A加上10
运行结果:
A:
[[1 2 3]
[4 5 6]
[7 8 9]]A*2:
[[ 2 4 6]
[ 8 10 12]
[14 16 18]]A+10:
[[11 12 13]
[14 15 16]
[17 18 19]]
接着,再看看矩阵×(+)矩阵:
#定义一个3×1矩阵(此时也可叫向量了)
B = np.array([[10],
[100],
[1000]])
print("\nB:\n",B)
print("\nA+B:\n",A+B)
print("\nA*B:\n",A*B)
运行结果:
B:
[[ 10]
[ 100]
[1000]]A+B:
[[ 11 12 13]
[ 104 105 106]
[1007 1008 1009]]A*B:
[[ 10 20 30]
[ 400 500 600]
[7000 8000 9000]]
可见,虽然A和B的形状不一样,一个是3×3,一个是3×1,但是我们在python中可以直接相加、相乘,相减相除也可以。也许看到这,大家都对broadcasting有感觉了。
用一个图来示意一下:
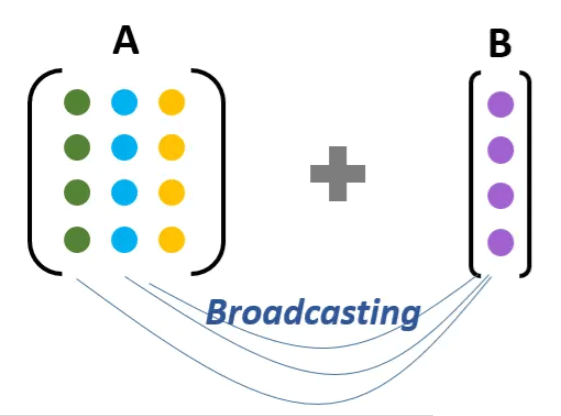
所谓“传播”,就是把一个数或者一个向量进行“复制”,从而作用到矩阵的每一个元素上。
有了这种机制,那进行向量和矩阵的运算,就太方便了!理解了传播机制,就可以随心所欲地对矩阵进行各种便捷的操作了。
三、利用numpy的内置函数对矩阵进行操作
numpy内置了很多的数学函数,例如np.log(),np.abs(),np.maximum()等等上百种。直接把矩阵丢进去,就可以算出新矩阵! 示例:
print(np.log(A))
输出把A矩阵每一个元素求log后得到的新矩阵:
array([[0. , 0.69314718, 1.09861229], [1.38629436, 1.60943791, 1.79175947], [1.94591015, 2.07944154, 2.19722458]])
再比如深度学习中常用的ReLU激活函数,就是y=max(0,x),

也可以对矩阵直接运算:
X = np.array([[1,-2,3,-4], [-9,4,5,6]])Y = np.maximum(0,X)print(Y)
得到:
[[1 0 3 0] [0 4 5 6]]
更多的numpy数学函数,可以参见文档
四、定义自己的函数来处理矩阵
其实这才是我写下本文的目的。。。前面扯了这么多,只是做个铺垫( /ω\)
我昨天遇到个问题,就是我要对ReLU函数求导,易知,y=max(0,x)的导函数是:y’ = 0 if x<0 y’ = 1 if x>0 但是这个y’(x)numpy里面没有定义,需要自己构建。即,我需要将矩阵X中的小于0的元素变为0,大于0的元素变为1。搞了好久没弄出来,后来在StackOverflow上看到了解决办法:
def relu_derivative(x): x[x<0] = 0 x[x>0] = 1 return x X = np.array([[1,-2,3,-4], [-9,4,5,6]]) print(relu_derivative(X))
输出:
[[1 0 1 0]
[0 1 1 1]]
**居然这么简洁就出来了!!!**ミ゚Д゚彡 (゚Д゚#)
这个函数relu_derivative中最难以理解的地方,就是**x[x>0]**了。于是我试了一下:
X = np.array([[1,-2,3,-4], [-9,4,5,6]]) print(X[X>0]) print(X[X<0])
输出:
[1 3 4 5 6]
[-2 -4 -9]
它直接把矩阵X中满足条件的元素取了出来!原来python对矩阵还有这种操作!
所以可以这么理解,X[X>0]相当于一个“选择器”,把满足条件的元素选出来,然后直接全部赋值。
用这种方法,我们便可以定义各种各样我们需要的函数,然后对矩阵整体进行更新操作了!
五、总结
可以看出,python以及numpy对矩阵的操作简直神乎其神,方便快捷又实惠。其实上面忘了写一点,那就是计算机进行矩阵运算的效率要远远高于用for-loop来运算,
不信可以用跑一跑:
# vetorization vs for loop
# define two arrays a, b:
a = np.random.rand(1000000)
b = np.random.rand(1000000)
# for loop version:
t1 = time.time()
c = 0
for i in range(1000000):
c += a[i]*b[i]
t2 = time.time()
print(c)
print("for loop version:"+str(1000*(t2-t1))+"ms")
time1 = 1000*(t2-t1)
# vectorization version:
t1 = time.time()
c = np.dot(a,b)
t2 = time.time()
print(c)
print("vectorization version:"+str(1000*(t2-t1))+"ms")
time2 = 1000*(t2-t1)
print("vectorization is faster than for loop by "+str(time1/time2)+" times!")
运行结果:
249765.8415288075
for loop version:627.4442672729492ms
249765.84152880745
vectorization version:1.5032291412353516ms
vectorization is faster than for loop by 417.39762093576525 times!
可见,用for方法和向量化方法,计算结果是一样,但是后者比前者快了400多倍!
因此,在计算量很大的时候,我们要尽可能想办法对数据进行Vectorizing,即“向量化” ,以便让计算机进行矩阵运算。
到此这篇关于Python 的矩阵传播机制Broadcasting和矩阵运算的文章就介绍到这了,更多相关Python矩阵传播内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python 写了个新型冠状病毒疫情传播模拟程序
病毒扩散仿真程序,用 python 也可以. 概述 事情是这样的,B 站 UP 主 @ele 实验室,写了一个简单的疫情传播仿真程序,告诉大家在家待着的重要性,视频相信大家都看过了,并且 UP 主也放出了源码. 因为是 Java 开发的,所以开始我并没有多加关注.后来看到有人解析代码,发现我也能看懂,然后就琢磨用 Python 应该怎么实现. Java 版程序浅析 一个人就是 1 个(x, y)坐标点,并且每个人有一个状态. public class Person extends Point {
-
Python实现的人工神经网络算法示例【基于反向传播算法】
本文实例讲述了Python实现的人工神经网络算法.分享给大家供大家参考,具体如下: 注意:本程序使用Python3编写,额外需要安装numpy工具包用于矩阵运算,未测试python2是否可以运行. 本程序实现了<机器学习>书中所述的反向传播算法训练人工神经网络,理论部分请参考我的读书笔记. 在本程序中,目标函数是由一个输入x和两个输出y组成, x是在范围[-3.14, 3.14]之间随机生成的实数,而两个y值分别对应 y1 = sin(x),y2 = 1. 随机生成一万份训练样例,经过网络的学
-

python中异常的传播详解
目录 1.异常的传播 2.如何处理异常 1.异常的传播 当在函数中出现异常时,如果在函数中对异常进行了处理,则异常不会再继续传播.如果函数中没有对异常进行处理,则异常会继续向函数调用者传播.如果函数调用者处理了异常,则不再传播,如果还没有处理,则继续向他的调用者传播,直到传递到全局作用域(主模块)如果依然没有处理,则程序终止,并且显示异常信息到控制台.所以异常的传播我们也称之为抛出异常. 异常传播示例如下: def fn1(): print('Hello fn') print(10/0) def
-
Python实现新型冠状病毒传播模型及预测代码实例
1.传染及发病过程 一个健康人感染病毒后进入潜伏期(时间长度为Q天),潜伏期之后进入发病期(时间长度为D天),发病期之后该患者有三个可能去向,分别是自愈.接收隔离.死亡. 2.模型假设 潜伏期Q=7天,根据报道潜伏期为2~14天,取中间值:发病期D=10天,根据文献报告,WHO认定SARS发病期为10天,假设武汉肺炎与此相同:潜伏期的患者不具有将病毒传染给他人的能力:发病期的患者具有将病毒传染给他人的能力:患者在发病期之后不再具有将病毒传染他人的能力:假设处于发病期的患者平均每天密切接触1人,致
-
python里反向传播算法详解
反向传播的目的是计算成本函数C对网络中任意w或b的偏导数.一旦我们有了这些偏导数,我们将通过一些常数 α的乘积和该数量相对于成本函数的偏导数来更新网络中的权重和偏差.这是流行的梯度下降算法.而偏导数给出了最大上升的方向.因此,关于反向传播算法,我们继续查看下文. 我们向相反的方向迈出了一小步--最大下降的方向,也就是将我们带到成本函数的局部最小值的方向. 图示演示: 反向传播算法中Sigmoid函数代码演示: # 实现 sigmoid 函数 return 1 / (1 + np.exp(-x))
-
Python 的矩阵传播机制Broadcasting和矩阵运算
目录 一.Python的矩阵传播机制(Broadcasting) 二.下面展示什么是python的传播机制 三.利用numpy的内置函数对矩阵进行操作 四.定义自己的函数来处理矩阵 五.总结 一.Python的矩阵传播机制(Broadcasting) 我们知道在深度学习中经常要操作各种矩阵(matrix) .回想一下,我们在操作数组(list)的时候,经常习惯于用**for循环(for-loop)**来对数组的每一个元素进行操作.例如: my_list = [1,2,3,4] new_list
-
Python中矩阵创建和矩阵运算方法
矩阵创建 1.from numpyimport *; a1=array([1,2,3]) a2=mat(a1) 矩阵与方块列表的区别如下: 2.data2=mat(ones((2,4))) 创建一个2*4的1矩阵,默认是浮点型的数据,如果需要时int类型,可以使用dtype=int 3.data5=mat(random.randint(2,8,size=(2,5)) 产生一个2-8之间的随机整数矩阵 4.data3=mat(random.rand(2,2)) 这里的random模块使用的是num
-
对Python 中矩阵或者数组相减的法则详解
最近在做编程练习,发现有些结果的值与答案相差较大,通过分析比较得出结论,大概过程如下: 定义了一个计算损失的函数: def error(yhat,label): yhat = np.array(yhat) label = np.array(label) error_sum = ((yhat - label)**2).sum() return error_sum 主要出现问题的是 yhat - label 部分,要强调的是一定要保证两者维度是相同的!这点很重要,否则就会按照python的广播机制进
-
Python操作多维数组输出和矩阵运算示例
本文实例讲述了Python操作多维数组输出和矩阵运算.分享给大家供大家参考,具体如下: 在许多编程语言中(Java,COBOL,BASIC),多维数组或者矩阵是(限定各维度的大小)预先定义好的.而在Python中,其实现更简单一些. 如果需要处理更加复杂的情形,可能需要使用Python的数学模块包NumPy,链接地址:http://numpy.sourceforge.net/ 首先来看一个简单的二维表格.投掷两枚骰子时,有36种可能的结果.我们可以将其制成一个二维表格,行和列分别代表一枚骰子的得
-
Python计算矩阵的和积的实例详解
python的numpy库提供矩阵运算的功能,因此我们在需要矩阵运算的时候,需要导入numpy的包. 一.numpy的导入和使用 from numpy import *;#导入numpy的库函数 import numpy as np; #这个方式使用numpy的函数时,需要以np.开头. 二.矩阵的创建 由一维或二维数据创建矩阵 from numpy import *; a1=array([1,2,3]); a1=mat(a1); 创建常见的矩阵 data1=mat(zeros((3,3)));
-
Python NumPy矩阵对象详解及方法
目录 1. 介绍 2. 创建矩阵 3. 矩阵特有属性 4. 矩阵乘法 1. 介绍 在数学上,矩阵(Matrix)是一个按照矩形阵列排列的负数或实数集合,但在NumPy中,矩阵np.matrix是数组np.ndarray的派生类.这意味着矩阵本质上是 一个数组,拥有数组的所有属性和方法:同时,矩阵又有一些不同于数组的特性和方法首先,矩阵是二维的,不能像数组一样幻化成任意维度,即使展开或切片,返回也是二维的:其次,矩阵和矩阵.矩阵和数组都可以做加减乘除运算,运算结果都是返回矩阵:最后,矩阵的乘法
-
python实现矩阵乘法的方法
本文实例讲述了python实现矩阵乘法的方法.分享给大家供大家参考.具体实现方法如下: def matrixMul(A, B): res = [[0] * len(B[0]) for i in range(len(A))] for i in range(len(A)): for j in range(len(B[0])): for k in range(len(B)): res[i][j] += A[i][k] * B[k][j] return res def matrixMul2(A, B):
-
Python表示矩阵的方法分析
本文实例讲述了Python表示矩阵的方法.分享给大家供大家参考,具体如下: 在c语言中,表示个"整型3行4列"的矩阵,可以这样声明:int a[3][4];在python中一不能声明变量int,二不能列出维数.可以利用列表中夹带列表形式表示.例如: 表示矩阵 ,可以这样: count = 1 a = [] for i in range(0, 3): tmp = [] for j in range(0, 3): tmp.append(count) count += 1 a.append
-
js 事件的传播机制(实例讲解)
事件的默认传播机制: 捕获阶段:从外向里依次查找元素 目标阶段:从当前事件源本身的操作 冒泡阶段:从内到外依次触发相关的行为(我们最常用的就是冒泡阶段) 具体见下图: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Document</title> <style> #outer{ margin
-
Python实现矩阵转置的方法分析
本文实例讲述了Python实现矩阵转置的方法.分享给大家供大家参考,具体如下: 前几天群里有同学提出了一个问题:手头现在有个列表,列表里面两个元素,比如[1, 2],之后不断的添加新的列表,往原来相应位置添加.例如添加[3, 4]使原列表扩充为[[1, 3], [2, 4]],再添加[5, 6]扩充为[[1, 3, 5], [2, 4, 6]]等等. 其实不动脑筋的话,用个二重循环很容易写出来: def trans(m): a = [[] for i in m[0]] for i in m: f