Python3 shelve对象持久存储原理详解
1.shelve对象的持久存储
不需要关系数据库时,可以用shelve模块作为持久存储Python对象的一个简单的选择。类似于字典,shelf按键访问。值将被pickled并写至由dbm创建和管理的数据库。
1.1 创建一个新shelf
使用shelve最简单的方法就是利用DbfilenameShelf类。它使用dbm存储数据。这个类可以直接使用,也可以通过调用shelve.open()来使用。
import shelve
with shelve.open('test_shelf.db') as s:
s['key1'] = {
'int': 10,
'float': 9.5,
'string': 'Sample data',
}
再次访问这个数据,可以打开shelf,并像字典一样使用它。
import shelve
with shelve.open('test_shelf.db') as s:
existing = s['key1']
print(existing)
运行这两个示例脚本会生成以下输出。
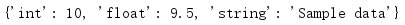
dbm模块不支持多个应用同时写同一个数据库,不过它支持并发的只读客户。如果一个客户没有修改shelf,则可以通过传入flag='r'来告诉shelve以只读方式打开数据库。
import dbm
import shelve
with shelve.open('test_shelf.db', flag='r') as s:
print('Existing:', s['key1'])
try:
s['key1'] = 'new value'
except dbm.error as err:
print('ERROR: {}'.format(err))
如果数据库作为只读数据源打开,并且程序试图修改数据库,那么便会生成一个访问错误异常。具体的异常类型取决于创建数据库时dbm选择的数据库模块。
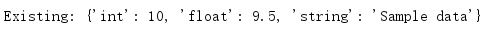
1.2 写回
默认的,shelf不会跟踪对可变对象的修改。这说明,如果存储在shelf中的一个元素的内容有变化,那么shelf必须再次存储整个元素来显式的更新。
import shelve
with shelve.open('test_shelf.db') as s:
print(s['key1'])
s['key1']['new_value'] = 'this was not here before'
with shelve.open('test_shelf.db', writeback=True) as s:
print(s['key1'])
在这个例子中,没有再次存储'key1'的相应字典,所以重新打开shelf时,修改不会保留。

对于shelf中存储的可变对象,要想自动捕获对它们的修改,可以在打开shelf时启用写回(writeback)。writeback标志会让shelf使用内存中缓存以记住从数据库获取的所有对象。shelf关闭时每个缓存对象也被写回到数据库。
import shelve
import pprint
with shelve.open('test_shelf.db', writeback=True) as s:
print('Initial data:')
pprint.pprint(s['key1'])
s['key1']['new_value'] = 'this was not here before'
print('\nModified:')
pprint.pprint(s['key1'])
with shelve.open('test_shelf.db', writeback=True) as s:
print('\nPreserved:')
pprint.pprint(s['key1'])
尽管这会减少程序员犯错的机会,并且使对象持久存储更透明,但是并非所有情况都有必要使用写回模式。打开shelf时缓存会消耗额外的内容,关闭shelf时会暂时将各个缓存对象写回到数据库,这会减慢应用的速度。所有缓存的对象都要写回数据库,因为无法区分它们是否有修改。如果应用读取的数据多于写的数据,那么写回就会影响性能而没有太大意义。

1.3 特定shelf类型
之前的例子都使用了默认的shelf实现。可以使用shelve.open()而不是直接使用某个shelf实现,这是一种常用的用法,特别是使用什么类型的数据库来存储数据并不重要时。不过,有些情况下数据库格式会很重要。在这些情况下,可以直接使用DbfilenameShelf或BsdDbshelf,或者甚至可以派生Shelf来得到一个定制解决方案。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python数据持久化shelve模块用法分析
本文实例讲述了Python数据持久化shelve模块用法.分享给大家供大家参考,具体如下: 一.简介 在python3中我们使用json或者pickle持久化数据,能dump多次,但只能load一次,因为先前的数据已经被后面dump的数据覆盖掉了.如果我们想要实现dump和load多次,可以使用shelve模块.shelve模块可以持久化所有pickle所支持的数据类型. 二.持久化数据 1.数据持久化 import shelve import datetime info = {'name':
-
Python之数据序列化(json、pickle、shelve)详解
什么是序列化 什么是序列化,把程序中的对象或者变量,从内存中转换为可存储或可传输的过程称为序列化.在 Python 中,这个过程称为 pickling,在其他语言中也被称为 serialization,marshalling,flattening 等.程序中的对象(或者变量)在序列化之后,就可以直接存放到存储设备上,或者直接发送到网络上进行传输. 序列化的逆向过程,即为反序列化(unpickling),就是把序列化的对象(或者变量)重新读到内存中~ Python中序列化的模块 模块名称 描述 提
-
python3 shelve模块的详解
python3 shelve模块的详解 一.简介 在python3中我们使用json或者pickle持久化数据,能dump多次,但只能load一次,因为先前的数据已经被后面dump的数据覆盖掉了.如果我们想要实现dump和load多次,可以使用shelve模块.shelve模块可以持久化所有pickle所支持的数据类型. 二.持久化数据 1.数据持久化 import shelve import datetime info = {'name': 'bigberg', 'age': 22} name
-

Python3.5内置模块之shelve模块、xml模块、configparser模块、hashlib、hmac模块用法分析
本文实例讲述了Python3.5内置模块之shelve模块.xml模块.configparser模块.hashlib.hmac模块用法.分享给大家供大家参考,具体如下: 1.shelve模块 shelve类似于一个key-value数据库,可以很方便的用来保存Python的内存对象,其内部使用pickle来序列化数据, 简单来说,使用者可以将一个列表.字典.或者用户自定义的类实例保存到shelve中,下次需要用的时候直接取出来, 就是一个Python内存对象,不需要像传统数据库一样,先取出数据,
-
Python shelve模块实现解析
一.持久化 --shelve 持久化工具 (1)作用:类似字典,用kv对保存数据,存取方式类似于字典 (2)例子:通过一下案例创建了一个数据库,第二个程序我们读取了数据库 #使用shelve创建文件并使用 import shelve shv = shelve.open(r"shv.db") shv["one"] = 1 shv["two"] = 2 shv.close() shv = shelve.open(r"shv.db"
-
python pickle 和 shelve模块的用法
1.pickle 写: 以写方式打开一个文件描述符,调用pickle.dump把对象写进去 复制代码 代码如下: dn = {'baidu':'www.baidu.com','qq':'www.qq.com','360':'www.360.cn'} name = ['mayun','mahuateng','liyanhong'] f = open(r'C:\a.txt','w') pickle.dump(dn,f) ##写一个对象 pickle.dump(name,f) ##再写一个
-
Python使用Shelve保存对象方法总结
Shelve是一个功能强大的Python模块,用于对象持久性.搁置对象时,必须指定一个用于识别对象值的键.通过这种方式,搁置文件成为存储值的数据库,其中任何一个都可以随时访问. Python中搁置的示例代码 要搁置对象,首先导入模块,然后按如下方式分配对象值: import shelve database = shelve.open(filename.suffix) object = Object() database['key'] = object 例如,如果要保留股票数据库,可以调整以下代码
-
Python3 shelve对象持久存储原理详解
1.shelve对象的持久存储 不需要关系数据库时,可以用shelve模块作为持久存储Python对象的一个简单的选择.类似于字典,shelf按键访问.值将被pickled并写至由dbm创建和管理的数据库. 1.1 创建一个新shelf 使用shelve最简单的方法就是利用DbfilenameShelf类.它使用dbm存储数据.这个类可以直接使用,也可以通过调用shelve.open()来使用. import shelve with shelve.open('test_shelf.db') as
-
c#中String类型的存储原理详解
在我们正式了解c#中的String类型前,先来判断一下下面代码的结果吧~ String str1 = "123"; String str2 = str1; str2 = "321"; Console.WriteLine(str1); 上面代码的最终输出结果是123,如果有浅学过引用类型的同学一定会问:str2不是在存储的是str1的引用么?那么str2不是和str1指向堆中同一块内存空间么?为什么在引用了str2使其改变数据后再打印出str1最终还是打印出来123?
-
JavaScript对象原型链原理详解
这篇文章主要介绍了JavaScript对象原型链原理详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一个js对象,除了自己设置的属性外,还会自动生成proto.class.extensible属性,其中,proto属性指向对象的原型. 对象的属性也有writable.enumerable.configurable.value和get/set的配置方法. 对象的创建方式有三种: 一.使用字面量直接创建. 二.基于原型链创建. 分析上图,要点如
-
python变量的存储原理详解
变量的存储 在高级语言中,变量是对内存及其地址的抽象. 对于python而言,python的一切变量都是对象,变量的存储,采用了引用语义的方式,存储的只是一个变量的值所在的内存地址,而不是这个变量的只本身. 引用语义:在python中,变量保存的是对象(值)的引用,我们称为引用语义.采用这种方式,变量所需的存储空间大小一致,因为变量只是保存了一个引用.也被称为对象语义和指针语义. 值语义:有些语言采用的不是这种方式,它们把变量的值直接保存在变量的存储区里,这种方式被我们称为值语义,例如C语言,采
-
JavaScript数组及非数组对象的深浅克隆详解原理
目录 什么是浅克隆.深克隆 1.对数组进行克隆 1.1 浅克隆 1.2 深克隆 2.对非数组对象进行克隆 2.1 浅克隆 2.2 深克隆 3.整合深克隆函数 什么是浅克隆.深克隆 浅克隆:直接将存储在栈中的值赋值给对应变量,如果是基本数据类型,则直接赋值对应的值,如果是引用类型,则赋值的是地址. 深克隆:将数据赋值给对应的变量,从而产生一个与源数据不相干的新数据(数据地址已变化).即对象各个层级的属性. JavaScript中基本数据类型使用符号"="可以进行克隆,引用数据类型使用符号
-
ceph集群RadosGW对象存储使用详解
目录 什么是对象存储 ceph对象存储的构成 RadosGW存储池作用 RadosGW常用操作详解 操纵radosgw 需要先安装好python3环境,以及python的boto模块 python脚本编写 一个完整的ceph集群,可以提供块存储.文件系统和对象存储. 本节主要介绍对象存储RadosGw功能如何灵活的使用 集群背景: $ ceph -s cluster: id: f0a8789e-6d53-44fa-b76d-efa79bbebbcf health: HEALTH_OK servi
-
java存储以及java对象创建的流程(详解)
java存储: 1)寄存器:这是最快的存储区,位于处理器的内部.但是寄存器的数量有限,所以寄存器根据需求进行分配.我们不能直接进行操作. 2)堆栈:位于通用RAM中,可以通过堆栈指针从处理器那里获取直接支持.堆栈指针往下移动,则分配新的内存.网上移动,则释放内存.但是 在创建程序的时候必须知道存储在堆栈中的所有项的具体生命周期,以便上下的移动指针.一般存储基本类型和java对象引用. 3)堆:位于通用RAM中,存放所有的java对象,不需要知道具体的生命周期. 4)常量存储:常量值通常直接存放在
-
Javascript对象及Proxy工作原理详解
正文 这一章其实算是javascript的科普文章,其实这本书的读者一般都不会是入门者,因此按道理说应该不需要再科普才对.但是作者依旧安排了这一章,证明就是这一章内容与我们以为的对象不一样. Javascript中一切皆对象 这一句话大家应该耳熟能详,对于常规的字面量对象,和new出来的对象,大家应该都能分辨 const str = '' const str2 = new String() const obj = {} const obj2 = Object.create() 但是根据ECMA,
-
Java对象Serializable接口实现详解
这篇文章主要介绍了Java对象Serializable接口实现详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 导读 最近这段时间一直在忙着编写Java业务代码,麻木地搬着Ctrl-C.Ctrl-V的砖,在不知道重复了多少次定义Java实体对象时"implements Serializable"的C/V大法后,脑海中突然冒出一个思维(A):问了自己一句"Java实体对象为什么一定要实现Serializable接口呢?&qu
-
Java NIO Buffer实现原理详解
目录 1.Buffer的继承体系 2.Buffer的操作API使用案例 3.Buffer的基本原理 4.allocate方法初始化一个指定容量大小的缓冲区 5.slice方法缓冲区分片 6.只读缓冲区 7.直接缓冲区 8.内存映射 1.Buffer的继承体系 如上图所示,对于Java中的所有基本类型,都会有一个具体的Buffer类型与之对应,一般我们最经常使用的是ByteBuffer. 2.Buffer的操作API使用案例 举一个IntBuffer的使用案例: /** * @author csp