Python操作Elasticsearch处理timeout超时
Elasticsearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。Elasticsearch 在 Apache Lucene 的基础上开发而成,由 Elasticsearch N.V.(即现在的 Elastic)于 2010 年首次发布
Elasticsearch 以其简单的 REST 风格 API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件;Elastic Stack 是适用于数据采集、充实、存储、分析和可视化的一组开源工具。人们通常将 Elastic Stack 称为 ELK Stack(代指 Elasticsearch、Logstash 和 Kibana),目前 Elastic Stack 包括一系列丰富的轻量型数据采集代理,这些代理统称为 Beats,可用来向 Elasticsearch 发送数据。
第一种方法,添加超时参数
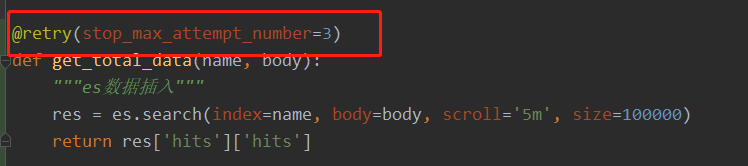
第二种方法:
在es语句中添加超时参数
res = es.search(index=name, body=body, scroll='5m', size=100000, timeout=60)
第三种方法:
在连接处配置:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python 操作 ElasticSearch的完整代码
官方文档:https://elasticsearch-py.readthedocs.io/en/master/ 1.介绍 python提供了操作ElasticSearch 接口,因此要用python来操作ElasticSearch,首先要安装python的ElasticSearch包,用命令pip install elasticsearch安装或下载安装:https://pypi.python.org/pypi/elasticsearch/5.4.0 2.创建索引 假如创建索引名称为ott,类型
-

使用Python操作Elasticsearch数据索引的教程
Elasticsearch是一个分布式.Restful的搜索及分析服务器,Apache Solr一样,它也是基于Lucence的索引服务器,但我认为Elasticsearch对比Solr的优点在于: 轻量级:安装启动方便,下载文件之后一条命令就可以启动: Schema free:可以向服务器提交任意结构的JSON对象,Solr中使用schema.xml指定了索引结构: 多索引文件支持:使用不同的index参数就能创建另一个索引文件,Solr中需要另行配置: 分布式:Solr Cloud的配置比较
-
python elasticsearch从创建索引到写入数据的全过程
python elasticsearch从创建索引到写入数据 创建索引 from elasticsearch import Elasticsearch es = Elasticsearch('192.168.1.1:9200') mappings = { "mappings": { "type_doc_test": { #type_doc_test为doc_type "properties": { "id": { "
-
Python对ElasticSearch获取数据及操作
使用Python对ElasticSearch获取数据及操作,供大家参考,具体内容如下 Version Python :2.7 ElasticSearch:6.3 代码: #!/usr/bin/env python # -*- coding: utf-8 -*- """ @Time : 2018/7/4 @Author : LiuXueWen @Site : @File : ElasticSearchOperation.py @Software: PyCharm @Descri
-
python3实现elasticsearch批量更新数据
废话不多说,直接上代码! updateBody = { "query":{ "range":{ "write_date": { "gte": "2019-01-15 12:30:17", "lte": "now" } } }, "script": { "inline": "ctx._source.index = par
-
python中的Elasticsearch操作汇总
这篇文章主要介绍了python中的Elasticsearch操作汇总,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 导入包 from elasticsearch import Elasticsearch 本地连接 es = Elasticsearch(['127.0.0.1:9200']) 创建索引 es.indices.create(index="python_es01",ignore=400) ingore=400 ingore是
-
elasticsearch python 查询的两种方法
elasticsearch python 查询的两种方法,具体内容如下所述: from elasticsearch import Elasticsearch es = Elasticsearch res1 = es.search(index="2018-07-31", body={"query": {"match_all": {}}}) print(es1) {'_shards': {'failed': 0, 'skipped': 0, 'suc
-
python elasticsearch环境搭建详解
windows下载zip linux下载tar 下载地址:https://www.elastic.co/downloads/elasticsearch 解压后运行:bin/elasticsearch (or bin\elasticsearch.bat on Windows) 检查是否成功:访问 http://localhost:9200 linux下不能以root用户运行, 普通用户运行报错: java.nio.file.AccessDeniedException 原因:当前用户没有执行权限 解
-
Python操作Elasticsearch处理timeout超时
Elasticsearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本.数字.地理空间.结构化和非结构化数据.Elasticsearch 在 Apache Lucene 的基础上开发而成,由 Elasticsearch N.V.(即现在的 Elastic)于 2010 年首次发布 Elasticsearch 以其简单的 REST 风格 API.分布式特性.速度和可扩展性而闻名,是 Elastic Stack 的核心组件:Elastic Stack 是适用于数据采集.充实.存
-
Python中elasticsearch插入和更新数据的实现方法
首先,我的索引结构是酱紫的. 存储以name_id为主键的索引,待插入或更新数据为: 一般会有有两种操作: 以下图片为个人见解,我没试过能不能直接运行,但形式上没错. 数据不存在,我需要插入地址为空字符串. 单条插入: 批量插入: 该数据存在,我需要更新地址字段为空字符串. 单条更新: 批量更新: 总结 以上所述是小编给大家介绍的Python中elasticsearch插入和更新数据的实现方法,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的! 您可能感兴趣的文章: 使用
-
Python操作ES的方式及与Mysql数据同步过程示例
目录 Python操作Elasticsearch的两种方式 mysql和Elasticsearch同步数据 haystack的使用 Redis补充 Python操作Elasticsearch的两种方式 # 官方提供的:Elasticsearch # pip install elasticsearch # GUI:pyhon能做图形化界面编程吗? -Tkinter -pyqt # 使用(查询是重点) # pip3 install elasticsearch https://github.com/e
-
在vue中axios设置timeout超时的操作
在做vue项目的时候,由于数据量查询比较大,所以前台调用接口数据的时候,往往要等很久,所以需要设置个超时,当超过设置时间就让向页面返回一个状态,让使用者不用一直等. 通过官网api查询,对其超时讲解不是很多,但其和Jquery中请求非常类似 Jquery请求方式 $.ajax({ url: '接口地址', type:'get', //请求方式get或post data:{}, //请求所传的参数 dataType: 'json', //返回的数据格式 timeout: 4000, //设置时间超
-
Python操作redis实例小结【String、Hash、List、Set等】
本文实例总结了Python操作redis方法.分享给大家供大家参考,具体如下: 这里介绍详细使用 1.String 操作 redis中的String在在内存中按照一个name对应一个value来存储 set() #在Redis中设置值,默认不存在则创建,存在则修改 r.set('name', 'zhangsan') '''参数: set(name, value, ex=None, px=None, nx=False, xx=False) ex,过期时间(秒) px,过期时间(毫秒) nx,如果设
-
python爬虫之urllib,伪装,超时设置,异常处理的方法
Urllib 1. Urllib.request.urlopen().read().decode() 返回一个二进制的对象,对这个对象进行read()操作,可以得到一个包含网页的二进制字符串,然后用decode()解码成html源码 2. urlretrieve() 将一个网页爬取到本地 3. urlclearup() 清除 urlretrieve()所产生的缓存 4. info() 返回一个httpMessage对象,表示远程服务器的头信息 5. getcode() 获取当前网页的状态码 20
-
使用Python操作MySql数据库和MsSql数据库
目录 一.MySQL数据库模块的安装和连接 1. PyMySQL模块的安装 2 .python连接数据库 二.创建表操作 三.操作数据 1.插入操作 2. 查询操作 3. 更新操作 4. 删除操作 四.MS SQLSever数据库模块的安装和连接 1.正确安装方法: 2.Python操作sqlserver介绍 1.数据库连接类及参数介绍 2.数据库连接对象的方法 3.Cusor 对象方法 3.实例: 一.MySQL数据库模块的安装和连接 1. PyMySQL模块的安装 pip install p