详解Java中字典树(Trie树)的图解与实现
目录
- 简介
- 工作过程
- 数据结构
- 初始化
- 构建字典树
- 应用
- 匹配有效单词
- 关键词提示
- 总结
简介
Trie又称为前缀树或字典树,是一种有序树,它是一种专门用来处理串匹配的数据结构,用来解决一组字符中快速查找某个字符串的问题。Google搜索的关键字提示功能相信大家都不陌生,我们在输入框中进行搜索的时候,会下拉出一系列候选关键词。

上面这个关键词提示功能,底层最基本的原理就是我们今天说的数据结构:Trie树
我们先看看Tire树长什么样子,以单纯的单词匹配为例,首先它是一棵多叉树结构,根节点是一个空字符,树中节点分为普通节点和结尾节点(如图中红色节点)。结尾节点表示加上前面前缀,可以称为一个单词,如图中hi,him。

工作过程
Tire树与之前串匹配最大的不同点是,之前我们都是单模式串,查看主串中是否有与模式串匹配的子串,操作过程也是用模式串去与主串进行比较。而Tire树是多模式串,我们先将模式串提前构建成Tire树,然后查看主串是否匹配模式串,且更适用于类似如上关键词提示的前缀匹配。接下来我们自己通过实现一个简易的关键词提示功能来讲解Tire树。
数据结构
一个value存储当前节点值,用一个26大小的数组存储当前节点的孩子节点,这是一个简单但是可能产生浪费的方法,可以采用有序存入采用二分法查找,或者采用hash表,跳表进行优化。一个标志当前节点是否可作为尾节点。
/**
* Trie树节点
* 假设我们只做26个小写字母下的匹配
*/
public static class Node{
//当前节点值
private char value;
//当前节点的孩子节点
private Node[] childNode;
//标志当前节点是否是某单词结尾
private boolean isTail;
public Node(char value) {
this.value = value;
}
}
初始化
初始化一个仅有root节点的Tire树,root节点值为'/0'。
Node root;
public void init() {
root = new Node('\0');
root.childNode = new Node[26];
}
构建字典树
将需要加入的模式串加入Tire树,遍历当前字符串字符,从Tire树根节点开始查找当前字符,如果字符已经存在不需要处理,并且从这个字符节点出发,查看下一个字符是否存在,如果当前节点不存Tire树,才需要插入当前字符,当插入最后一个字符时需要标志当前字符节点为尾节点。
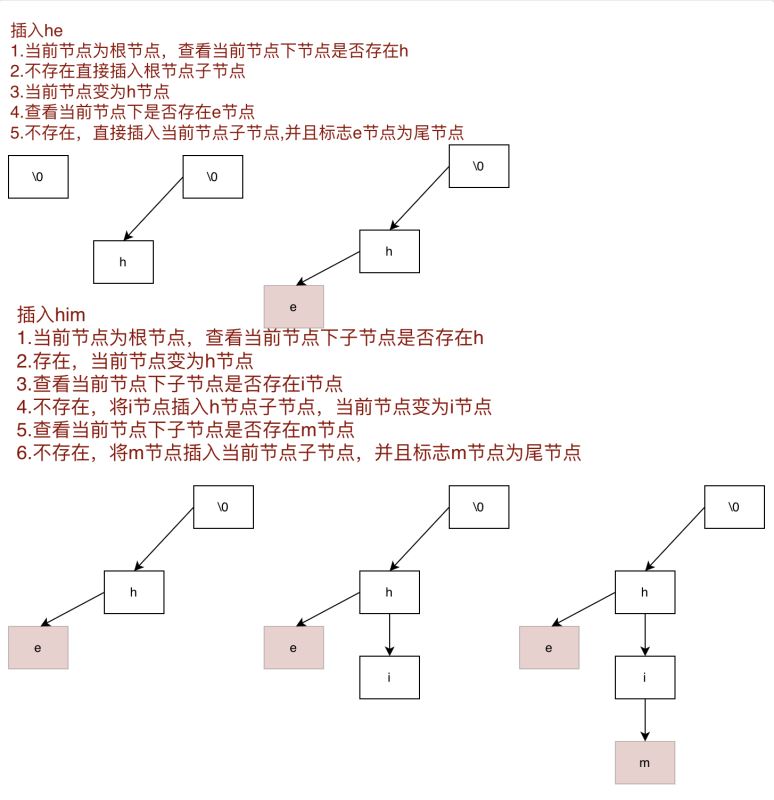
/**
* 将当前串插入字典树
* @param chars
*/
public void insertStr(char[] chars) {
//首先判断首字符是否已经在字典树中,然后判断第二字符,依次往下进行判断,找到第一个不存在的字符进行插入孩节点
Node p = root;
//表明当前处理到了第几个字符
int chIndex = 0;
while (chIndex < chars.length) {
while (chIndex < chars.length && null != p) {
Node[] children = p.childNode;
boolean find = false;
for (Node child : children) {
if (null == child) {continue;}
if (child.value == chars[chIndex]) {
//当前字符已经存在,不需要再进行存储
//从当前节点出发,存储下一个字符
p = child;
++ chIndex;
find = true;
break;
}
}
if (Boolean.TRUE.equals(find)) {
//在孩子中找到了 不用再次存储
break;
}
//如果把孩子节点都找遍了,还没有找到这个字符,直接将这个字符加入当前节点的孩子节点
Node node = new Node(chars[chIndex]);
node.childNode = new Node[26];
children[chars[chIndex] - 'a'] = node;
p = node;
++ chIndex;
}
}
//字符串中字符全部进入tire树中后,将最后一个字符所在节点标志为结尾节点
p.isTail = true;
}
应用
匹配有效单词
遍历字符串,从根节点出发,查看字符是否存在,只要存在不存在的情况,直接返回false,如果每个字符都存在,判断最后一个字符是否为结尾节点,如果不是,到这里还不是一个有效单词,返回false,否则,返回true。
/**
* 查看当前字符串是否可以在trie中找到
* @param str 主串
* @return true/false
*/
public boolean isMatch(String str) {
//从root开始进行匹配,只要有一个找不到即为匹配失败
char[] chars = str.toCharArray();
int chIndex = 0;
Node p = root;
while (null != p) {
Node[] children = p.childNode;
boolean flag = false;
for (Node child : children) {
if (null == child) {continue;}
if (child.value == chars[chIndex]) {
flag = true;
p = child;
++ chIndex;
//当比较最后一个字符的时候,这个字符需要是结尾字符才能完全匹配
if (chIndex == chars.length && p.isTail) {
return true;
}
break;
}
}
if (Boolean.FALSE.equals(flag)) {
return false;
}
}
return false;
}
测试样例
public static void main(String[] args) {
//he, him, lot, a
//初始化Tire树
Trie trie = new Trie();
trie.init();
//构建Tire树,只有以下单词才是有效单词
trie.insertStr("he".toCharArray());
trie.insertStr("him".toCharArray());
trie.insertStr("lot".toCharArray());
trie.insertStr("a".toCharArray());
//匹配字符串是否为有效单词
System.out.println(trie.isMatch("lot"));
System.out.println(trie.isMatch("lit"));
}
运行结果

关键词提示
根据输入的关键词前缀,匹配所有可能出现的关键词。首先遍历字符串,从节点出发,只要有一个找不到,直接返回null,直至找到最后一个字符对应的节点,从该节点出发找到所有尾节点。
/**
* 找到所有以str为前缀的字符串
* @param str 前缀串
* @return 所有以str为前缀的单词
*/
public List<String> findStrPrefix(String str) {
//根据str首先找到str最后一个字符,然后从这个字符出发,找到所有字符串
List<String> result = new ArrayList<>();
char[] chars = str.toCharArray();
//分成两步走
//1。找到str最后一个自字符在字典树中的node
//2。从该node出发,找到所有的结尾node,即为以str为前缀的字符串
int chIndex = 0;
Node p = root;
while (null != p && chIndex < chars.length) {
Node[] children = p.childNode;
boolean flag = false;
for (Node child : children) {
if (null == child) {continue;}
if (child.value == chars[chIndex]) {
//已经找到
p = child;
flag = true;
++ chIndex;
break;
}
}
//如果没有找到,直接返回空
if (Boolean.FALSE.equals(flag)) {
return null;
}
}
//找到了最后一个节点
//深度优先遍历,查找所有尾节点
this.dfs(p, new StringBuilder(str), result);
return result;
}
public void dfs(Node p, StringBuilder str, List<String> result) {
Node[] children = p.childNode;
for (Node child : children) {
if (null == child) {
continue;
}
str.append(child.value);
if (child.isTail) {
result.add(str.toString());
}
//再递归查当前节点的孩子节点
dfs(child, str, result);
//需要将刚刚set进去的节点删除,否则影响当前节点的下一个孩子节点
//举个例子,h的孩子节点有e,i,当e放进去之后不拿出来,在遍历到i的时候,就会形成hei
str.setLength(str.length() - 1);
}
}
测试样例
public static void main(String[] args) {
//he, him, lot, a
//初始化Tire树
Trie trie = new Trie();
trie.init();
//构建Tire树,只有以下单词才是有效单词
trie.insertStr("he".toCharArray());
trie.insertStr("him".toCharArray());
trie.insertStr("lot".toCharArray());
trie.insertStr("a".toCharArray());
//匹配字符串是否为有效单词
List<String> strings = trie.findStrPrefix("h");
}
运行结果

总结
到这里Trie树就讲完了,主要就是聚合前缀,通过树的特性,按照链路进行访问,同时标志尾节点,标志到当前节点是一个完整的字符串。
以上就是详解Java中字典树(Trie树)的图解与实现的详细内容,更多关于Java字典树的资料请关注我们其它相关文章!
相关推荐
-

Java中关于字典树的算法实现
字典树(前缀树)算法实现 前言 字典树,又称单词查找树,是一个典型的 一对多的字符串匹配算法."一"指的是一个模式串,"多"指的是多个模板串.字典树经常被用来统计.排序和保存大量的字符串.它利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较. 字典树有3个基本性质: 根节点不包含字符,其余的每个节点都包含一个字符: 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串: 每个节点的所有子节点包含的字符都不相同. pass参数:代表从这个
-
Trie树(字典树)的介绍及Java实现
简介 Trie树,又称为前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串.与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定.一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串. 它的主要特点如下: 根节点不包含字符,除根节点外的每一个节点都只包含一个字符. 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串. 每个节点的所有子节点包含的字符都不相同. 如下是一棵典型的Trie树: Trie的来源是Retrie
-
详解Java中字典树(Trie树)的图解与实现
目录 简介 工作过程 数据结构 初始化 构建字典树 应用 匹配有效单词 关键词提示 总结 简介 Trie又称为前缀树或字典树,是一种有序树,它是一种专门用来处理串匹配的数据结构,用来解决一组字符中快速查找某个字符串的问题.Google搜索的关键字提示功能相信大家都不陌生,我们在输入框中进行搜索的时候,会下拉出一系列候选关键词. 上面这个关键词提示功能,底层最基本的原理就是我们今天说的数据结构:Trie树 我们先看看Tire树长什么样子,以单纯的单词匹配为例,首先它是一棵多叉树结构,根节点是一个空
-
详解Java中AC自动机的原理与实现
目录 简介 工作过程 数据结构 初始化 构建字典树 构建失败指针 匹配 执行结果 简介 AC自动机是一个多模式匹配算法,在模式匹配领域被广泛应用,举一个经典的例子,违禁词查找并替换为***.AC自动机其实是Trie树和KMP 算法的结合,首先将多模式串建立一个Tire树,然后结合KMP算法前缀与后缀匹配可以减少不必要比较的思想达到高效找到字符串中出现的匹配串. 如果不知道什么是Tire树,可以先查看:详解Java中字典树(Trie树)的图解与实现 如果不知道KMP算法,可以先查看:详解Java中
-
详解Java中HashSet和TreeSet的区别
详解Java中HashSet和TreeSet的区别 1. HashSet HashSet有以下特点: 不能保证元素的排列顺序,顺序有可能发生变化 不是同步的 集合元素可以是null,但只能放入一个null 当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置. 简单的说,HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个
-
详解Java中list,set,map的遍历与增强for循环
详解Java中list,set,map的遍历与增强for循环 Java集合类可分为三大块,分别是从Collection接口延伸出的List.Set和以键值对形式作存储的Map类型集合. 关于增强for循环,需要注意的是,使用增强for循环无法访问数组下标值,对于集合的遍历其内部采用的也是Iterator的相关方法.如果只做简单遍历读取,增强for循环确实减轻不少的代码量. 集合概念: 1.作用:用于存放对象 2.相当于一个容器,里面包含着一组对象,其中的每个对象作为集合的一个元素出现 3.jav
-
详解Java中String,StringBuffer和StringBuilder的使用
目录 1.String类 2.String对象创建的两种方式 3.String常用方法 4.StringBuffer String和StringBuffer的转换 StringBuffer的常用方法 5.StringBuilder 1.String类 字符串广泛应用 在 Java 编程中,在 Java 中字符串属于对象,Java 提供了 String 类来创建和操作字符串. String对象实现了Serializable接口,说明String对象可以串行化(在网络中进行传输),同时实现了Comp
-
详解Java中@Override的作用
详解Java中@Override的作用 @Override是伪代码,表示重写(当然不写也可以),不过写上有如下好处: 1.可以当注释用,方便阅读: 2.编译器可以给你验证@Override下面的方法名是否是你父类中所有的,如果没有则报错.例如,你如果没写@Override,而你下面的方法名又写错了,这时你的编译器是可以编译通过的,因为编译器以为这个方法是你的子类中自己增加的方法. 举例:在重写父类的onCreate时,在方法前面加上@Override 系统可以帮你检查方法的正确性. @Overr
-
详解Java中多线程异常捕获Runnable的实现
详解Java中多线程异常捕获Runnable的实现 1.背景: Java 多线程异常不向主线程抛,自己处理,外部捕获不了异常.所以要实现主线程对子线程异常的捕获. 2.工具: 实现Runnable接口的LayerInitTask类,ThreadException类,线程安全的Vector 3.思路: 向LayerInitTask中传入Vector,记录异常情况,外部遍历,判断,抛出异常. 4.代码: package step5.exception; import java.util.Vector
-
详解java 中Spring jsonp 跨域请求的实例
详解java 中Spring jsonp 跨域请求的实例 jsonp介绍 JSONP(JSON with Padding)是JSON的一种"使用模式",可用于解决主流浏览器的跨域数据访问的问题.由于同源策略,一般来说位于 server1.example.com 的网页无法与不是 server1.example.com的服务器沟通,而 HTML 的<script> 元素是一个例外.利用 <script> 元素的这个开放策略,网页可以得到从其他来源动态产生的 JSO
-
详解Java 中的嵌套类与内部类
详解Java 中的嵌套类与内部类 在Java中,可以在一个类内部定义另一个类,这种类称为嵌套类(nested class).嵌套类有两种类型:静态嵌套类和非静态嵌套类.静态嵌套类较少使用,非静态嵌套类使用较多,也就是常说的内部类.其中内部类又分为三种类型: 1.在外部类中直接定义的内部类. 2.在函数中定义的内部类. 3.匿名内部类. 对于这几种类型的访问规则, 示例程序如下: package lxg; //定义外部类 public class OuterClass { //外部类静态成员变量
-
详解Java中Collections.sort排序
Comparator是个接口,可重写compare()及equals()这两个方法,用于比价功能:如果是null的话,就是使用元素的默认顺序,如a,b,c,d,e,f,g,就是a,b,c,d,e,f,g这样,当然数字也是这样的. compare(a,b)方法:根据第一个参数小于.等于或大于第二个参数分别返回负整数.零或正整数. equals(obj)方法:仅当指定的对象也是一个 Comparator,并且强行实施与此 Comparator 相同的排序时才返回 true. Collections.