Spring Bean的包扫描的实现方法
我们知道,Spring可以通过包扫描将使用@Component注解定义的Bean定义到容器中。今天就来探究下他实现的原理。
首先,找到@Component注解的处理类
注解的定义,一般都需要配套的对注解的处理才能完成注解所代表的功能。所以我们通过@Component注解的用到的地方,来查找可能的处理逻辑;
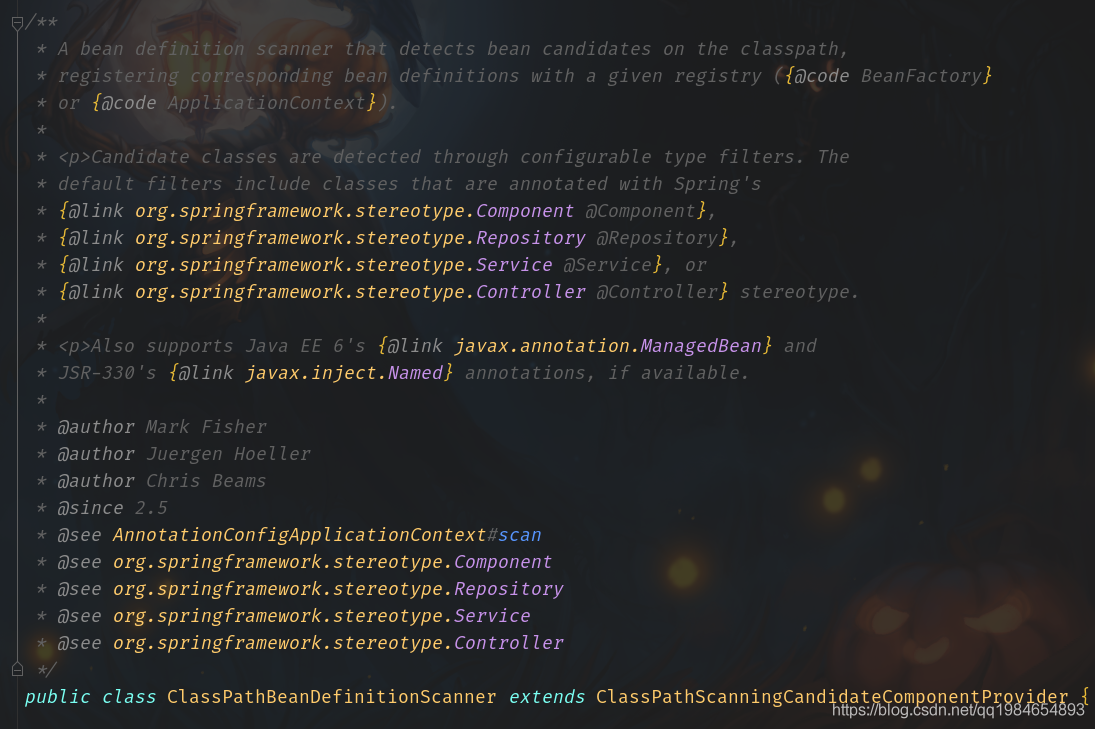
我们先进入Spring的项目,在IDEA里面用Ctrl和鼠标左键点击Component注解的名称,IDEA会显示出使用到这个类的位置,我们从弹出的列表中找到一个名称像的类,去看类上面的注释说明,如图:

我们点进类中,可以看到第一行就说了这个类是为了从classpath里面找到定义的Bean:
分析具体方法
一般Spring的类都是经过设计的,职责清晰。所以一般都是有简单直接的接口暴露,我们打开类的公开API可以看到有个很直接的方法就叫做扫描,看看注释说“从指定的包中扫描Bean”,那就是它了。
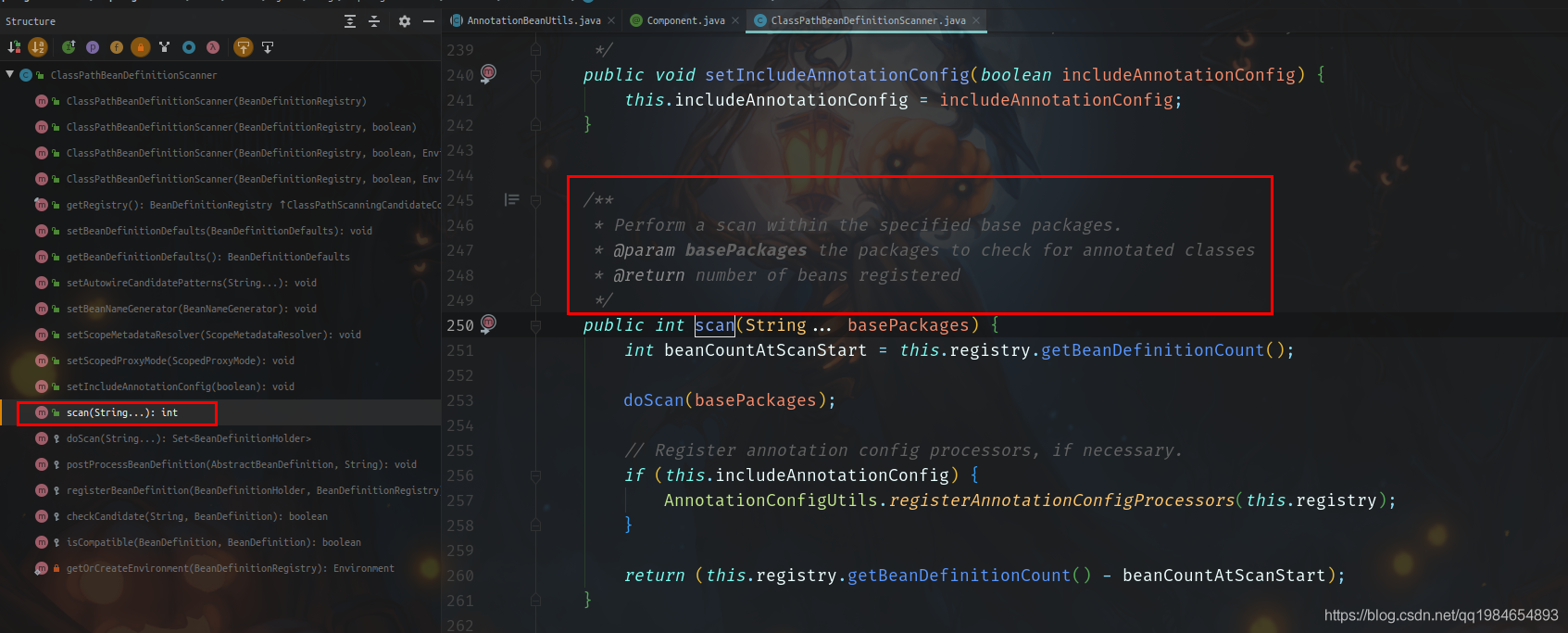
然后,我们为了确认,实现确实是通过这个方法,可以启动程序,打个断点看看是否经过这里(但是这这里,没有调用scan()方法,而是更深一层的doScan方法,也确实费解)。
我们进入doScan() 方法看看实现:
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
// 可以指定多个basePackage,这里就对每个都处理
for (String basePackage : basePackages) {
// 这个方法是真正的查找候选Bean的地方
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// 对于每个查找出的候选Bean,进行处理
for (BeanDefinition candidate : candidates) {
// 解析@Scope的元数据
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// 为候选的Bean生成一个名称
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// 应用后置处理器
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
//
// 处理一些其它通用的注解的元数据
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 校验通过后,注册到 BeanFactory
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
从方法中我们可以明显的看到,核心代码还在findCandidateComponents方法里面,我们进入这个方法后再通过调试一直找到核心代码scanCandidateComponents。如下图,第一处是找到指定包路径所代表的classpath中的资源对象, 但是这里只是找到了包下面有什么,但是还不知道包下面的类是不是一个候选的Bean(可以看到将DTO类也扫描到了)。如下:
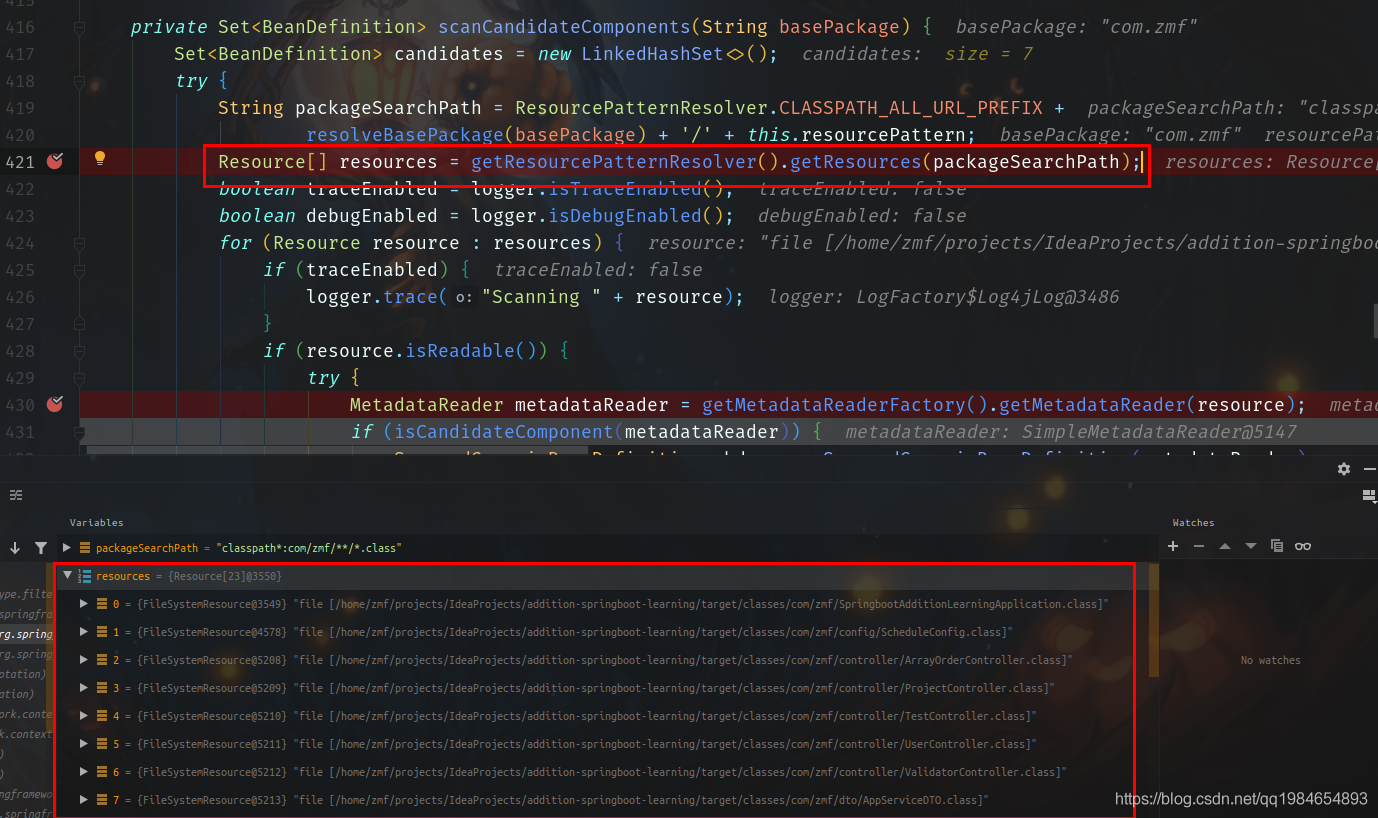
正常思路,拿到了有哪些资源就该进一步去筛选,看看这些资源有哪些是真正的Bean的定义类。
现在我们还不清楚的是,Spring通过什么方式知道一个类是否是真正的Bean的。我们继续调试,到上图的430行debug进去看看,可以走到org.springframework.core.type.classreading.SimpleMetadataReader这个类的构造器中,如下:
SimpleMetadataReader(Resource resource, @Nullable ClassLoader classLoader) throws IOException {
// 通过流读取资源的内容,现在这个资源可以认为是我们的类
InputStream is = new BufferedInputStream(resource.getInputStream());
ClassReader classReader;
try {
// 这个Reader的构造器中就将流读取完毕了
classReader = new ClassReader(is);
}
catch (IllegalArgumentException ex) {
// 通过这个异常的信息,可以推测出,其实这里是通过ASM读取Class文件的定义了
throw new NestedIOException("ASM ClassReader failed to parse class file - " +
"probably due to a new Java class file version that isn't supported yet: " + resource, ex);
}
finally {
is.close();
}
// 这里根据命名可以推测是访问者模式来暴露注解的元数据
AnnotationMetadataReadingVisitor visitor = new AnnotationMetadataReadingVisitor(classLoader);
// 这个accpect方法也是访问者模式中的典型方法,在这里面,是数据的解析逻辑
classReader.accept(visitor, ClassReader.SKIP_DEBUG);
this.annotationMetadata = visitor;
// (since AnnotationMetadataReadingVisitor extends ClassMetadataReadingVisitor)
this.classMetadata = visitor;
this.resource = resource;
}
我们在进入classReader.accept方法,这里面可以看到reader对于Class文件的的按字节解析。
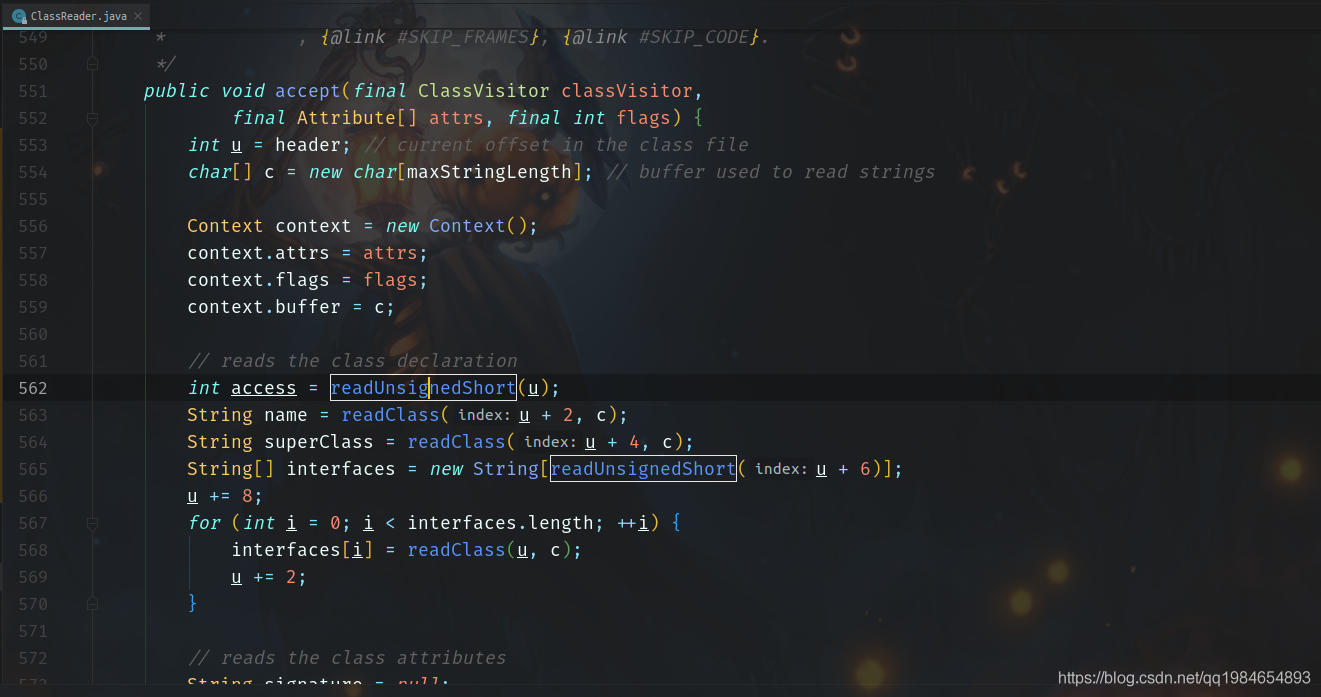
例如,下面读取的类声明,类注解都是包扫描需要的类元数据:

拿到这些元数据之后,就按照包扫描的过滤器就过滤出真正需要的类,作为候选的Bean
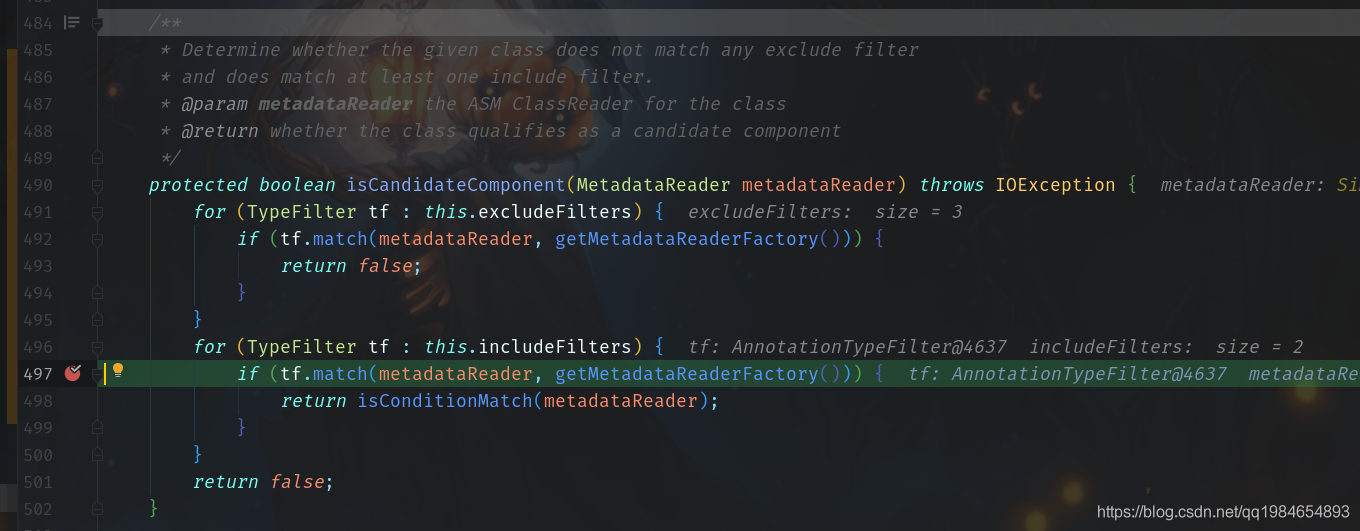
获取到元数据之后,就可以按部就班对Bean进行注册、初始化等一系列逻辑啦~
总结
- 包扫描是通过读取包对应的类路径下的
class文件后,对class文件进行解析元数据的方式,确定了Bean的定义的; - 本地
IDEA的启动方式可能和Jar包方式寻找资源的方式略有不同,但是思路是一致的,都是按照第一点查找;
到此这篇关于Spring Bean的包扫描的实现方法的文章就介绍到这了,更多相关Spring Bean扫描包内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
浅谈Spring装配Bean之组件扫描和自动装配
Spring从两个角度来实现自动化装配: 组件扫描:Spring会自动发现应用上下文中所创建的bean. 自动装配:Spring自动满足bean之间的依赖. 案例:音响系统的组件.首先为CD创建CompactDisc接口及实现类,Spring会发现它并将其创建为一个bean.然后,会创建一个CDPlayer类,让Spring发现它,并将CompactDisc bean注入进来. 创建CompactDisc接口: package soundsystem; public interface Comp
-

Spring自动扫描无法扫描jar包中bean的解决方法
发现问题 前几天用eclipse打包了一个jar包,jar包里面是定义的Spring的bean. 然后将jar包放到lib下,设置spring的自动扫描这个jar包中的bean,可谁知根本无法扫描到bean,显示错误就是找不到bean,当时就纳闷儿了,为什么扫描不到,结果搜索之后才发现,用eclipse打包jar包要勾选"Add directory entries"才能被Spring正确扫描到,居然有这个说法,呵呵- 不知道 勾选"Add directory entries&
-
解决Spring Boot 多模块注入访问不到jar包中的Bean问题
情景描述 一个聚合项目spring-security-tutorial,其中包括4个module,pom如下所示: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://mav
-
Spring Bean的包扫描的实现方法
我们知道,Spring可以通过包扫描将使用@Component注解定义的Bean定义到容器中.今天就来探究下他实现的原理. 首先,找到@Component注解的处理类 注解的定义,一般都需要配套的对注解的处理才能完成注解所代表的功能.所以我们通过@Component注解的用到的地方,来查找可能的处理逻辑; 我们先进入Spring的项目,在IDEA里面用Ctrl和鼠标左键点击Component注解的名称,IDEA会显示出使用到这个类的位置,我们从弹出的列表中找到一个名称像的类,去看类上面的注释说明
-
关于SpingMVC的<context:component-scan>包扫描踩坑记录
目录 <context:component-scan>包扫描的坑 改动前 改动后 <context:component-scan>的使用说明 <context:annotation-config/>提供了两个子标签 <context:component-scan>包扫描的坑 公司项目配置的Spring项目的包扫描有点问题,出现了一个被Spring容器管理的Bean被创建了2次的现象.在此记录下解决的过程,方便后续查阅. 改动前 容器启动监听器中会扫描全部包,
-
Spring Bean注册与注入实现方法详解
目录 1. 逻辑上的 Bean 注册 2. XML 注册 Bean 到自建的库中 2.1 工厂方法 2.2 使用工厂方法和实例化工厂注册 Bean 3. XML 配合注解进行 Bean 注册 4. 使用注解注册 Bean 4.1 注解方式注册的必要条件 4.2 用到的注解 4.3 @Component注解注入 4.4 使用 @Bean 注解注册 5. 通过注解注入 Bean 6. 注入时的一个坑点 7. 获取 库中的对象 上接[Spring]spring核心思想——IOC和DI 上篇文章结尾简单
-
springboot多模块包扫描问题的解决方法
问题描述: springboot建立多个模块,当一个模块需要使用另一个模块的服务时,需要注入另一个模块的组件,如下面图中例子: memberservice模块中的MemberServiceApiImpl类需要注入common模块中的RedisService组件,该怎么注入呢? 解决: 在memberservice模块的启动类上加上RedisService类所在包的全路径的组件扫描,就像这样: 注意启动类上方的注解@ComponentScan(basePackages={"com.whu.comm
-
普通类注入不进spring bean的解决方法
解决问题:我在做移动端accessToken的使用遇到一个问题,就是普通类死活注入不进去spring bean,我和同事雷杰通过各种注解,xml配置搞了好久都搞不定,这里插个眼,有空补一下spring,得深入研究一下 解决办法:后面通过一个spring工具类搞定,这里贴上代码 1.引入这个springUtil类 2.通过构造方法注入 贴上SpringUtils代码: package com.dt.base.weixin.util; import org.springframework.aop.f
-
Spring中bean的生命周期之getSingleton方法
Spring中bean的生命周期 要想讲清楚spring中bean的生命周期,真的是不容易,以AnnotationConfigApplicationContext上下文为基础来讲解bean的生命周期,AnnotationConfigApplicationContext是基于注解的上下文,使用XML的方式现在很少见,所以以此上下文为基础,使用XML的上下文ClassPathXmlApplicationContext的步骤和AnnotationConfigApplicationContext类似.
-
java Quartz定时器任务与Spring task定时的几种实现方法
一.分类 从实现的技术上来分类,目前主要有三种技术(或者说有三种产品): 1.Java自带的java.util.Timer类,这个类允许你调度一个java.util.TimerTask任务.使用这种方式可以让你的程序按照某一个频度执行,但不能在指定时间运行.一般用的较少,这篇文章将不做详细介绍. 2.使用Quartz,这是一个功能比较强大的的调度器,可以让你的程序在指定时间执行,也可以按照某一个频度执行,配置起来稍显复杂,稍后会详细介绍. 3.Spring3.0以后自带的task,可以将它看成一
-
Spring Boot使用Druid和监控配置方法
Spring Boot默认的数据源是:org.apache.tomcat.jdbc.pool.DataSource Druid是Java语言中最好的数据库连接池,并且能够提供强大的监控和扩展功能. 下面来说明如何在 Spring Boot 中配置使用Druid (1)添加Maven依赖 (或jar包)\ <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId&g
-
Spring自动装配与扫描注解代码详解
1 javabean的自动装配 自动注入,减少xml文件的配置信息. <?xml version="1.0" encoding="UTF-8"?> <!-- 到入xml文件的约束 --> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:p="http://www.springframework.org/schema/p&quo