Mysql InnoDB B+树索引目录项记录页管理
目录
- Mysql InnoDB B+树索引目录项记录管理
- 一、目录项记录页
- 二、当目录项记录页也变多后
- 三、B+ 树
Mysql InnoDB B+树索引目录项记录管理
接上一篇内容,InnoDB 的作者想到一种更灵活的方式来管理所有目录项,是什么?
一、目录项记录页
其实这些用户目录项与用户记录很像,只是目录项中的两个列记录的是主键和页号而已,那么就可以复用之前存储用户记录的数据页来存储目录项。
为了区分用户记录和目录项,仍然使用 record_type 这个属性,当值为 1 时,表示目录项记录,再来复习一遍:
- 0:普通用户记录
- 1:目录项记录
- 2:Infimum 记录
- 3:Supremum 记录
现在把目录项放到一个新页中,就变成了这样:

- 目录项记录 record_type 值为 1,普通用户记录的 record_type 值是 0
- 目录项记录只有主键值和页的编号,两个列
如此一来,目录页跟数据页一样,都可以为主键值生成 Page Directory(页目录),从而在根据主键值查找记录时,使用二分法来加快查询速度。
还是以查找主键值为 20 的记录为例,大致就可以分为 2 步走:
- 先目录项页(页30)通过二分法快速找到对应的目录项记录。因为 12<20<209,所以目标记录在页 9。
- 到页 9中继续根据二分法快速找到主键为 20 的用户记录。
二、当目录项记录页也变多后
一个页大小是16KB,当数据多的时候,一个页用来存放页目录记录一定不够用。解决办法也很简单,就是整更多的页。
基于上图,假设一个目录项记录页最多只能存放 4 条目录项记录(实际可以存很多),现在继续插入一条主键值为 320 的普通用户记录,这时候就需要多分配一个新页。
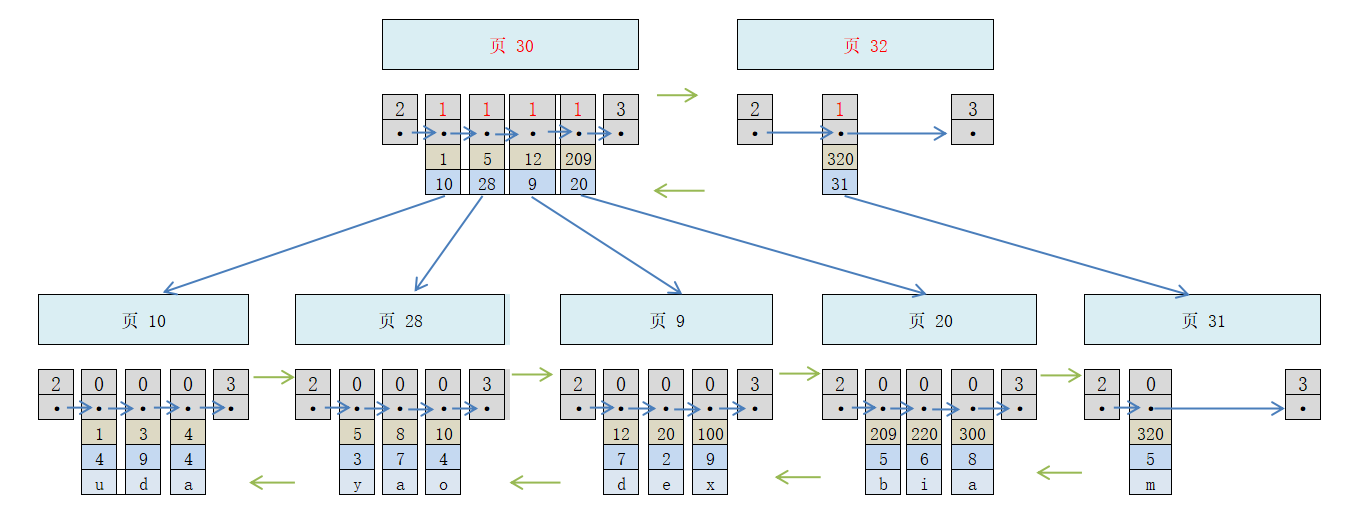
现在因为存储目录项记录的页是多个,此时再根据主键值查找一条用户记录,大致需要 3 个步骤(继续查找主键值为 20 的记录):
确定存储目录项记录的页。上图中有2个,分别是页 30 和页 32。因为页 30 表示的目录项主键值在 [1, 320),页 32 的主键值则不小于 320,所以主键 20的记录应该在 页30。
通过存储目录项记录的页确定用户记录真正所在的页(见上文第一部分)
在真正存储用户记录的页找到主键 20 的记录(见上文第一部分)
ok,解决了问题,又来了新的问题。当数据非常多,上面的2个目录项记录页也不够,又会有很多,那如何根据主键值快速定位一个存储目录项记录的页?
解决办法:目录项记录页不是多么?我再给这些页建个更高级的目录不就行了?可以想象一个多级目录,大目录里嵌套小目录,小目录里才是实际的数据。
基于上图,又会演变成这样:

- 生成了一个更高级的目录项记录的页 33
- 页中分别 2 条记录,代表页 30 和 页 32
- 如果用户记录的主键值在 [1, 320) 之间,则到页 30中继续查找
- 如果用户记录的主键值不小于 320,则到页 32 中继续查找
看出套路来了吧?随着表中记录的增加,这个目录的层级就会继续增加。
三、B+ 树
按照上面的套路,其实可以简化这个目录结构图:

其实这就是 B+ 树。
现在无论是存放用户记录的数据页,还是存放目录项记录的数据页,都存放到 B+ 树这种数据结构中。
- 所有的数据页都成为 B+ 树的节点。
- 真正存用户记录的数据页都在 B+树最底层的节点上,称为叶子节点或者叶节点。
- 而存放目录项记录的节点称为非叶子节点或者内节点。
- B+ 树最上面的节点称为根节点。
那如果说树的层级深了,找起来不也没那么快吗?
在之前的假设中规定了存放用户记录的页最多3条,存放目录项记录的最多4条,而实际上一个页存放的记录数量是非常大的。
现在继续假设,所有存放用户记录 的叶子节点的数据页可以存放 100 条用户记录,所有存放目录项记录的非叶子节点的数据页可以存放 1000 条目录项记录,那么:
- 如果 B+树只有 1 层,也就是说只有 1 个用于存放用户记录的节点,那么只能存 100 条用户记录。
- 如果 B+树有 2 层,则最多存放 1000*100= 100000 条用户记录。
- 如果 B+树有 3 层,则最多存放 1000*1000*100= 100000000 条用户记录。
- 如果 B+树有 4 层,则最多存放 1000*1000*1000*100= 100000000000 条用户记录。
也就是说,如果有 4 层的话最多存 1000亿 条记录,很显然表里不会有这么多数据。所以在一般情况下,我们用到的 B+树不超过 4 层。
基于此,通过主键值去查询某条记录,最多只需要进行 4 个页面内的查找(3个存储目录项的页,1个存储用户记录的页)。而在每个页面内有存在页目录 Page Directory,所以在页面内也可以通过二分法快速定位记录。
本文参考书籍: 小孩子4919 《mysql是怎样运行的》
以上就是Mysql InnoDB B+树索引目录项记录页管理的详细内容,更多关于Mysql InnoDB B+树索引目录记录的资料请关注我们其它相关文章!
相关推荐
-

为什么Mysql 数据库表中有索引还是查询慢
目录 前言: 1.字段类型不匹配导致的索引失效 2.被索引字段使用了表达式计算 3.被索引字段使用了内置函数 4.like 使用了 %X 模糊匹配 5.索引字段不是联合索引字段的最左字段 6.or 分割的条件 7.in.not in 可能会导致索引失效 总结 前言: 问题分析: 在进行数据库查询的时候,我们都知道索引可以加快数据查询的效率.但是在实际的业务场景下,经常会遇到即使在表中增加了索引,但是同样还是会出现数据查询慢的问题.这就需要具体分析数据查询慢的具体原因到底是什么了. 首先需要进行确
-
MySQL优化中B树索引知识点总结
为什么要进行SQL优化呢?很显然,当我们去写sql语句时: 1会发现性能低 2.执行时间太长, 3.或等待时间太长 4.sql语句欠佳,以及我们索引失效 5.服务器参数设置不合理 SQL语句执行过程分析 1.编写过程: 编写过程就是我们平常写sql语句的过程,也可以理解为编写顺序,以下就是我们编写顺序: select from join on where 条件 group by 分组 having过滤组 order by排序 limit限制查询个数 我们虽然是这样去写的,但是它mysql的引擎去
-
Mysql InnoDB聚簇索引二级索引联合索引特点
目录 一.聚簇索引 特点 1 特点 2 二.二级索引 三.联合索引 接上一篇内容:https://www.jb51.net/article/249934.htm 一.聚簇索引 其实之前内容中介绍的 B+ 树就是聚簇索引. 这种索引不需要我们显示地使用 INDEX 语句去创建,InnoDB 引擎会自动创建.另外,在 InnoDB 引擎中,聚簇索引就是数据的存储方式. 它有 2 个特点: 特点 1 使用记录主键值的大小进行记录和页的排序. 其中又包含了下面 3 个点: 页(包括叶节点和内节点)内的记
-
Mysql InnoDB中B+树索引使用注意事项
目录 一.根页面万年不动 二.内节点中目录项记录的唯一性 三.一个页面至少容纳 2 条记录 一.根页面万年不动 在之前的文章里,为了方便理解,都是先画存储用户记录的叶子节点,然后再画出存储目录项记录的内节点. 但实际上 B+ 树的行成过程是这样的: 每当为某个表创建一个 B+ 树索引,都会为这个索引创建一个根节点页面.最开始表里没数据,所以根节点中既没有用户记录,也没有目录项记录. 当往表里插入用户记录时,先把用户记录存储到这个根节点上. 当根节点页空间用完,继续插入记录,此时会将根节点中所有记
-
浅谈MySQL的B树索引与索引优化小结
MySQL的MyISAM.InnoDB引擎默认均使用B+树索引(查询时都显示为"BTREE"),本文讨论两个问题: 为什么MySQL等主流数据库选择B+树的索引结构? 如何基于索引结构,理解常见的MySQL索引优化思路? 为什么索引无法全部装入内存 索引结构的选择基于这样一个性质:大数据量时,索引无法全部装入内存. 为什么索引无法全部装入内存?假设使用树结构组织索引,简单估算一下: 假设单个索引节点12B,1000w个数据行,unique索引,则叶子节点共占约100MB,整棵树最多20
-
MySQL中B树索引和B+树索引的区别详解
目录 1.多路搜索树 2.B树-多路平衡搜索树 3.B树索引 4.B+树索引 总结 如果用树作为索引的数据结构,每查找一次数据就会从磁盘中读取树的一个节点,也就是一页,而二叉树的每个节点只存储一条数据,并不能填满一页的存储空间,那多余的存储空间岂不是要浪费了?为了解决二叉平衡搜索树的这个弊端,我们应该寻找一种单个节点可以存储更多数据的数据结构,也就是多路搜索树. 1. 多路搜索树 1.完全二叉树高度:O(log2N),其中2为对数,树每层的节点数: 2.完全M路搜索树的高度:O(logmN),其
-
Mysql InnoDB B+树索引目录项记录页管理
目录 Mysql InnoDB B+树索引目录项记录管理 一.目录项记录页 二.当目录项记录页也变多后 三.B+ 树 Mysql InnoDB B+树索引目录项记录管理 接上一篇内容,InnoDB 的作者想到一种更灵活的方式来管理所有目录项,是什么? 一.目录项记录页 其实这些用户目录项与用户记录很像,只是目录项中的两个列记录的是主键和页号而已,那么就可以复用之前存储用户记录的数据页来存储目录项. 为了区分用户记录和目录项,仍然使用 record_type 这个属性,当值为 1 时,表示目录项记
-
mysql 使用B+树索引有哪些优势
搞懂这个问题之前,我们首先来看一下MySQL表的存储结构,再分别对比二叉树.多叉树.B树和B+树的区别就都懂了. MySQL的存储结构 表存储结构 单位:表>段>区>页>行 在数据库中, 不论读一行,还是读多行,都是将这些行所在的页进行加载.也就是说存储空间的基本单位是页. 一个页就是一棵树B+树的节点,数据库I/O操作的最小单位是页,与数据库相关的内容都会存储在页的结构里. B+树索引结构 在一棵B+树中,每个节点为都是一个页,每次新建节点的时候,就会申请一个页空间 同一层的节点
-
Mysql InnoDB引擎的索引与存储结构详解
前言 在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的. 而MySql数据库提供了多种存储引擎.用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎. MySQL主要存储引擎的区别 MySQL默认的存储引擎是MyISAM,其他常用的就是InnoDB,另外还有MERGE.MEMORY(HEAP)等. 主要的几个存储引擎 MyISAM管理非事务表,提供高速存储和检索,以及全文搜索能力. MyISAM是Mysql的
-
MySQL高级篇之索引的数据结构详解
目录 1.为什么使用索引? 2.索引的优缺点 3.InnoDB中的索引 3.1 设计索引 3.2 常见索引概念 3.2.1 聚簇索引 3.2.2 非聚簇索引 3.2.3 联合索引 4.InnoDB与MyISAM的索引对比 5.B-Tree和B+Tree的差异 总结 1.为什么使用索引? 假如给数据使用 二叉树 这样的数据结构进行存储,如下图所示 2.索引的优缺点 MySQL 官方对索引的定义为: 索引(Index )是帮助 MySQL 高效获取数据的数据结构 .索引的本质: 索引是数据结构.你可
-
Mysql InnoDB引擎中的数据页结构详解
目录 Mysql InnoDB引擎数据页结构 一.页的简介 二.数据页的结构 三.记录在页中的存储结构 四.记录头信息 1. deleted_flag 2. min_rec_flag 3. n_owned 4. heap_no 5. record_type 6. next_record Mysql InnoDB引擎数据页结构 InnoDB 是 mysql 的默认引擎,也是我们最常用的,所以基于 InnoDB,学习页结构.而学习页结构,是为了更好的学习索引. 一.页的简介 页是 InnoDB 管理
-
mysql性能优化之索引优化
作为免费又高效的数据库,mysql基本是首选.良好的安全连接,自带查询解析.sql语句优化,使用读写锁(细化到行).事物隔离和多版本并发控制提高并发,完备的事务日志记录,强大的存储引擎提供高效查询(表记录可达百万级),如果是InnoDB,还可在崩溃后进行完整的恢复,优点非常多.即使有这么多优点,仍依赖人去做点优化,看书后写个总结巩固下,有错请指正. 完整的mysql优化需要很深的功底,大公司甚至有专门写mysql内核的,sql优化攻城狮,mysql服务器的优化,各种参数常量设定,查询语句优化,主