python之MSE、MAE、RMSE的使用
我就废话不多说啦,直接上代码吧!
target = [1.5, 2.1, 3.3, -4.7, -2.3, 0.75]
prediction = [0.5, 1.5, 2.1, -2.2, 0.1, -0.5]
error = []
for i in range(len(target)):
error.append(target[i] - prediction[i])
print("Errors: ", error)
print(error)
squaredError = []
absError = []
for val in error:
squaredError.append(val * val)#target-prediction之差平方
absError.append(abs(val))#误差绝对值
print("Square Error: ", squaredError)
print("Absolute Value of Error: ", absError)
print("MSE = ", sum(squaredError) / len(squaredError))#均方误差MSE
from math import sqrt
print("RMSE = ", sqrt(sum(squaredError) / len(squaredError)))#均方根误差RMSE
print("MAE = ", sum(absError) / len(absError))#平均绝对误差MAE
targetDeviation = []
targetMean = sum(target) / len(target)#target平均值
for val in target:
targetDeviation.append((val - targetMean) * (val - targetMean))
print("Target Variance = ", sum(targetDeviation) / len(targetDeviation))#方差
print("Target Standard Deviation = ", sqrt(sum(targetDeviation) / len(targetDeviation)))#标准差
补充拓展:回归模型指标:MSE 、 RMSE、 MAE、R2
sklearn调用
# 测试集标签预测
y_predict = lin_reg.predict(X_test)
# 衡量线性回归的MSE 、 RMSE、 MAE、r2
from math import sqrt
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
print("mean_absolute_error:", mean_absolute_error(y_test, y_predict))
print("mean_squared_error:", mean_squared_error(y_test, y_predict))
print("rmse:", sqrt(mean_squared_error(y_test, y_predict)))
print("r2 score:", r2_score(y_test, y_predict))
原生实现
# 测试集标签预测
y_predict = lin_reg.predict(X_test)
# 衡量线性回归的MSE 、 RMSE、 MAE
mse = np.sum((y_test - y_predict) ** 2) / len(y_test)
rmse = sqrt(mse)
mae = np.sum(np.absolute(y_test - y_predict)) / len(y_test)
r2 = 1-mse/ np.var(y_test)
print("mse:",mse," rmse:",rmse," mae:",mae," r2:",r2)
相关公式
MSE

RMSE

MAE
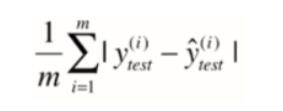
R2
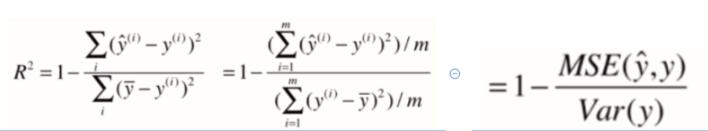
以上这篇python之MSE、MAE、RMSE的使用就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
使用Tensorflow将自己的数据分割成batch训练实例
学习神经网络的时候,网上的数据集已经分割成了batch,训练的时候直接使用batch.next()就可以获取batch,但是有的时候需要使用自己的数据集,然而自己的数据集不是batch形式,就需要将其转换为batch形式,本文将介绍一个将数据打包成batch的方法. 一.tf.slice_input_producer() 首先需要讲解两个函数,第一个函数是 :tf.slice_input_producer(),这个函数的作用是从输入的tensor_list按要求抽取一个tensor放入文件名队列
-
python之MSE、MAE、RMSE的使用
我就废话不多说啦,直接上代码吧! target = [1.5, 2.1, 3.3, -4.7, -2.3, 0.75] prediction = [0.5, 1.5, 2.1, -2.2, 0.1, -0.5] error = [] for i in range(len(target)): error.append(target[i] - prediction[i]) print("Errors: ", error) print(error) squaredError = [] abs
-

10个Python常用的损失函数及代码实现分享
目录 什么是损失函数 损失函数与度量指标 为什么要用损失函数 回归问题 1.均方误差(MSE) 2.平均绝对误差(MAE) 3.均方根误差(RMSE) 4.平均偏差误差(MBE) 5.Huber损失 二元分类 6.最大似然损失(Likelihood Loss/LHL) 7.二元交叉熵(BCE) 8.Hinge Loss 和 Squared Hinge Loss (HL and SHL) 多分类 9.交叉熵(CE) 10.Kullback-Leibler 散度 (KLD) 什么是损失函数 损失函数
-
用scikit-learn和pandas学习线性回归的方法
对于想深入了解线性回归的童鞋,这里给出一个完整的例子,详细学完这个例子,对用scikit-learn来运行线性回归,评估模型不会有什么问题了. 1. 获取数据,定义问题 没有数据,当然没法研究机器学习啦.:) 这里我们用UCI大学公开的机器学习数据来跑线性回归. 数据的介绍在这:http://archive.ics.uci.edu/ml/datasets/Combined+Cycle+Power+Plant 数据的下载地址在这:http://archive.ics.uci.edu/ml/mach
-
对Keras自带Loss Function的深入研究
本文研究Keras自带的几个常用的Loss Function. 1. categorical_crossentropy VS. sparse_categorical_crossentropy 注意到二者的主要差别在于输入是否为integer tensor.在文档中,我们还可以找到关于二者如何选择的描述: 解释一下这里的Integer target 与 Categorical target,实际上Integer target经过独热编码就变成了Categorical target,举例说明: (类
-
PyTorch搭建CNN实现风速预测
目录 数据集 特征构造 一维卷积 数据处理 1.数据预处理 2.数据集构造 CNN模型 1.模型搭建 2.模型训练 3.模型预测及表现 数据集 数据集为Barcelona某段时间内的气象数据,其中包括温度.湿度以及风速等.本文将利用CNN来对风速进行预测. 特征构造 对于风速的预测,除了考虑历史风速数据外,还应该充分考虑其余气象因素的影响.因此,我们根据前24个时刻的风速+下一时刻的其余气象数据来预测下一时刻的风速. 一维卷积 我们比较熟悉的是CNN处理图像数据时的二维卷积,此时的卷积是一种局部
-
PyTorch搭建ANN实现时间序列风速预测
目录 数据集 特征构造 数据处理 1.数据预处理 2.数据集构造 ANN模型 1.模型训练 2.模型预测及表现 数据集 数据集为Barcelona某段时间内的气象数据,其中包括温度.湿度以及风速等.本文将简单搭建来对风速进行预测. 特征构造 对于风速的预测,除了考虑历史风速数据外,还应该充分考虑其余气象因素的影响.因此,我们根据前24个时刻的风速+下一时刻的其余气象数据来预测下一时刻的风速. 数据处理 1.数据预处理 数据预处理阶段,主要将某些列上的文本数据转为数值型数据,同时对原始数据进行归一
-
python 计算平均平方误差(MSE)的实例
我们要编程计算所选直线的平均平方误差(MSE), 即数据集中每个点到直线的Y方向距离的平方的平均数,表达式如下: MSE=1n∑i=1n(yi−mxi−b)2 最初麻烦的写法 # TODO 实现以下函数并输出所选直线的MSE def calculateMSE(X,Y,m,b): in_bracket = [] for i in range(len(X)): num = Y[i] - m*X[i] - b num = pow(num,2) in_bracket.append(num) all_su
-
python实现线性回归的示例代码
目录 1线性回归 1.1简单线性回归 1.2多元线性回归 1.3使用sklearn中的线性回归模型 1线性回归 1.1简单线性回归 在简单线性回归中,通过调整a和b的参数值,来拟合从x到y的线性关系.下图为进行拟合所需要优化的目标,也即是MES(Mean Squared Error),只不过省略了平均的部分(除以m). 对于简单线性回归,只有两个参数a和b,通过对MSE优化目标求极值(最小二乘法),即可求得最优a和b如下,所以在训练简单线性回归模型时,也只需要根据数据求解这两个参数值即可. 下面
-
Python绘制散点密度图的三种方式详解
目录 方式一 方式二 方式三 方式一 import matplotlib.pyplot as plt import numpy as np from scipy.stats import gaussian_kde from mpl_toolkits.axes_grid1 import make_axes_locatable from matplotlib import rcParams config = {"font.family":'Times New Roman',"fo
-
Python+SimpleRNN实现股票预测详解
目录 1.数据源 2.代码实现 3.完整代码 原理请查看前面几篇文章. 1.数据源 SH600519.csv 是用 tushare 模块下载的 SH600519 贵州茅台的日 k 线数据,本次例子中只用它的 C 列数据(如图 所示): 用连续 60 天的开盘价,预测第 61 天的开盘价. 2.代码实现 按照六步法: import 相关模块->读取贵州茅台日 k 线数据到变量 maotai,把变量 maotai 中前 2126 天数据中的开盘价作为训练数据,把变量 maotai 中后 300 天数