Python如何批量获取文件夹的大小并保存
很多时候,查看一个文件夹下的每个文件大小可以轻易的做到,因为文件后面就是文件尺寸,但是如果需要查看一个文件夹下面所有的文件夹对应的尺寸,就发现需要把鼠标放到对应的文件夹上,稍等片刻才会出结果。
有时候,我们需要查看几十个甚至于上百个文件夹,找出包含文件最多,空间占用最大的那个,就比较麻烦了。这段代码是我以前的代码,可以按大小排序输出文件夹大小到txt文件,供使用的方便。
格式化当时花了很长时间,最后发现使用‘YaHei.Consolas'字体可以解决,对齐后输出结果看起来还算舒服。
上代码:
import os
import datetime
def get_folder_size(path):
folder_size = 0
if not os.path.exists(path):
return folder_size
if os.path.isfile(path):
folder_size = os.path.getsize(path)
return folder_size
try:
if os.path.isdir(path):
with os.scandir(path) as directory_lists:
for directory_list in directory_lists:
if directory_list.is_dir():
sub_folder_size = get_folder_size(directory_list.path) # 递归获取大小
folder_size += sub_folder_size
elif directory_list.is_file():
file_size = os.path.getsize(directory_list.path)
folder_size += file_size
return folder_size
except:
pass
# 以下主要是为了格式化输出
def get_file_length(file_name):
characters = list(file_name)
ascii_length = 0
utf8_length = 0
for character in characters:
if ord(character) < 128:
ascii_length += 1
else:
utf8_length += 2
return ascii_length + utf8_length
def main(basedir):
with os.scandir(basedir) as dirs:
directory_size = []
for dir in dirs:
try:
if not dir.is_file():
dirsize = round(get_folder_size(dir.path) / 1000000) # return the file size in Mb
resformat = [dir.name, dirsize]
directory_size.append(resformat)
except:
pass
results = sorted(directory_size, key=lambda x: x[1], reverse=True) # return a list ordered by size
results = [[i[0], '文件夹大小:' + str(i[1]) + ' Mb'] for i in results]
with open(basedir + os.sep + datetime.date.today().isoformat() + '.txt', 'a+') as f:
for result in results:
# 按照50的宽度格式化输出结果
len1 = 50 - get_file_length(result[0]) + len(result[0])
len2 = 25 - get_file_length(result[1]) + len(result[1])
f.writelines('{:<{len1}s} {:>{len2}s}\n'.format(result[0], result[1], len1=len1, len2=len2))
print('The result was successfully saved in the directory with date as file name.')
if __name__ == "__main__":
basedir = input("Please input the directory you would like to know the sizes: ")
main(basedir)
如果输入相应的文件夹路径,输出结果如下:
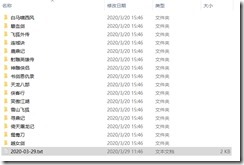
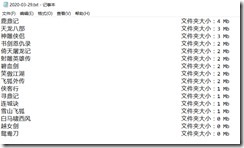
有时间我再简化一下代码,目前先这样。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python 获取当前目录下的文件目录和文件名实例代码详解
os模块下有两个函数: os.walk() os.listdir() # -*- coding: utf-8 -*- import os def file_name(file_dir): for root, dirs, files in os.walk(file_dir): print(root) #当前目录路径 print(dirs) #当前路径下所有子目录 print(files) #当前路径下所有非目录子文件 输出格式为: 当前文件目录路径 当前路径下子文件目录(若存在, 不存在则为 []
-
如何基于python操作json文件获取内容
这篇文章主要介绍了如何基于python操作json文件获取内容,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 写case时,将case 写到json文件比写到,写python一定要学会处理json 以下,是要处理的json 处理操作包括:打开json文件,获取json文件内容,关闭json文件,读取内容中的对应key的value { "name": "BeJson", "url": "
-
Python通过递归获取目录下指定文件代码实例
这篇文章主要介绍了python通过递归获取目录下指定文件代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 获取一个目录下所有指定格式的文件是实际生产中常见需求. import os #递归获取一个目录下所有的指定格式的文件 def get_jsonfile(path,file_list): dir_list=os.listdir(path) for x in dir_list: new_x=os.path.join(path,x) if
-
Python 获取指定文件夹下的目录和文件的实现
经常有需要扫描目录,对文件做批量处理的需求,所以对目录处理这块做了下学习和总结.Python 中扫描目录有两种方法:os.listdir 和 os.walk. 一.os.listdir 方法 os.listdir() 方法用于返回指定的目录下包含的文件或子目录的名字的列表.这个列表以字母顺序.其得到的是仅当前路径下的文件名,不包括子目录中的文件,如果需要得到所有文件需要递归. 它也不包括 '.' 和 '..' 即使它在目录中. 语法格式如下: os.listdir(path) 实例代码 def
-
python3获取文件中url内容并下载代码实例
这篇文章主要介绍了python3获取文件中url内容并下载代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2019-12-25 11:33 # @Author : Anthony # @Email : ianghont7@163.com # @File : get_video_audio_file.py import xlrd
-
Python3 获取文件属性的方式(时间、大小等)
os.stat(path) : 用于在给定的路径上执行一个系统 stat 的调用. path: 指定路径 返回值: st_mode: inode 保护模式 -File mode: file type and file mode bits (permissions). st_ino: inode 节点号. -Platform dependent, but if non-zero, uniquely identifies the file for a given value of st_dev. -
-
python爬虫 线程池创建并获取文件代码实例
本实例主要进行线程池创建,多线程获取.存储视频文件 梨视频:利用线程池进行视频爬取 #爬取梨视频数据 import requests import re from lxml import etree from multiprocessing.dummy import Pool import random # 定义获取视频数据方法 def getVideoData(url): # url为列表中的视频url return requests.get(url=url,headers=headers).
-
Python如何批量获取文件夹的大小并保存
很多时候,查看一个文件夹下的每个文件大小可以轻易的做到,因为文件后面就是文件尺寸,但是如果需要查看一个文件夹下面所有的文件夹对应的尺寸,就发现需要把鼠标放到对应的文件夹上,稍等片刻才会出结果. 有时候,我们需要查看几十个甚至于上百个文件夹,找出包含文件最多,空间占用最大的那个,就比较麻烦了.这段代码是我以前的代码,可以按大小排序输出文件夹大小到txt文件,供使用的方便. 格式化当时花了很长时间,最后发现使用'YaHei.Consolas'字体可以解决,对齐后输出结果看起来还算舒服. 上代码: i
-
python实现批量获取指定文件夹下的所有文件的厂商信息
本文实例讲述了python实现批量获取指定文件夹下的所有文件的厂商信息的方法.分享给大家供大家参考.具体如下: 功能代码如下: import os, string, shutil,re import pefile import codecs, sys import wx import struct #输出中打印Unicode字符 #sys.stdout = codecs.lookup('utf-8')[-1](sys.stdout) def addToDict(theDict,PEfile_Pa
-
Python实现批量压缩文件/文件夹zipfile的使用
目录 [Python压缩文件夹]导入"zipfile"模块 [python压缩文件]导入"zipfile"模块 补充 zipfile是python里用来做zip格式编码的压缩和解压缩的,由于是很常见的zip格式,所以这个模块使用频率也是比较高的, 在这里对zipfile的使用方法做一些记录.即方便自己也方便别人. Python zipfile模块用来做zip格式编码的压缩和解压缩的,要进行相关操作,首先需要实例化一个 ZipFile 对象.ZipFile 接受一个字
-
PHP获取文件夹大小函数用法实例
本文实例讲述了PHP获取文件夹大小函数用法.分享给大家供大家参考.具体如下: <?php // 获取文件夹大小 function getDirSize($dir) { $handle = opendir($dir); while (false!==($FolderOrFile = readdir($handle))) { if($FolderOrFile != "." && $FolderOrFile != "..") { if(is_dir(
-
C#获取文件夹及文件的大小与占用空间的方法
本文详细介绍了利用C#实现根据路径,计算这个路径所占用的磁盘空间的方法 . 网上有很多资料都是获取文件夹/文件的大小的.对于占用空间的很少有完整的代码.这里介绍实现这一功能的完整代码,供大家参考一下. 首先说下文件夹/文件大小与占用空间的区别. 这个是硬盘分区格式有关 大小是文件的实际大小,而占用空间是占硬盘的实际空间 以FAT32格式为例,硬盘的基本存储单位是簇,在FAT32中一簇是4KB 那么,也就是说即使文件只有1个字节,在硬盘上也要占到4KB的空间 如果文件是4KB零1个字节,那就要占用
-
C#实现获取文件夹大小的方法
本文实例讲述了C#实现获取文件夹大小的方法.分享给大家供大家参考.具体如下: 当然了,首先都需要引入System.IO这个命名空间 第一个方法: public static long GetDirectoryLength(string dirPath) { //判断给定的路径是否存在,如果不存在则退出 if (!Directory.Exists(dirPath)) return 0; long len = 0; //定义一个DirectoryInfo对象 DirectoryInfo di = n
-
python批量修改文件夹及其子文件夹下的文件内容
前言:前几天我看一位同学要修改很多文件中的数据,该文件数据很规律,一行只有三个数,需要将每行最后一个数字改为负数,但文件有上千个,分布在每个文件夹下面以及它的多级子文件夹下,看他用excel手动改数据改的很痛苦,我突然想到用Python访问和操作文件,修改文件内容都很方便,于是在对Python不熟悉的情况下花了大半天写了下面的程序. 大概思路:先获取文件夹下所有文件名存在列表中,然后循环遍历访问文件内容,修改后写入新文件,考虑到还有子文件夹,这里用了递归的方法访问子文件夹的文件,最后修改完再把原
-
C#获取文件夹所占空间大小的功能
虽然现在硬盘越来越大,但是清理垃圾还是必要的.这时我们往往需要一个获取文件夹所占空间大小的功能,从而判断垃圾文件的位置. 这个时候,我们常用的在右键属性中查看文件夹所占空间的方法显得效率实在太低.往往需要一些工具来辅助实现这个功能.一般有两个工具可以实现这个功能:diruse和du.diruse是MS在系统中的一个附加的工具,du是sysinternals公司的,不过sysinternals好像已经被MS收购了.这两个工具都是命令行工具,但也保持着MS一贯的简单易用的特点. 这里以diruse为
-

Python实现合并同一个文件夹下所有PDF文件的方法示例
本文实例讲述了Python实现合并同一个文件夹下所有PDF文件的方法.分享给大家供大家参考,具体如下: 一.需求说明 下载了网易云课堂的吴恩达免费的深度学习的pdf文档,但是每一节是一个pdf,我把这些PDF文档放在一个文件夹下,希望合并成一个PDF文件.于是写了一个python程序,很好的解决了这个问题. 二.数据形式 三.合并效果 四.python代码实现 # -*- coding:utf-8*- import sys reload(sys) sys.setdefaultencoding('
-
python实现批量移动文件
本文通过实例为大家分享了python实现批量移动文件的具体代码,供大家参考,具体内容如下 任务:每个大文件夹下有许多小文件夹,将小文件夹里的pdf文件移动到指定文件夹.如图: 最终效果: 废话不多说 上源码: import os import shutil path_main = r"C:\Users\e2164\Desktop\待处理文件夹"#待处理文件夹路径 filelist_main = os.listdir(path_main) #将"待处理文件夹"下的文件