配置python连接oracle读取excel数据写入数据库的操作流程
前提条件:本地已经安装好oracle单实例,能使用plsql developer连接,或者能使用TNS连接串远程连接到oracle集群
读取excel写入数据库的方式有多种,这里介绍的是使用pandas写入,相对来说比较简便,不需要在读取excel后再去整理数据
整个过程需要分两步进行:
一、配置python连接oracle并测试成功
网上有不少教程,但大部分都没那么详细,并且也没有说明连接单实例和连接集群的区别,这里先介绍连接oracle单实例的方式,后续再补充连接oracle集群方式。
版本:
window 10 64位
python 3.6.8
cx-Oracle 7.3.0
安装流程:
1、使用pip安装操作oracle的包:
pip install cx_Oracle==7.3.0
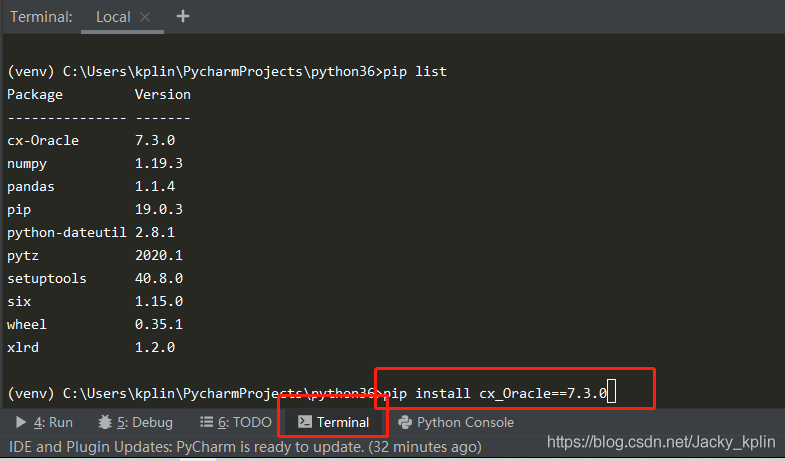
2、手动配置cx_Oracle临时客户端:
注意这里电脑是64位的,使用的即时客户端也是64位的,32位的需要另外到下面的下载地址找一下
2.1、解压下面的文件
链接: https://pan.baidu.com/s/12iMCBjKvl-Lao9iOHMT-yw
提取码: pxmq
oracle即时客户端使用说明:
https://docs.oracle.com/en/database/oracle/oracle-database/19/lnoci/instant-client.html#GUID-6895DB45-97AA-4738-9959-BD677D610186
oracle即时客户端下载地址:
https://www.oracle.com/database/technologies/instant-client/downloads.html
2.2、放置到D盘某个位置,例如:
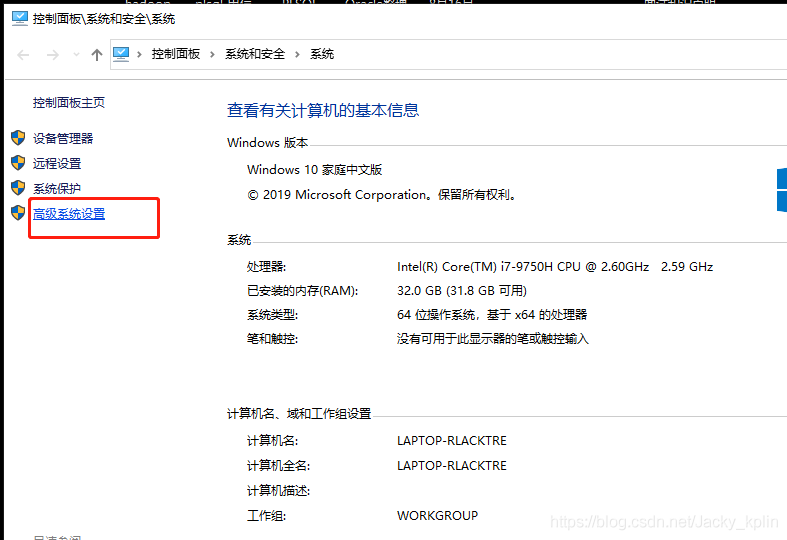
2.3、配置环境变量
控制面板——系统和安全——系统

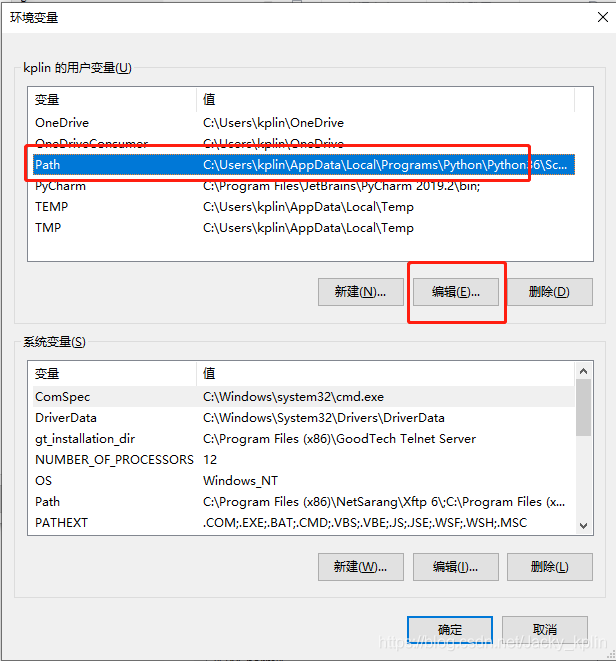
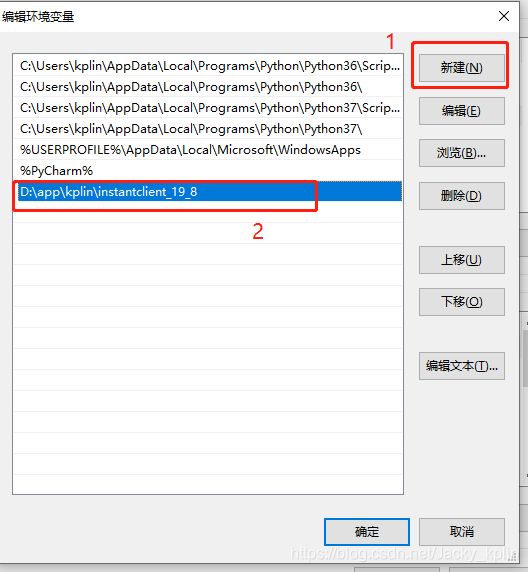
2.4、重启电脑,让新配置的环境变量生效
2.5、测试配置是否成功
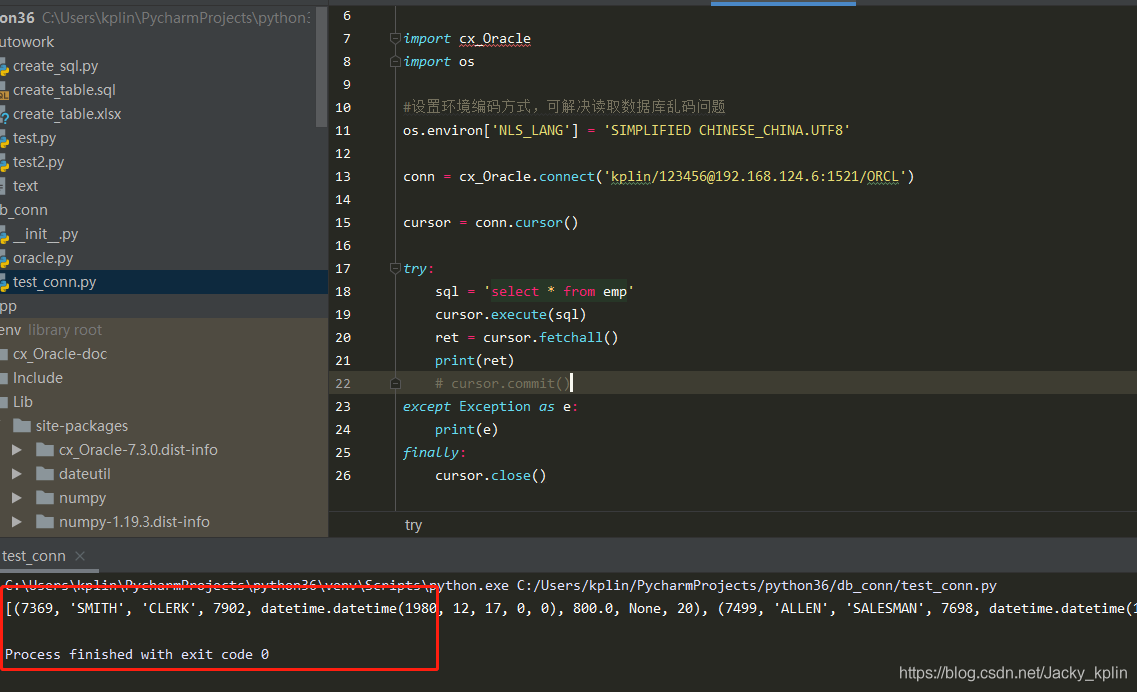
虽然导入cx_Oracle有红色波浪线,一般认为导入不成功,但这里可以先不管它,直接运行测试代码,没有报错说明没问题。
如果没有查到数据,也可能是该用户下没有emp表。
import cx_Oracle
import os
# 设置环境编码方式,可解决读取数据库中文乱码问题
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8'
# 用户名/密码@IP:端口/实例名
conn = cx_Oracle.connect('kplin/12sss3456@192.168.124.102:1521/ORCL')
cursor = conn.cursor()
try:
sql = 'select * from emp'
cursor.execute(sql)
ret = cursor.fetchall()
print(ret)
# cursor.commit()
except Exception as e:
print(e)
finally:
cursor.close()
二、使用pandas读取excel数据,使用sqlalchemy协助写入数据库
1、安装sqlalchemy,pandas
这里指定pandas版本是因为最新版的pandas在读写excel的时候会有些奇怪的报错,换成1.1.4版本即可。
pip install pandas==1.1.4 pip install sqlalchemy
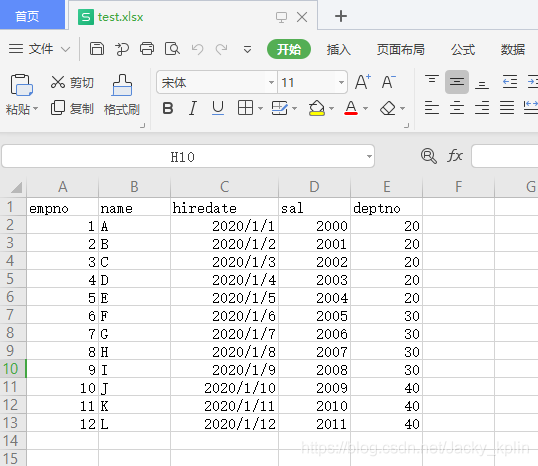
2、准备一个excel表,命名为test.xlsx,写入以下测试数据
3、测试读取并写入数据库
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# date: 2021/3/14
# filename: excel_to_db
# author: kplin
import pandas as pd
from sqlalchemy import create_engine
from sqlalchemy import types
# conn_string='oracle+cx_oracle://user:pass@host:port/dbname'
conn_string='oracle+cx_oracle://KPLIN:654321@192.168.124.6:1521/ORCL'
engine = create_engine(conn_string, echo=False)
df = pd.read_excel('test.xlsx')
# if_exists有三个可选值,'fail':如果存在该表则报错,'append':如果存在该表则将数据追加到列尾,'replace':如果存在该表则替换
# df.to_sql('test', con=engine, if_exists='replace')
# 按上面这种写入方式name字段将被写成clob字段类型,
# 如果我们希望把name改为varchar2类型,怎么做?
# 我们可以利用sqlalchemy的types把name指定为varchar2()类型
len = df.name.str.len().max()
df.to_sql('test', engine, if_exists='replace', dtype={'name': types.VARCHAR(len)})
rows = engine.execute("SELECT * FROM TEST").fetchall()
print(rows)
到此这篇关于配置python连接oracle读取excel数据写入数据库的操作流程的文章就介绍到这了,更多相关python读取excel数据写入oracle数据库内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python写入已存在的excel数据实例
python可以使用xlrd读excel,使用xlwt写excel,但是如果要把数据写入已存在的excel,需要另外一个库xlutils配合使用. 大概思路: 1.用xlrd.open_workbook打开已有的xsl文件 注意添加参数formatting_info=True,得以保存之前数据的格式 2.然后用,from xlutils.copy import copy;,之后的copy去从打开的xlrd的Book变量中,拷贝出一份,成为新的xlwt的Workbook变量 3.然后对于xlwt的
-
用Python将Excel数据导入到SQL Server的例子
使用环境:Win10 x64 Python:3.6.4 SqlServer:2008R2 因为近期需要将excel导入到SQL Server,但是使用的是其他语言,闲来无事就尝试着用python进行导入,速度还是挺快的,1w多条数据,也只用了1s多,代码也比较简单,就不多解释了. 用到的库有xlrd(用来处理excel),pymssql(用来连接使用sql server) import xlrd import pymssql import datetime # 连接本地sql server
-
Python修改Excel数据的实例代码
在前面的文章中介绍了如何用Python读写Excel数据,今天再介绍一下如何用Python修改Excel数据.需要用到xlutils模块.下载地址为https://pypi.python.org/pypi/xlutils.下载后执行python setup.py install命令进行安装即可.具体使用代码如下: 复制代码 代码如下: #-*-coding:utf-8-*-from xlutils.copy import copy # http://pypi.python.org/pypi
-
Python matplotlib读取excel数据并用for循环画多个子图subplot操作
读取excel数据需要用到xlrd模块,在命令行运行下面命令进行安装 pip install xlrd 表格内容大致如下,有若干sheet,每个sheet记录了同一所学校的所有学生成绩,分为语文.数学.英语.综合.总分 考号 姓名 班级 学校 语文 数学 英语 综合 总分 ... ... ... ... 136 136 100 57 429 ... ... ... ... 128 106 70 54 358 ... ... ... ... 110.5 62 92 44 308.5 画多张子图需要
-

python读取并定位excel数据坐标系详解
测试数据:坐标数据:testExcelData.xlsx 使用python读取excel文件需要安装xlrd库: xlrd下载后的压缩文件:xlrd-1.2.0.tar.gz 解压后再进行安装即可,具体安装方法请另行百度. 代码 import xlrd import matplotlib.pyplot as plt import numpy as np #打开文件 data = xlrd.open_workbook(r'testExcelData.xlsx') #获取表格数目 nums = le
-
Python利用pandas处理Excel数据的应用详解
最近迷上了高效处理数据的pandas,其实这个是用来做数据分析的,如果你是做大数据分析和测试的,那么这个是非常的有用的!!但是其实我们平时在做自动化测试的时候,如果涉及到数据的读取和存储,那么而利用pandas就会非常高效,基本上3行代码可以搞定你20行代码的操作!该教程仅仅限于结合柠檬班的全栈自动化测试课程来讲解下pandas在项目中的应用,这仅仅只是冰山一角,希望大家可以踊跃的去尝试和探索! 一.安装环境: 1:pandas依赖处理Excel的xlrd模块,所以我们需要提前安装这个,安装命令
-
使用python将excel数据导入数据库过程详解
因为需要对数据处理,将excel数据导入到数据库,记录一下过程. 使用到的库:xlrd 和 pymysql (如果需要写到excel可以使用xlwt) 直接丢代码,使用python3,注释比较清楚. import xlrd import pymysql # import importlib # importlib.reload(sys) #出现呢reload错误使用 def open_excel(): try: book = xlrd.open_workbook("XX.xlsx")
-
Python导入数值型Excel数据并生成矩阵操作
riginal_Data 因为程序是为了实现对纯数值型Excel文档进行导入并生成矩阵,因此有必要对第五列文本值进行删除处理. Import_Data import numpy as np import xlrd def import_excel_matrix(path): table = xlrd.open_workbook(path).sheets()[0] # 获取第一个sheet表 row = table.nrows # 行数 col = table.ncols # 列数 datamat
-
python读取excel数据绘制简单曲线图的完整步骤记录
python读写excel文件有很多种方法: 用xlrd和xlwt进行excel读写 用openpyxl进行excel读写 用pandas进行excel读写 本文使用xlrd读取excel文件(xls,sxls格式),使用xlwt向excel写入数据 一.xlrd和xlwt的安装 安装很简单,windos+r调出运行窗口,输入cmd,进入命令行窗口,输入以下命令. 安装xlrd: pip install xlrd 安装xlwt: pip install xlwt xlrd的API(applica
-
配置python连接oracle读取excel数据写入数据库的操作流程
前提条件:本地已经安装好oracle单实例,能使用plsql developer连接,或者能使用TNS连接串远程连接到oracle集群 读取excel写入数据库的方式有多种,这里介绍的是使用pandas写入,相对来说比较简便,不需要在读取excel后再去整理数据 整个过程需要分两步进行: 一.配置python连接oracle并测试成功 网上有不少教程,但大部分都没那么详细,并且也没有说明连接单实例和连接集群的区别,这里先介绍连接oracle单实例的方式,后续再补充连接oracle集群方式. 版本
-
python 使用openpyxl读取excel数据
openpyxl介绍 openpyxl是一个开源项目,它是一个用于读取/写入Excel 2010文档(如xlsx .xlsm .xltx .xltm文件 )的Python库,如果要处理更早格式的Excel文档(xls),需要用到其它库(如:xlrd.xlwt等),这是openpyxl比较其他模块的不足之处.openpyxl是一款比较综合的工具,不仅能够同时读取和修改Excel文档,而且可以对Excel文件内单元格进行详细设置,包括单元格样式等内容,甚至还支持图表插入.打印设置等内容. p
-
Oracle读取excel数据
推荐阅读:Oracle导出excel数据 废话不多说了,直接给大家奔入主题了. --解析excel,转换成table,可供查询,支持xls.xlsx --首先修改这个Type,长度改为4000. CREATE OR REPLACE TYPE XYG_PUB_DATA_UPLOAD_Obj AS OBJECT( SOURCE_TYPE VARCHAR2(240)--EXCEL/TXT ,BATCH_CODE VARCHAR2 (480 BYTE)--批的Code,Excel用,因为一个Excel可
-
Oracle导出excel数据
推荐阅读:Oracle读取excel数据 oracle导出excel(非csv)的方法有两种,1.使用sqlplus spool,2.使用包体 现将网上相关代码整理后贴出以备不时之需: 使用sqlplus: 使用sqlplus需要两个文件:sql脚本文件和格式设置文件. 去除冗余信息,main.sql --main.sql 注意,需要在sqlplus下运行 非plsql命令行下 set linesize 200 set term off verify off feedback off pages
-
python从Oracle读取数据生成图表
初次学习python,连接Oracle数据库,导出数据到Excel,再从Excel里面读取数据进行绘图,生成png保存出来. 1.涉及到的python模块(模块安装就不进行解释了): import os import cx_Oracle import openpyxl import time import csv import xlrd from matplotlib import pyplot as plt from matplotlib import font_manager 2.连接数据库
-
Python连接Oracle之环境配置、实例代码及报错解决方法详解
Oracle Client 安装 1.环境 日期:2019年8月1日 公司已经安装好Oracle服务端 Windows版本:Windows10专业版 系统类型:64位操作系统,基于x64的处理器 Python版本:Python 3.6.4 :: Anaconda, Inc. 2.下载网址 https://www.oracle.com/database/technologies/instant-client/downloads.html 3.解压至目录 解压后(这里放D盘) 4.配置环境变量 控制
-
Python自动化办公之读取Excel数据的实现
目录 前言 Excel 读取 - xlrd 常用函数介绍 获取 excel 对象 获取工作簿 读取工作簿内容 前言 之前的章节我们学习了 python 关于 word 文件相关操作的知识点,从今天开始讲学习关于 excel 的相关操作,来看一下关于即将学习的 excel 相关知识点都有哪些? 如何读取 excel 文件 如何生成 excel 文件 如何在 excel 中生成基础的图表 目标:实现对 excel 的最基础的读写内容 该篇章所使用的新的模块 xlrd —> excel 的读取模块 x
-
Python自动化办公之Excel数据的写入
目录 Excel 写入 - xlsxwriter xlsxwriter 的安装 xlsxwriter 常用函数介绍 初始化 excel 对象 获取工作簿 小实战 上一章节我们学习了 excel 的读取模块 - xlrd ,今天章节将学习 excel 的写入模块 - xlsxwriter .通过该章节的学习,就可以自己主动生成 excel 文件了. Excel 写入 - xlsxwriter xlsxwriter 的安装 安装方式: pip install xlsxwriter 若安装不上或者安装
-
基于python连接oracle导并出数据文件
python连接oracle,感觉table_list文件内的表名,来卸载数据文件 主脚本: import os import logging import sys import configparser import subprocess import cx_Oracle #判断输入参数个数 class param(): def check_para(self): if len(sys.argv) != 1: print("请输入正确的参数:yyyymmdd") exit(1) el