PyTorch 如何检查模型梯度是否可导
一、PyTorch 检查模型梯度是否可导
当我们构建复杂网络模型或在模型中加入复杂操作时,可能会需要验证该模型或操作是否可导,即模型是否能够优化,在PyTorch框架下,我们可以使用torch.autograd.gradcheck函数来实现这一功能。
首先看一下官方文档中关于该函数的介绍:
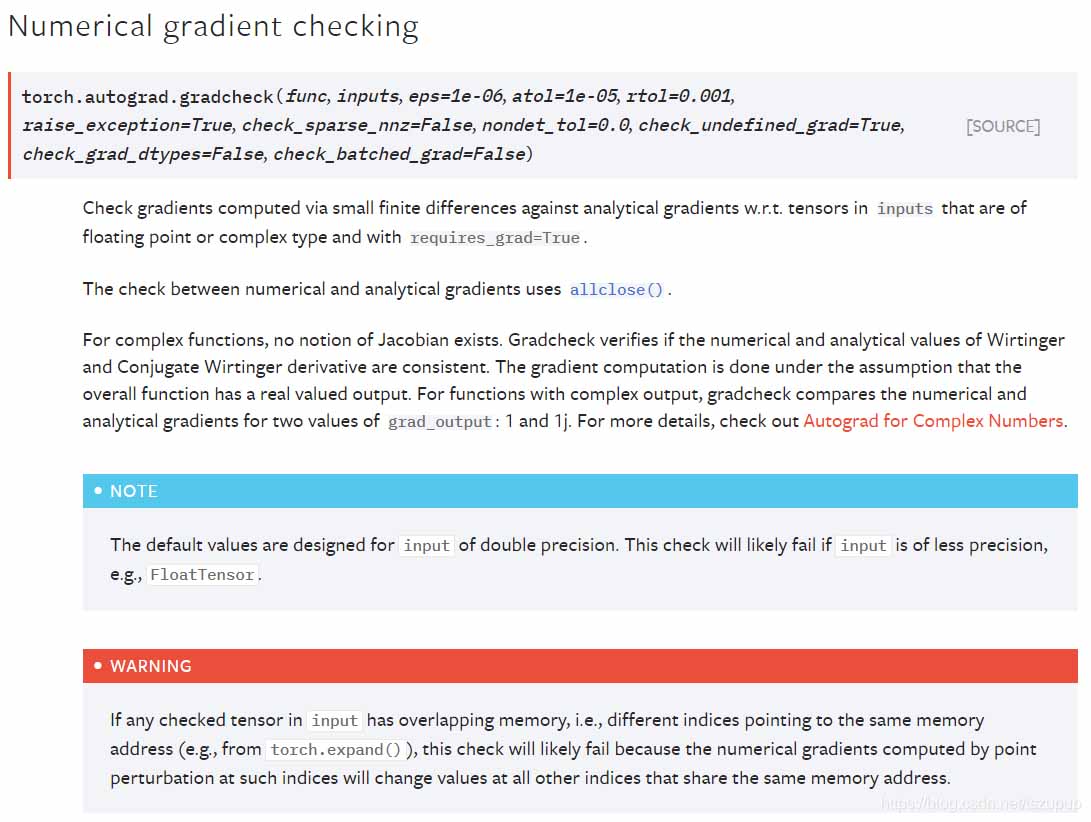

可以看到官方文档中介绍了该函数基于何种方法,以及其参数列表,下面给出几个例子介绍其使用方法,注意:
Tensor需要是双精度浮点型且设置requires_grad = True
第一个例子:检查某一操作是否可导
from torch.autograd import gradcheck
import torch
import torch.nn as nn
inputs = torch.randn((10, 5), requires_grad=True, dtype=torch.double)
linear = nn.Linear(5, 3)
linear = linear.double()
test = gradcheck(lambda x: linear(x), inputs)
print("Are the gradients correct: ", test)
输出为:
Are the gradients correct: True
第二个例子:检查某一网络模型是否可导
from torch.autograd import gradcheck
import torch
import torch.nn as nn
# 定义神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.net = nn.Sequential(
nn.Linear(15, 30),
nn.ReLU(),
nn.Linear(30, 15),
nn.ReLU(),
nn.Linear(15, 1),
nn.Sigmoid()
)
def forward(self, x):
y = self.net(x)
return y
net = Net()
net = net.double()
inputs = torch.randn((10, 15), requires_grad=True, dtype=torch.double)
test = gradcheck(net, inputs)
print("Are the gradients correct: ", test)
输出为:
Are the gradients correct: True
二、Pytorch求导
1.标量对矩阵求导

验证:
>>>import torch
>>>a = torch.tensor([[1],[2],[3.],[4]]) # 4*1列向量
>>>X = torch.tensor([[1,2,3],[5,6,7],[8,9,10],[5,4,3.]],requires_grad=True) #4*3矩阵,注意,值必须要是float类型
>>>b = torch.tensor([[2],[3],[4.]]) #3*1列向量
>>>f = a.view(1,-1).mm(X).mm(b) # f = a^T.dot(X).dot(b)
>>>f.backward()
>>>X.grad #df/dX = a.dot(b^T)
tensor([[ 2., 3., 4.],
[ 4., 6., 8.],
[ 6., 9., 12.],
[ 8., 12., 16.]])
>>>a.grad b.grad # a和b的requires_grad都为默认(默认为False),所以求导时,没有梯度
(None, None)
>>>a.mm(b.view(1,-1)) # a.dot(b^T)
tensor([[ 2., 3., 4.],
[ 4., 6., 8.],
[ 6., 9., 12.],
[ 8., 12., 16.]])
2.矩阵对矩阵求导


验证:
>>>A = torch.tensor([[1,2],[3,4.]]) #2*2矩阵
>>>X = torch.tensor([[1,2,3],[4,5.,6]],requires_grad=True) # 2*3矩阵
>>>F = A.mm(X)
>>>F
tensor([[ 9., 12., 15.],
[19., 26., 33.]], grad_fn=<MmBackward>)
>>>F.backgrad(torch.ones_like(F)) # 注意括号里要加上这句
>>>X.grad
tensor([[4., 4., 4.],
[6., 6., 6.]])
注意:
requires_grad为True的数组必须是float类型
进行backgrad的必须是标量,如果是向量,必须在后面括号里加上torch.ones_like(X)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

PyTorch 如何自动计算梯度
在PyTorch中,torch.Tensor类是存储和变换数据的重要工具,相比于Numpy,Tensor提供GPU计算和自动求梯度等更多功能,在深度学习中,我们经常需要对函数求梯度(gradient). PyTorch提供的autograd包能够根据输入和前向传播过程自动构建计算图,并执行反向传播. 本篇将介绍和总结如何使用autograd包来进行自动求梯度的有关操作. 1. 概念 Tensor是这个pytorch的自动求导部分的核心类,如果将其属性.requires_grad=True,它将开
-
PyTorch梯度裁剪避免训练loss nan的操作
近来在训练检测网络的时候会出现loss为nan的情况,需要中断重新训练,会很麻烦.因而选择使用PyTorch提供的梯度裁剪库来对模型训练过程中的梯度范围进行限制,修改之后,不再出现loss为nan的情况. PyTorch中采用torch.nn.utils.clip_grad_norm_来实现梯度裁剪,链接如下: https://pytorch.org/docs/stable/_modules/torch/nn/utils/clip_grad.html 训练代码使用示例如下: from torch
-
pytorch损失反向传播后梯度为none的问题
错误代码:输出grad为none a = torch.ones((2, 2), requires_grad=True).to(device) b = a.sum() b.backward() print(a.grad) 由于.to(device)是一次操作,此时的a已经不是叶子节点了 修改后的代码为: a = torch.ones((2, 2), requires_grad=True) c = a.to(device) b = c.sum() b.backward() print(a.grad)
-
pytorch 如何打印网络回传梯度
需求: 打印梯度,检查网络学习情况 net = your_network().cuda() def train(): ... outputs = net(inputs) loss = criterion(outputs, targets) loss.backward() for name, parms in net.named_parameters(): print('-->name:', name, '-->grad_requirs:',parms.requires_grad, \ ' --
-
Pytorch获取无梯度TorchTensor中的值
获取无梯度Tensor 遇到的问题: 使用两个网络并行运算,一个网络的输出值要给另一个网络反馈.而反馈的输出值带有网络权重的梯度,即grad_fn=<XXXBackward0>. 这时候如果把反馈值扔到第二网络中更新,会出现第一个计算图丢失无法更新的错误.哎哟喂,我根本不需要第一个网络的梯度好吗? 一开始用了一个笨办法,先转numpy,然后再转回torch.Tensor.因为numpy数据是不带梯度的. 但是我的原始tensor的放在cuda上的, cuda的张量是不能直接转Tensor,所以
-
浅谈pytorch中为什么要用 zero_grad() 将梯度清零
pytorch中为什么要用 zero_grad() 将梯度清零 调用backward()函数之前都要将梯度清零,因为如果梯度不清零,pytorch中会将上次计算的梯度和本次计算的梯度累加. 这样逻辑的好处是,当我们的硬件限制不能使用更大的bachsize时,使用多次计算较小的bachsize的梯度平均值来代替,更方便,坏处当然是每次都要清零梯度. optimizer.zero_grad() output = net(input) loss = loss_f(output, target) los
-
PyTorch 如何检查模型梯度是否可导
一.PyTorch 检查模型梯度是否可导 当我们构建复杂网络模型或在模型中加入复杂操作时,可能会需要验证该模型或操作是否可导,即模型是否能够优化,在PyTorch框架下,我们可以使用torch.autograd.gradcheck函数来实现这一功能. 首先看一下官方文档中关于该函数的介绍: 可以看到官方文档中介绍了该函数基于何种方法,以及其参数列表,下面给出几个例子介绍其使用方法,注意: Tensor需要是双精度浮点型且设置requires_grad = True 第一个例子:检查某一操作是否可
-
Pytorch实现将模型的所有参数的梯度清0
有两种方式直接把模型的参数梯度设成0: model.zero_grad() optimizer.zero_grad()#当optimizer=optim.Optimizer(model.parameters())时,两者等效 如果想要把某一Variable的梯度置为0,只需用以下语句: Variable.grad.data.zero_() 补充知识:PyTorch中在反向传播前为什么要手动将梯度清零?optimizer.zero_grad()的意义 optimizer.zero_grad()意思
-
PyTorch搭建多项式回归模型(三)
PyTorch基础入门三:PyTorch搭建多项式回归模型 1)理论简介 对于一般的线性回归模型,由于该函数拟合出来的是一条直线,所以精度欠佳,我们可以考虑多项式回归来拟合更多的模型.所谓多项式回归,其本质也是线性回归.也就是说,我们采取的方法是,提高每个属性的次数来增加维度数.比如,请看下面这样的例子: 如果我们想要拟合方程: 对于输入变量和输出值,我们只需要增加其平方项.三次方项系数即可.所以,我们可以设置如下参数方程: 可以看到,上述方程与线性回归方程并没有本质区别.所以我们可以采用线性回
-
pytorch中的自定义反向传播,求导实例
pytorch中自定义backward()函数.在图像处理过程中,我们有时候会使用自己定义的算法处理图像,这些算法多是基于numpy或者scipy等包. 那么如何将自定义算法的梯度加入到pytorch的计算图中,能使用Loss.backward()操作自动求导并优化呢.下面的代码展示了这个功能` import torch import numpy as np from PIL import Image from torch.autograd import gradcheck class Bicu
-
pytorch 权重weight 与 梯度grad 可视化操作
pytorch 权重weight 与 梯度grad 可视化 查看特定layer的权重以及相应的梯度信息 打印模型 观察到model下面有module的key,module下面有features的key, features下面有(0)的key,这样就可以直接打印出weight了 在pdb debug界面输入p model.module.features[0].weight,就可以看到weight,输入 p model.module.features[0].weight.grad 就可以查看梯度信息
-
深入理解Pytorch微调torchvision模型
目录 一.简介 二.导入相关包 三.数据输入 四.辅助函数 1.模型训练和验证 2.设置模型参数的'.requires_grad属性' 一.简介 在本小节,深入探讨如何对torchvision进行微调和特征提取.所有模型都已经预先在1000类的magenet数据集上训练完成. 本节将深入介绍如何使用几个现代的CNN架构,并将直观展示如何微调任意的PyTorch模型. 本节将执行两种类型的迁移学习: 微调:从预训练模型开始,更新我们新任务的所有模型参数,实质上是重新训练整个模型. 特征提取:从预训
-
PyTorch加载数据集梯度下降优化
目录 一.实现过程 1.准备数据 2.设计模型 3.构造损失函数和优化器 4.训练过程 5.结果展示 二.参考文献 一.实现过程 1.准备数据 与PyTorch实现多维度特征输入的逻辑回归的方法不同的是:本文使用DataLoader方法,并继承DataSet抽象类,可实现对数据集进行mini_batch梯度下降优化. 代码如下: import torch import numpy as np from torch.utils.data import Dataset,DataLoader clas
-
在 pytorch 中实现计算图和自动求导
前言: 今天聊一聊 pytorch 的计算图和自动求导,我们先从一个简单例子来看,下面是一个简单函数建立了 yy 和 xx 之间的关系 然后我们结点和边形式表示上面公式: 上面的式子可以用图的形式表达,接下来我们用 torch 来计算 x 导数,首先我们创建一个 tensor 并且将其requires_grad设置为True表示随后反向传播会对其进行求导. x = torch.tensor(3.,requires_grad=True) 然后写出 y = 3*x**2 + 4*x + 2 y.ba
-
浅谈pytorch grad_fn以及权重梯度不更新的问题
前提:我训练的是二分类网络,使用语言为pytorch Varibale包含三个属性: data:存储了Tensor,是本体的数据 grad:保存了data的梯度,本事是个Variable而非Tensor,与data形状一致 grad_fn:指向Function对象,用于反向传播的梯度计算之用 在构建网络时,刚开始的错误为:没有可以grad_fn属性的变量. 百度后得知要对需要进行迭代更新的变量设置requires_grad=True ,操作如下: train_pred = Variable(tr
-
pytorch 实现打印模型的参数值
对于简单的网络 例如全连接层Linear 可以使用以下方法打印linear层: fc = nn.Linear(3, 5) params = list(fc.named_parameters()) print(params.__len__()) print(params[0]) print(params[1]) 输出如下: 由于Linear默认是偏置bias的,所有参数列表的长度是2.第一个存的是全连接矩阵,第二个存的是偏置. 对于稍微复杂的网络 例如MLP mlp = nn.Sequential