python数据结构算法分析
目录
- 1.算法分析的定义
- 2. 大O记法
- 3. 不同算法的大O记法
- 3.1 清点法
- 3.2 排序法
- 3.3 蛮力法
- 3.4 计数法
- 4. 列表和字典操作的复杂度
- 4.1 列表
- 4.2 字典
前文学习:
python数据类型: python数据结构:数据类型.
python的输入输出: python数据结构输入输出及控制和异常.
python面向对象: python数据结构面向对象.
今天我们来学习的内容是面试题中都避免不小了的问题,就是算法分析了,什么是算法分析,算法分析是用来分析一个算法的好坏的,大家完成一件事情写不一样的算法,就需要算法分析来评判算法的好坏,最常见的就是程序的复杂的O(n)。
1.算法分析的定义
有这样一个问题:当两个看上去不同的程序 解决同一个问题时,会有优劣之分么?答案是肯定的。算法分析关心的是基于所使用的计算资源比较算法。我们说甲算法比乙算法好,依据是甲算法有更高的资源利用率或使用更少的资源。从这个角度来看,上面两个函数其实差不多,它们本质上都利用同一个算法解决累加问题。
计算资源究竟指什么?思考这个问题很重要。有两种思考方式。
- 一是考虑算法在解决问题时 要占用的空间或内存。解决方案所需的空间总量一般由问题实例本身决定,但算法往往也会有特定的空间需求。
- 二是根据算法执行所需的时间进行分析和比较。这个指标有时称作算法的执行 时间或运行时间。要 衡 量
sumOfN函数的执行时间,一个方法就是做基准分析。也就是说,我们会记录程序计算出结果所消耗的实际时间。在 Python 中,我们记录下函数就所处系统而言的开始时间和结束时间。time模块中有一个 time 函数,它会以秒为单位返回自指定时间点起到当前的系统时钟时间。在首尾各调用一次这个函数,计算差值,就可以得到以秒为单位的执行时间。
举个例子:我们需要求解前n个数之和,通过计算所需时间来评判效率好坏。(这里使用time函数,并计算5次来看看大致需要多少时间)
第一种方法:循环方案
import time
def sumOfN2(n):
start=time.time()
thesum=0
for i in range(1,n+1):
thesum=thesum+i
end=time.time()
return thesum,end-start
#循环5次
for i in range(5):
print("Sum is %d required %10.7f seconds" % sumOfN2(10000))
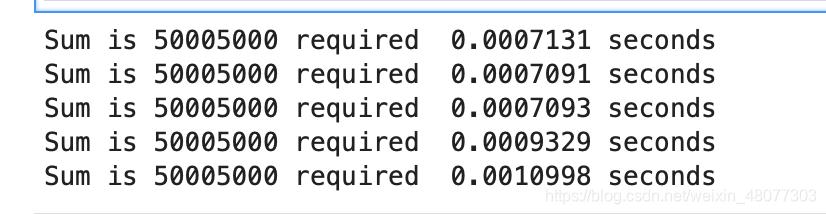
结果如下:
第二种方法:公式方法
#直接利用求和公式
def sumOfN3(n):
start=time.time()
thesum=(1+n)*n/2
end=time.time()
return thesum,end-start
for i in range(5):
print("Sum is %d required %10.7f seconds" % sumOfN3(10000))
结果如下:
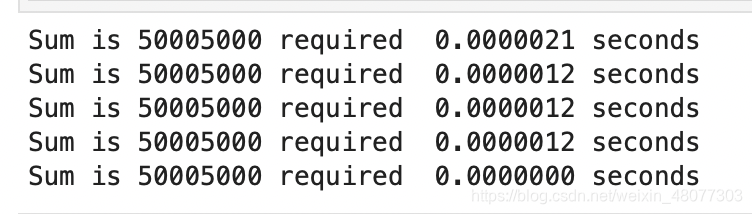
直觉上,循环方案看上去工作量更大,因为有些步骤重复。这好像是耗时更久的原因。而且,循环方案的耗时会随着 n 一起增长。然而,这里有个问题。如果在另一台计算机上运行这个函数,或用另一种编程语言来实现,很可能会得到不同的结果。如果计算机再旧些,sumOfN3 的执行时间甚至更长。
我们需要更好的方式来描述算法的执行时间。基准测试计算的是执行算法的实际时间。 这不是一个有用的指标,因为它依赖于特定的计算机、程序、时间、编译器与编程语言。我们希 望找到一个独立于程序或计算机的指标。这样的指标在评价算法方面会更有用,可以用来比较不同实现下的算法。
2. 大O记法

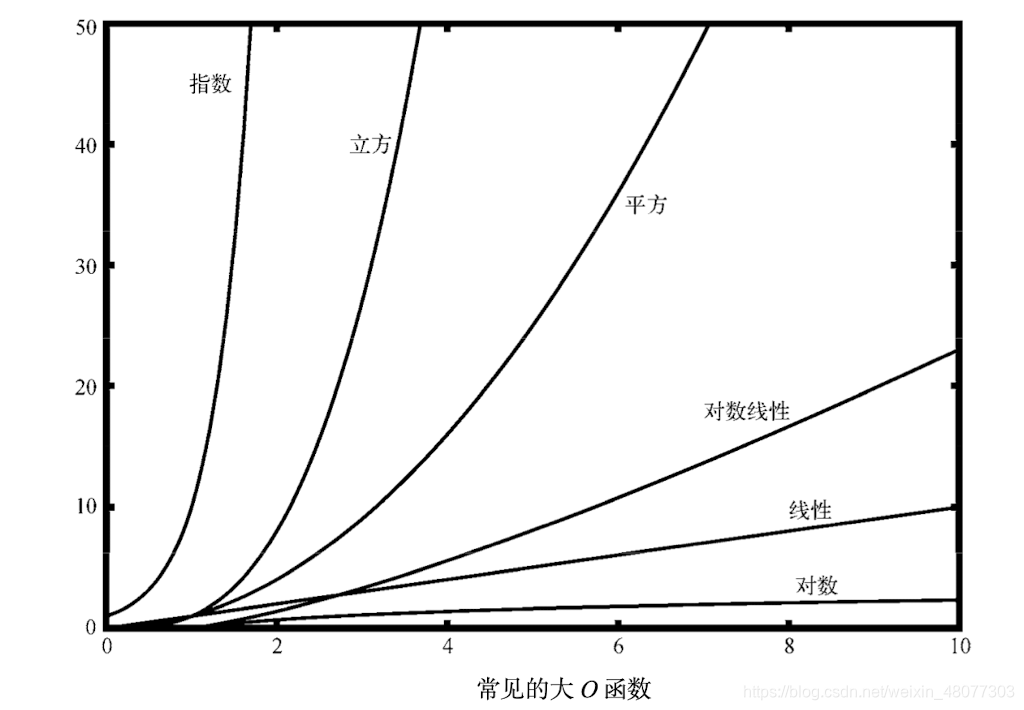
这里为了让大家知道一些函数的增长速度,我决定将一些函数的列举出来。

例:计算如下程序的步骤数,和数量级大O
a = 5
b = 6
c = 10
for i in range(n):
for j in range(n):
x = i * i
y = j * j
z = i * j
for k in range(n):
w = a * k + 45
v = b * b
d = 33
这段程序的赋值次数为:

大家可以自己算一下。
3. 不同算法的大O记法
这里我们采用不同的算法实现一个经典的异序词检测问,所谓异序词,就是组成单词的字母一样,只是顺序不同,例如heart和earth,python和typhon。为了简化问题,我们假设要检验的两个单词字符串的长度已经一样长。
3.1 清点法
该方法主要是清点第 1 个字符串的每个字符,看看它们是否都出现在第 2 个字符串中。如果是,那么两个字符串必然是异序词。清点是通过用 Python 中的特殊值 None 取代字符来实现的。但是,因为 Python 中的字符串是不可修改的,所以先要将第 2 个字符串转换成列表。在字符列表中检查第 1 个字符串中的每个字符,如果找到了,就替换掉。
def anagramSolution1(s1, s2):
alist = list(s2)
pos1=0
stillOK = True
while pos1 < len(s1) and stillOK:
pos2 = 0
found = False
while pos2 < len(alist) and not found:
if s1[pos1] == alist[pos2]:
found = True
else:
pos2 = pos2 + 1
if found:
alist[pos2] = None
else:
stillOK = False
pos1 = pos1 + 1
return stillOK
来分析这个算法。注意,对于 s1 中的 n 个字符,检查每一个时都要遍历 s2 中的 n 个字符。 要匹配 s1 中的一个字符,列表中的 n 个位置都要被访问一次。因此,访问次数就成了从 1 到 n 的整数之和。这可以用以下公式来表示。
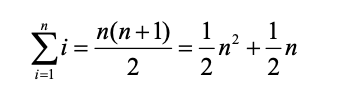
因此,该方法的时间复杂度是

3.2 排序法
尽管 s1 与 s2 是不同的字符串,但只要由相同的字符构成,它们就是异序词。基于这一点, 可以采用另一个方案。如果按照字母表顺序给字符排序,异序词得到的结果将是同一个字符串。
def anagramSolution2(s1, s2):
alist1 = list(s1)
alist2 = list(s2)
alist1.sort()
alist2.sort()
pos=0
matches = True
while pos < len(s1) and matches:
if alist1[pos] == alist2[pos]:
pos = pos + 1
else:
matches = False
return matches
乍看之下,你可能会认为这个算法的时间复杂度是O ( n ) O(n)O(n),因为在排序之后只需要遍历一次就可以比较 n 个字符。但是,调用两次 sort 方法不是没有代价。我们在后面会看到,排序的时 间复杂度基本上是O ( n 2 ) O(n2 )O(n2)或 O ( n l o g n ) O(nlogn)O(nlogn) ,所以排序操作起主导作用。也就是说,该算法和排序过程的数量级相同。
3.3 蛮力法
用蛮力解决问题的方法基本上就是穷尽所有的可能。就异序词检测问题而言,可以用 s1 中 的字符生成所有可能的字符串,看看 s2 是否在其中。但这个方法有个难处。用 s1 中的字符生 成所有可能的字符串时,第 1 个字符有 n 种可能,第 2 个字符有 n-1 种可能,第 3 个字符有 n-2 种可能,依此类推。字符串的总数是n ∗ ( n − 1 ) ∗ ( n − 2 ) ∗ . . . . . . ∗ 3 ∗ 2 ∗ 1 n*(n-1)*(n-2)*......*3*2*1n∗(n−1)∗(n−2)∗......∗3∗2∗1,即为n ! n!n!也许有些字符串会重复,但程序无法预见,所以肯定会生成n ! n!n!个字符串。
当 n 较大时, n! 增长得比2n还要快。实际上,如果 s1 有20个字符,那么字符串的个数就 是 20!= 2432902008176640000 。假设每秒处理一个,处理完整个列表要花 77146816596 年。 这可不是个好方案。
3.4 计数法
最后一个方案基于这样一个事实:两个异序词有同样数目的 a、同样数目的 b、同样数目的 c,等等。要判断两个字符串是否为异序词,先数一下每个字符出现的次数。因为字符可能有 26 种,所以使用 26 个计数器,对应每个字符。每遇到一个字符,就将对应的计数器加 1。最后, 如果两个计数器列表相同,那么两个字符串肯定是异序词。
def anagramSolution4(s1, s2):
c1=[0]*26
c2=[0]*26
for i in range(len(s1)):
pos = ord(s1[i]) - ord('a')
c1[pos] = c1[pos] + 1
for i in range(len(s2)):
pos = ord(s2[i]) - ord('a')
c2[pos] = c2[pos] + 1
j=0
stillOK = True
while j < 26 and stillOK:
if c1[j] == c2[j]:
j=j+1
else:
stillOK = False
return stillOK
这个方案也有循环。但不同于方案 1,这个方案的循环没有嵌套。前两个计数循环都是 n 阶 的。第 3 个循环比较两个列表,由于可能有 26 种字符,因此会循环 26 次。全部加起来,得到总步骤数 T (n) =2n - 26 ,即 O(n) 。我们找到了解决异序词检测问题的线性阶算法。
4. 列表和字典操作的复杂度
4.1 列表
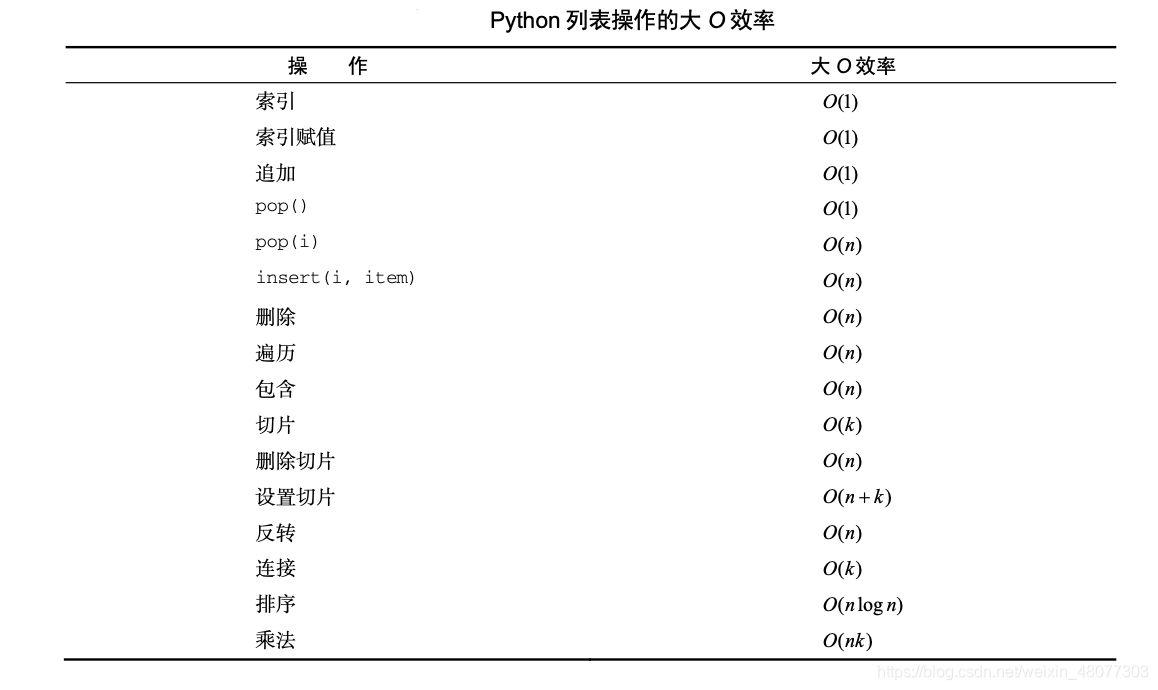
4.2 字典

到此这篇关于python数据结构算法分析的文章就介绍到这了,更多相关python 算法分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python数据结构:数据类型
目录 1.数据是什么? 2.数据类型 2.1内建原子数据类型 2.2 内建集合数据类型 3.集合数据类型的方法 3.1 列表 3.2 字符串 3.3 元祖 3.4 集合 3.5 字典 1.数据是什么? 在 Python 以及其他所有面向对象编程语言中,类都是对数据的构成(状态)以及数据 能做什么(行为)的描述.由于类的使用者只能看到数据项的状态和行为,因此类与抽象数据类 型是相似的.在面向对象编程范式中,数据项被称作对象.一个对象就是类的一个实例. 2.数据类型 2.1内建原子数据类型 Pyth
-
Python3实现从排序数组中删除重复项算法分析
本文实例讲述了Python3实现从排序数组中删除重复项算法.分享给大家供大家参考,具体如下: 题目:给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度. 不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成. 方案一:利用set()快速剔除重复元素. 效率最高 # -*- coding:utf-8 -*- #! python3 def removeDuclicates(nums): nums[:] = sorted
-
Python从入门到实战之数据结构篇
前言 我是栗子--专为小白准备<Python从入门到实战>内容. 这不是上一期刚讲完循环判断,还给大家出了很多新手的题目,边学边练习才有效果嘛. 时隔几天,大家都吼完了叭~实在没写完的慢慢复习,我更新文章也挺慢的!哈哈哈哈 今天想一想:要学数据结构啦~ 一.Python有那几种数据结构? Python 有四种数据结构,分别是:列表.字典.元组,集合.每种数据结构都有自己的特点,并且都有着独到的用处.为了避免过早地陷入细枝末节. 我们先从整体上来认识一下这四种数据结构:从最容易识别的特征上来说,
-
python数据结构输入输出及控制和异常
目录 1. 输入 input 2. 输出 print 2.1 普通输出 2.2 格式化输出 3. 控制语句 4. 异常处理 前言: python数据类型: python数据结构之数据类型. 今天我们主要来介绍一些内置函数,比如输入输出,控制,和异常的用法,尤其是输出和控制,用的太多了,写算法题,输出数据格式问题,对以后都会很有帮助. 1. 输入 input 程序经常需要与用户进行交互,以获得数据或者提供某种结果.Python 提供了一个函数,它使得我们可以要求用户输入数据并且返回一个字 符串的引
-
Python二叉树的定义及常用遍历算法分析
本文实例讲述了Python二叉树的定义及常用遍历算法.分享给大家供大家参考,具体如下: 说起二叉树的遍历,大学里讲的是递归算法,大多数人首先想到也是递归算法.但作为一个有理想有追求的程序员.也应该学学非递归算法实现二叉树遍历.二叉树的非递归算法需要用到辅助栈,算法着实巧妙,令人脑洞大开. 以下直入主题: 定义一颗二叉树,请看官自行想象其形状, class BinNode( ): def __init__( self, val ): self.lchild = None self.rchild =
-
python数据结构之面向对象
目录 1. 面向对象编程 2. 构建类 3. 继承 3.1 继承案例 python数据结构:数据类型. python数据结构输入输出及控制和异常. 今天我们来学习面向对象编程,面向对象这种编程方式非常重要,我们以后学习到的栈.队列.链表都是通过面向对象的方式实现的. 1. 面向对象编程 定义:面向对象是按照人们客观世界的系统思维方式,采用基于对象(实体)的概念建立模型 ,模拟客观世界分析,设计,实现软件的办法.通过面向对象的理念使计算机软件系统能与现实世界中的系统的一一对应. 听到这很多同学应
-
python数据结构算法分析
目录 1.算法分析的定义 2. 大O记法 3. 不同算法的大O记法 3.1 清点法 3.2 排序法 3.3 蛮力法 3.4 计数法 4. 列表和字典操作的复杂度 4.1 列表 4.2 字典 前文学习: python数据类型: python数据结构:数据类型. python的输入输出: python数据结构输入输出及控制和异常. python面向对象: python数据结构面向对象. 今天我们来学习的内容是面试题中都避免不小了的问题,就是算法分析了,什么是算法分析,算法分析是用来分析一个算法的好坏
-
python数据结构之递归方法讲解
目录 1.递归概念 2. 递归三原则 2.1 实现任意进制的数据转换 今天我们来学习python中最为重要的内容之递归,对以往内容感兴趣的同学可以查看下面: python数据类型: python数据结构:数据类型. python的输入输出: python数据结构之输入输出.控制和异常. python面向对象: python数据结构之面向对象. python算法分析: python数据结构算法分析. python数据结构之栈.队列和双端队列 递归是在进行重复性工作中经常考到的问题,非常值得学习.
-
python数据结构之栈、队列及双端队列
目录 1.线性数据结构的定义 2.栈 2.1 栈的定义 2.2 栈的数据类型 2.3 用python实现栈 2.4 栈的应用 3. 队列 3.1 队列的定义 3.2 队列抽象数据类型 3.3 用python实现队列 3.3 队列的应用 4. 双端队列 4.1 双端队列的定义 4.2 双端队列抽象数据类型 4.3 用python实现双端队列 4.3 双端队列的应用 5.链表 5.1 链表定义 5.2 用python实现链表 前文学习: python数据类型: python数据结构:数据类型. py
-
Python数据结构与算法之算法分析详解
目录 0. 学习目标 1. 算法的设计要求 1.1 算法评价的标准 1.2 算法选择的原则 2. 算法效率分析 2.1 大O表示法 2.2 常见算法复杂度 2.3 复杂度对比 3. 算法的存储空间需求分析 4. Python内置数据结构性能分析 4.1 列表性能分析 4.2 字典性能分析 0. 学习目标 我们已经知道算法是具有有限步骤的过程,其最终的目的是为了解决问题,而根据我们的经验,同一个问题的解决方法通常并非唯一.这就产生一个有趣的问题:如何对比用于解决同一问题的不同算法?为了以合理的方式
-
Python数据结构树与算法分析
目录 1.示例 2.术语及定义 3.实现 3.1 列表之列表 3.2节点与引用 4.二叉树的应用 4.1解析树 4.2树的遍历 5.利用二叉堆实现优先级队列 6.二叉搜索树 6.1搜索树的实现 7.平衡二叉搜索树(AVL树) 1.示例 树的一些属性: 层次性:树是按层级构建的,越笼统就越靠近顶部,越具体则越靠近底部. 一个节点的所有子节点都与另一个节点的所有子节点无关. 叶子节点都是独一无二的. 嵌套 2.术语及定义 节点:树的基础部分.节点的名字 → 键,附加信息 → 有效载荷. 边:两个节点
-
python数据结构之搜索讲解
目录 1. 普通搜索 2. 顺序搜索 1.1 无序下的顺序查找 1.2 有序下的顺序查找 2.二分查找 3.散列查找 3.1 几种散列函数 3.2 处理散列表冲突 3.3 散列表的实现(加1重复) 4.参考资料 往期学习: python数据类型: python数据结构:数据类型. python的输入输出: python数据结构之输入输出及控制和异常. python面向对象: python数据结构面向对象. python算法分析: python数据结构之算法分析. python栈.队列和双端队列:
-
python数据结构之图的实现方法
本文实例讲述了python数据结构之图的实现方法.分享给大家供大家参考.具体如下: 下面简要的介绍下: 比如有这么一张图: A -> B A -> C B -> C B -> D C -> D D -> C E -> F F -> C 可以用字典和列表来构建 graph = {'A': ['B', 'C'], 'B': ['C', 'D'], 'C': ['D'], 'D': ['C'], 'E': [
-
python数据结构之列表和元组的详解
python数据结构之 列表和元组 序列:序列是一种数据结构,它包含的元素都进行了编号(从0开始).典型的序列包括列表.字符串和元组.其中,列表是可变的(可以进行修改),而元组和字符串是不可变的(一旦创建了就是固定的).序列中包含6种内建的序列,包括列表.元组.字符串.Unicode字符串.buffer对象.xrange对象. 列表的声明: mylist = [] 2.列表的操作: (1) 序列的分片: 用法:mylist[startIndex:endIndex:step] exam: myli
-
Python数据结构与算法之图结构(Graph)实例分析
本文实例讲述了Python数据结构与算法之图结构(Graph).分享给大家供大家参考,具体如下: 图结构(Graph)--算法学中最强大的框架之一.树结构只是图的一种特殊情况. 如果我们可将自己的工作诠释成一个图问题的话,那么该问题至少已经接近解决方案了.而我们我们的问题实例可以用树结构(tree)来诠释,那么我们基本上已经拥有了一个真正有效的解决方案了. 邻接表及加权邻接字典 对于图结构的实现来说,最直观的方式之一就是使用邻接列表.基本上就是针对每个节点设置一个邻接列表.下面我们来实现一个最简
-
python数据结构之图深度优先和广度优先实例详解
本文实例讲述了python数据结构之图深度优先和广度优先用法.分享给大家供大家参考.具体如下: 首先有一个概念:回溯 回溯法(探索与回溯法)是一种选优搜索法,按选优条件向前搜索,以达到目标.但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为"回溯点". 深度优先算法: (1)访问初始顶点v并标记顶点v已访问. (2)查找顶点v的第一个邻接顶点w. (3)若顶点v的邻接顶点w存在,则继续执行:否则回