基于mysql实现group by取各分组最新一条数据
前言:
group by函数后取到的是分组中的第一条数据,但是我们有时候需要取出各分组的最新一条,该怎么实现呢?
本文提供两种实现方式。
一、准备数据
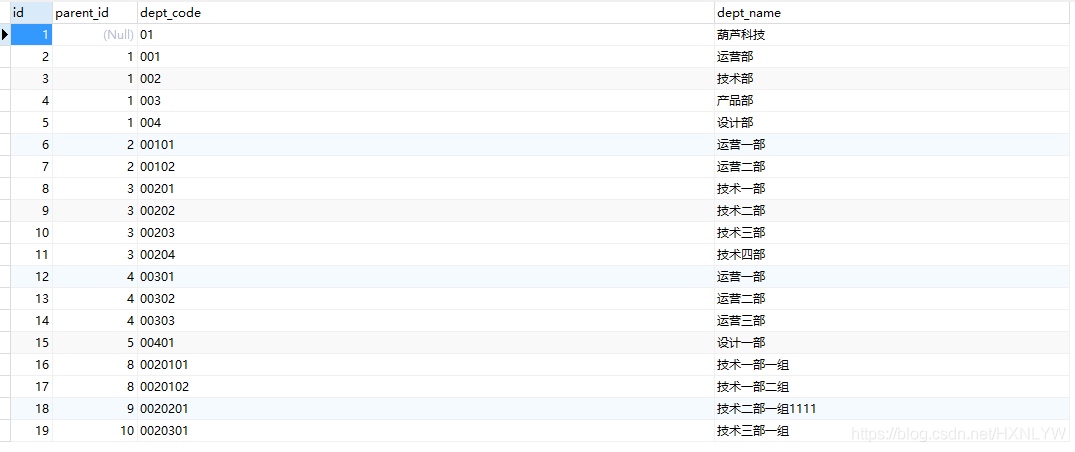
二、三种实现方式
1)先order by之后再分组:
SELECT * FROM (SELECT * from tb_dept ORDER BY id descLIMIT 10000) a GROUP BY parent_id;
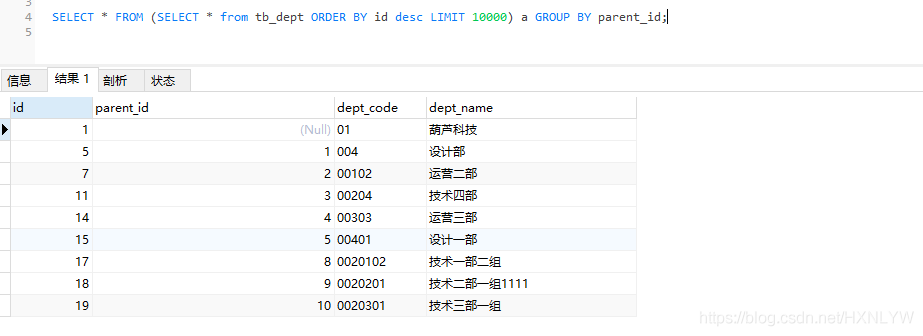
不加LIMIT可能会无效,由于mysql的版本问题。但是总觉得这种写法不太正经,因为如果数据量大于Limit 的值后,结果就不准确了。所以就有了第二种写法。
2)利用max() 函数:
SELECT * FROM tb_dept td,(SELECT max(id) id FROM tb_dept GROUP BY parent_id) md where td.id = md.id;
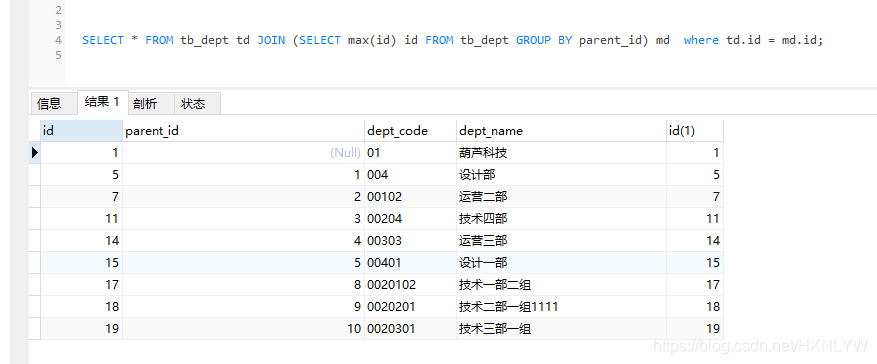
3)利用 where 字段名称 in (...) 函数:
SELECT * FROM tb_dept WHERE id IN (SELECT MAX(id) FROM tb_dept GROUP BY parent_id);
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Mysql利用group by分组排序
昨天有个需求对数据库的数据进行去重排名,同一用户去成绩最高,时间最短,参与活动最早的一条数据进行排序.我们可以利用MySQL中的group by的特性. MySQL的group by与Oracle有所不同,查询得字段可以不用写聚合函数,查询结果取得是每一组的第一行记录. 利用上面的特点,可以利用mysql实现一种独特的排序: 首先先按某个字段进行order by,然后把有顺序的表进行分组,这样每组的成员都是有顺序的,而mysql默认取得分组的第一行.从而得到每组的最值. select id, (
-

mysql分组取每组前几条记录(排名) 附group by与order by的研究
--按某一字段分组取最大(小)值所在行的数据 复制代码 代码如下: /* 数据如下: name val memo a 2 a2(a的第二个值) a 1 a1--a的第一个值 a 3 a3:a的第三个值 b 1 b1--b的第一个值 b 3 b3:b的第三个值 b 2 b2b2b2b2 b 4 b4b4 b 5 b5b5b5b5b5 */ --创建表并插入数据: 复制代码 代码如下: create table tb(name varchar(10),val int,memo varchar(20)
-
MySQL分组查询Group By实现原理详解
由于GROUP BY 实际上也同样会进行排序操作,而且与ORDER BY 相比,GROUP BY 主要只是多了排序之后的分组操作.当然,如果在分组的时候还使用了其他的一些聚合函数,那么还需要一些聚合函数的计算.所以,在GROUP BY 的实现过程中,与 ORDER BY 一样也可以利用到索引. 在MySQL 中,GROUP BY 的实现同样有多种(三种)方式,其中有两种方式会利用现有的索引信息来完成 GROUP BY,另外一种为完全无法使用索引的场景下使用.下面我们分别针对这三种实现方式做一个分
-
MySql Group By对多个字段进行分组的实现方法
在平时的开发任务中我们经常会用到MYSQL的GROUP BY分组, 用来获取数据表中以分组字段为依据的统计数据.比如有一个学生选课表,表结构如下: Table: Subject_Selection Subject Semester Attendee --------------------------------- ITB001 1 John ITB001 1 Bob ITB001 1 Mickey ITB001 2 Jenny ITB001 2 James MKB114 1 John MKB1
-
解决大于5.7版本mysql的分组报错Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated
原因: MySQL 5.7.5和up实现了对功能依赖的检测.如果启用了only_full_group_by SQL模式(在默认情况下是这样),那么MySQL就会拒绝选择列表.条件或顺序列表引用的查询,这些查询将引用组中未命名的非聚合列,而不是在功能上依赖于它们.(在5.7.5之前,MySQL没有检测到功能依赖项,only_full_group_by在默认情况下是不启用的.关于前5.7.5行为的描述,请参阅MySQL 5.6参考手册.) 执行以下个命令,可以查看 sql_mode 的内容: mys
-
mysql使用GROUP BY分组实现取前N条记录的方法
本文实例讲述了mysql使用GROUP BY分组实现取前N条记录的方法.分享给大家供大家参考,具体如下: MySQL中GROUP BY分组取前N条记录实现 mysql分组,取记录 GROUP BY之后如何取每组的前两位下面我来讲述mysql中GROUP BY分组取前N条记录实现方法. 这是测试表(也不知道怎么想的,当时表名直接敲了个aa,汗~~~~): 结果: 方法一: 复制代码 代码如下: SELECT a.id,a.SName,a.ClsNo,a.Score FROM aa a LEFT J
-
MySQL group by对单字分组序和多字段分组的方法讲解
我这里创建了一个 goods 表,先看下里面的数据: mysql> select * from goods; +----+------+------+------------+-------------+------------+ | id | s_id | b_id | goods_name | goods_price | goods_desc | +----+------+------+------------+-------------+------------+ | 1 | 1 | 5
-
基于mysql实现group by取各分组最新一条数据
前言: group by函数后取到的是分组中的第一条数据,但是我们有时候需要取出各分组的最新一条,该怎么实现呢? 本文提供两种实现方式. 一.准备数据 http://note.youdao.com/noteshare?id=dba748092a619be0a8f160ccf6e25a5f&sub=FD4C1C7823CA440DB360FEA3B4A905CD 二.三种实现方式 1)先order by之后再分组: SELECT * FROM (SELECT * from tb_dept ORDE
-
MySQL 多表关联一对多查询实现取最新一条数据的方法示例
本文实例讲述了MySQL 多表关联一对多查询实现取最新一条数据的方法.分享给大家供大家参考,具体如下: MySQL 多表关联一对多查询取最新的一条数据 遇到的问题 多表关联一对多查询取最新的一条数据,数据出现重复 由于历史原因,表结构设计不合理:产品告诉我说需要导出客户信息数据,需要导出客户的 所属行业,纳税性质 数据:但是这两个字段却在订单表里面,每次客户下单都会要求客户填写:由此可知,客户数据和订单数据是一对多的关系:那这样的话,问题就来了,我到底以订单中的哪一条数据为准呢?经过协商后一致同
-
pyodps中的apply用法及groupby取分组排序第一条数据
目录 1.apply用法 2.取分组排序后的第一条数据 1.apply用法 apply在pandas里非常好用的,那在pyodps里如何去使用,还是有一些区别的,在pyodps中要对一行数据使用自定义函数,可以使用 apply 方法,axis 参数必须为 1,表示在行上操作. apply 的自定义函数接收一个参数,为上一步 Collection 的一行数据,用户可以通过属性.或者偏移取得一个字段的数据. iris.apply(lambda row: row.sepallength + row.s
-
mysql通过group by分组取最大时间对应数据的两种有效方法
1.项目记录表project_record的结构和数据如下: 以下为项目记录表project_record的所有数据.project_id为项目Id,on_project_time为上项目时间.(每一条数据代表着上某个项目(project_id)的时间(on_project_time)记录) 2.我们的需求是:取出每个项目中最大上项目时间对应的那条数据.(即根据project_id分组,取出每组中最大的on_project_time对应的数据.)上方红框是我们要查出的数据. 3.错误代码: SE
-
Mysql数据库group by原理详解
目录 引言 1. 使用group by的简单例子 2. group by 原理分析 2.1 explain 分析 2.2 group by 的简单执行流程 3. where 和 having的区别 3.1 group by + where 的执行流程 3.2 group by + having 的执行 3.3 同时有where.group by .having的执行顺序 3.4 where + having 区别总结 4. 使用 group by 注意的问题 4.1 group by一定要配合聚
-
Oracle结合Mybatis实现取表TOP 10条数据
之前一直使用mysql和informix数据库,查表中前10条数据十分简单: 最原始版本: select top * from student 当然,我们还可以写的复杂一点,比如外加一些查询条件? 比如查询前10条成绩大于80分的学生信息 添加了where查询条件的版本: select top * from table where score > 80 但是!!oracle中没有top啊!!!!那么该如何实现呢? 嗯,可以用rownum! oracle中原始版本 select * from st
-
Mysql实现定时清空一张表的旧数据并保留几条数据(推荐)
要达到如下目的: Mysql数据库会每隔一段时间(可以是2小时,也可以是一天,这个可以自定义),定时对一张库中的表做一个判断,如果这张表的数据超过了20条(这个数据也是自定义的,也可以是200条),就保留最新的10条数据(这个数据同样可以自定义,但要小于等于之前的超过数据条数). 简单说一下解决的思路(从后往前推导): 1.开启一个定时器,这个定时器做了两件事: ⑴设置了时间间隔 ⑵调用一个存储过程 2.写一个存储过程,此存储过程要做两件事: ⑴判断表的数据条数是否超过20,如果超过20才做下面