pandas读取csv格式数据时header参数设置方法
目录
- 写在前面
- 参考文档
- read_csv的header参数
- header参数测试
- 思考
写在前面
使用pandas中read_csv读取csv数据时,对于有表头的数据,将header设置为空(None),会报错:pandas_libs\parsers.pyx in pandas._libs.parsers.raise_parser_error() ParserError: Error tokenizing data. C error: Expected 4 fields in line 2, saw 5 。
查看pandas官方文档发现,read_csv读取时会自动识别表头,数据有表头时不能设置header为空(默认读取第一行,即header=0);数据无表头时,若不设置header,第一行数据会被视为表头,应传入names参数设置表头名称或设置header=None。
参考文档
这是pandas的read_csv的官方文档: python - pandas.read_csv
read_csv的header参数
使用pandas的read_csv读取数据时,header参数表头名称设置(即各列数据对应名称),下面是文档中对header参数的说明:

其中指出,表头可根据数据格式推断各列名称:默认情况下,
- 若未传入
names参数,则根据输入文件的第一行推断是否有表头; - 若传入
names参数,则names传入的参数作为表头(原数据有表头则会替换原有表头)。
下面是对read_csv的header参数测试
header参数测试
测试数据 两个csv(用逗号隔开)格式的文件,这里是用Excel打开,分别是带有表头和不带表头的数据:
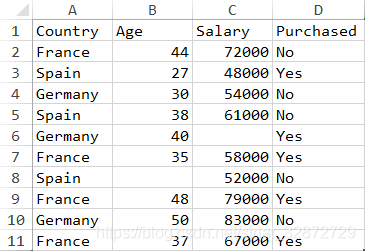
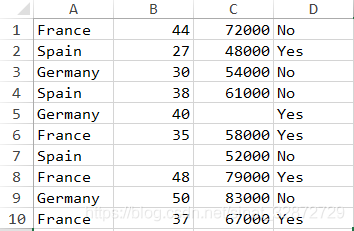
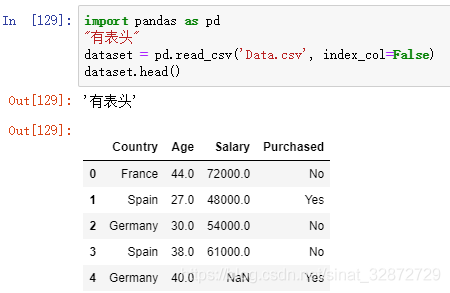
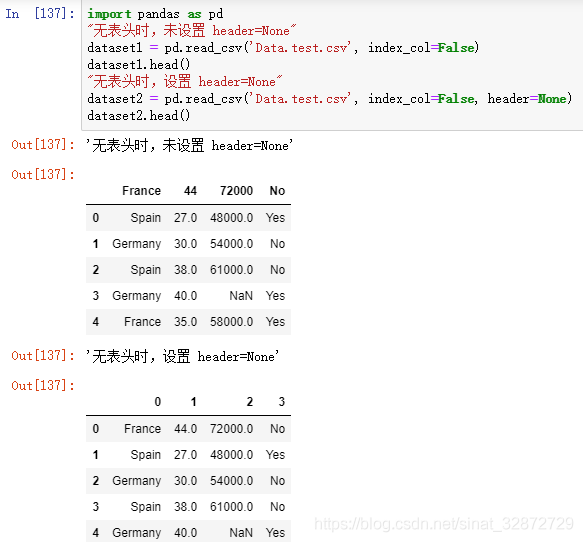
默认header 下面是header默认情况下,对有表头的数据识别第一行作为header(即header=0)[ 数据没有给出index名称,这里设置 index_col=False,不设置默认第一列为index(而表头仍是4列,最后一列数据为NaN), index_col参数与 header类似可自动识别。
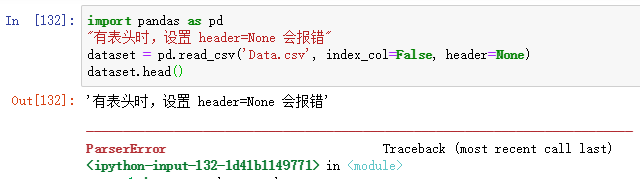
设置header=None 对有表头的数据设置 header=None则会报错:

对无表头的数据,则需设置 header=None,否则第一行数据被作为表头:
思考
pandas是如何识别或区分数据和表头名称的 ?
- 对于
index_col来说,若数据都是相同类型,比如数值型,则表示无index,输出默认index为0,1,2,…;若数据第一列为字符,其他列为数值,则会将第一列视为index;若设置index_col=False, 则表示无index(默认将0, 1, 2,…作为数据的index) - 对
header,当第一行为字符,则第一行默认为表头;当第一行与其他数据类型相同时,也会把第一行当作表头,所以无表头时应设置header=None
header传入list参数(元素代表取对应行号)怎么用?
read_csv的参数skip_blank_lines=True会忽略注释行和空行,其中注释行是用什么符号注释的?(试了一下,行首用’#'注释的不对)
到此这篇关于pandas读取csv格式数据时header参数设置方法的文章就介绍到这了,更多相关pandas header参数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pandas参数设置的实用小技巧
前言 在日常使用pandas的过程中,由于我们所分析的数据表规模.格式上的差异,使得同样的函数或方法作用在不同数据上的效果存在差异. 而pandas有着自己的一套参数设置系统,可以帮助我们在遇到不同的数据时灵活调节从而达到最好的效果,本文就将介绍pandas中常用的参数设置方面的知识. 图1 1 设置DataFrame最大显示行数 pandas设置参数中的display.max_rows用于控制打印出的数据框的最大显示行数,我们使用pd.set_option()来有针对的设置参数,如下面的例子:
-
Pandas的read_csv函数参数分析详解
函数原型 复制代码 代码如下: pd.read_csv(filepath_or_buffer, sep=',', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_va
-
pandas读取csv文件,分隔符参数sep的实例
在python中读取csv文件时,一般操作如下: import pandas as pd pd.read_csv(filename) 该读文件方式,默认是以逗号","作为分割符,若是以其它分隔符,比如制表符"/t",则需要显示的指定分隔符.如下 pd_read_csv(filename,'/t') 但如果遇见某个字段包含了"/t"的字符,比如网址"www.xxx.xx/t-",则也会把字段中的"/t"理解为
-
pandas.read_csv参数详解(小结)
pandas.read_csv参数整理 读取CSV(逗号分割)文件到DataFrame 也支持文件的部分导入和选择迭代 更多帮助参见:http://pandas.pydata.org/pandas-docs/stable/io.html 参数: filepath_or_buffer : str,pathlib.str, pathlib.Path, py._path.local.LocalPath or any object with a read() method (such as a file
-
对python pandas中 inplace 参数的理解
pandas 中 inplace 参数在很多函数中都会有,它的作用是:是否在原对象基础上进行修改 inplace = True:不创建新的对象,直接对原始对象进行修改: inplace = False:对数据进行修改,创建并返回新的对象承载其修改结果. 默认是False,即创建新的对象进行修改,原对象不变,和深复制和浅复制有些类似. 例: inplace=True情况: import pandas as pd import numpy as np df=pd.DataFrame(np.rand
-
快速解释如何使用pandas的inplace参数的使用
介绍 在操作数据帧时,初学者有时甚至是更高级的数据科学家会对如何在pandas中使用inplace参数感到困惑. 更有趣的是,我看到的解释这个概念的文章或教程并不多.它似乎被假定为知识或自我解释的概念.不幸的是,这对每个人来说都不是那么简单,因此本文试图解释什么是inplace参数以及如何正确使用它. 让我们来看看一些使用inplace的函数的例子: fillna() dropna() sort_values() reset_index() sort_index() rename() 我已经创建
-

pandas读取csv格式数据时header参数设置方法
目录 写在前面 参考文档 read_csv的header参数 header参数测试 思考 写在前面 使用pandas中read_csv读取csv数据时,对于有表头的数据,将header设置为空(None),会报错:pandas_libs\parsers.pyx in pandas._libs.parsers.raise_parser_error() ParserError: Error tokenizing data. C error: Expected 4 fields in line 2,
-
pandas读取csv文件提示不存在的解决方法及原因分析
一般情况是数据文件没有在当前路径,那么它是无法读取数据的.另外,如果路径名包含中文它也是无法读取的. (1)可以选择: import os os.getcwd() 获得当前的工作路径,把你的数据文件放在此路径上就可以了,就可以直接使用pd.read_csv("./_.csv") (2)可以选择: 使用os.chdir(path),path是你的那个数据文件路径 (3)可以选择: 不更改路径,直接调用df=pd.read_csv(U"文件存储的盘(如C盘) :/文件夹/文件名.
-
利用Pandas读取表格行数据判断是否相同的方法
描述: 下午快下班的时候公司供应链部门的同事跑过来问我能不能以程序的方法帮他解决一些excel表格每周都需要手工重复做的事情,Excel 是数据处理最常用的办公工具对于市场.运营都应该很熟练.哈哈,然而程序员是不怎么会用excel的.下面给大家介绍一下pandas, Pandas是一个强大的分析结构化数据的工具集:它的使用基础是Numpy(提供高性能的矩阵运算):用于数据挖掘和数据分析,同时也提供数据清洗功能. 具体需求: 找出相同的数字,把与数字对应的英文字母合并在一起. 期望最终生成值:
-
pandas读取CSV文件时查看修改各列的数据类型格式
下面给大家介绍下pandas读取CSV文件时查看修改各列的数据类型格式,具体内容如下所述: 我们在调bug的时候会经常查看.修改pandas列数据的数据类型,今天就总结一下: 1.查看: Numpy和Pandas的查看方式略有不同,一个是dtype,一个是dtypes print(Array.dtype) #输出int64 print(df.dtypes) #输出Df下所有列的数据格式 a:int64,b:int64 2.修改 import pandas as pd import numpy a
-
python中pandas读取csv文件时如何省去csv.reader()操作指定列步骤
优点: 方便,有专门支持读取csv文件的pd.read_csv()函数. 将csv转换成二维列表形式 支持通过列名查找特定列. 相比csv库,事半功倍 1.读取csv文件 import pandas as pd file="c:\data\test.csv" csvPD=pd.read_csv(file) df = pd.read_csv('data.csv', encoding='gbk') #指定编码 read_csv()方法参数介绍 filepath_or_buf
-
Python如何利用pandas读取csv数据并绘图
目录 如何利用pandas读取csv数据并绘图 绘制图像 展示结果 pandas画pearson相关系数热力图 pearson相关系数计算函数 如何利用pandas读取csv数据并绘图 导包,常用的numpy和pandas,绘图模块matplotlib, import matplotlib.pyplot as plt import pandas as pd import numpy as np fig = plt.figure() ax = fig.add_subplot(111) 读取csv文
-
Python Pandas读取csv/tsv文件(read_csv,read_table)的区别
目录 前言 read_csv()和read_table()之间的区别 读取没有标题的CSV 读取有标题的CSV 读取有index的CSV 指定(选择)要读取的列 跳过(排除)行的读取 skiprows skipfooter nrows 通过指定类型dtype进行读取 NaN缺失值的处理 读取使用zip等压缩的文件 tsv的读取 总结 前言 要将csv和tsv文件读取为pandas.DataFrame格式,可以使用Pandas的函数read_csv()或read_table(). 在此 read_
-
使用Python pandas读取CSV文件应该注意什么?
示例文件 将以下内容保存为文件 people.csv. id,姓名,性别,出生日期,出生地,职业,爱好 1,张小三,m,1992-10-03,北京,工程师,足球 2,李云义,m,1995-02-12,上海,程序员,读书 下棋 3,周娟,女,1998-03-25,合肥,护士,音乐,跑步 4,赵盈盈,Female,2001-6-32,,学生,画画 5,郑强强,男,1991-03-05,南京(nanjing),律师,历史-政治 如果一切正常的话,在Jupyter Notebook 中应该显示以下内容:
-
Python pandas读取CSV文件的注意事项(适合新手)
目录 前言 示例文件 文件编码 空值 日期错误 函数映射 方法1:直接使用labmda表达式 方法二:使用自定义函数 方法三:使用数值字典映射 总结 前言 本文是给使用pandas的新手而写,主要列出一些常见的问题,根据笔者所踩过的坑,进行归纳总结,希望对读者有所帮助. 示例文件 将以下内容保存为文件 people.csv. id,姓名,性别,出生日期,出生地,职业,爱好 1,张小三,m,1992-10-03,北京,工程师,足球 2,李云义,m,1995-02-12,上海,程序员,读书 下棋 3