Python反爬机制-验证码功能的具体实现过程
目录
- 识别验证码
- 1.字符验证码
- 1.1OCR环境
- 1.2下载验证码图片
- 1.3识别验证码
- 2.第三方验证码识别
- 3.滑动拼图验证码
识别验证码
OCR(Optical Character Recognition)即光学字符识别技术,专门用于对图片文字进行识别,并获取文本。字符验证码的特点就是验证码中包含数字、字母或者掺杂着斑点与混淆曲线的图片验证码。识别此类验证码,首先需要找到验证码验证码图片在网页HTML代码中的位置,然后将验证码下载,最后再通过OCR技术进行验证码的识别工作。
1. 字符验证码
1.1 OCR环境
Tesseract-OCR是一个免费、开源的OCR引擎,通过该引擎可以识别图片中的验证码,搭建OCR的具体步骤如下:
(1)这里以macOS操作系统为例,使用brew install安装tesseract,命令如下:
liuxiaowei@MacBookAir ~ % brew install --with-training-tools tesseract # 同时安装附加组件
安装完毕后用如下命令测试,示例代码如下:
liuxiaowei@MacBookAir ~ % tesseract -v tesseract 5.0.1 leptonica-1.82.0 libgif 5.2.1 : libjpeg 9d : libpng 1.6.37 : libtiff 4.3.0 : zlib 1.2.11 : libwebp 1.2.1 : libopenjp2 2.4.0 Found AVX2 Found AVX Found FMA Found SSE4.1 Found libarchive 3.5.2 zlib/1.2.11 liblzma/5.2.5 bz2lib/1.0.8 liblz4/1.9.3 libzstd/1.5.0 Found libcurl/7.77.0 SecureTransport (LibreSSL/2.8.3) zlib/1.2.11 nghttp2/1.42.0
(2)安装tesseract模块,安装命令如下:
pip install tesseract

说 明
如果使用的的是Anaconda并在安装tesseract模块时出现错误,可以使用如下命令:
conda install -c simonflueckiger tesseract
1.2 下载验证码图片
以下面地址对应的网页为例,下载网页中的验证码图片,具体步骤如下:
测试页面地址:http://sck.rjkflm.com:666/spider/word/
(1)使用浏览器打开测试网页的地址,将显示如下图片所示的字符验证码:

(2)打开浏览器开发者工具,然后在HTML代码中获取验证码图片所在的位置,如下图所示:

(3) 对目标网页发送网络请求,并在返回的HTML代码中获取图片的下载地址,然后下载验证码图片。代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/15/22 7:47 PM
# 文件 :获取HTML代码中地址下载验证码图片.py
# IDE :PyCharm
# 导入网络请求模块
import requests
# 导入urllib.request模块
import urllib.request
# 导入随机请求头
from fake_useragent import UserAgent
# 导入ssl,否则ssl验证错误
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# 导入解析HTML的模块
from bs4 import BeautifulSoup
# 创建随机请求头
header = {'User-Agent':UserAgent().random}
# 网页请求地址
url = 'http://sck.rjkflm.com:666/spider/word/'
# 发送网络请求
resp = requests.get(url, header)
resp.encoding = 'utf-8'
# 解析HTML
html = BeautifulSoup(resp.text, 'html.parser')
src = html.find('img').get('src')
# 组合验证码图片请求地址
img_url = url+src
# 下载并设置图片名称
urllib.request.urlretrieve(img_url, 'code.png')
程序运行后项目文件夹中自动生成验证码图片,结果如下图:

1.3 识别验证码
验证码下载完成以后, 如果没有安装pillow模块,需要通过“pip install pillow“命令安装一下,如果tesserocr模块没安装也要通过"pip install tesserocr"先安装,然后导入tesserocr与Image模块,再通过Image.open()方法打开验证码图片,接着通过tesserocr.image_to_text()函数识别图片中的验证码信息即可。示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/16/22 7:21 AM
# 文件 :识别图中验证码.py
# IDE :PyCharm
# 导入tesserocr模块
import tesserocr
# 导入图像处理模块
from PIL import Image
# 打开验证码图片
img = Image.open('code.png')
# 将图片中的验证码转换为文本
code = tesserocr.image_to_text(img)
print('验证码为: ', code)
程序运行结果如下:
验证码为: uuuc
Process finished with exit code 0
OCR的识别技术虽然很强大,但是并不是所有的验证码都可以这么轻松地识别出来,如下图所示的验证码中就会掺杂很多干扰线条,那么在识别这样的验证码信息时,就需要对验证码图片进行相应的处理并识别。

如果直接通过OCR识别,识别结果将会受到干扰线的影响,下面通过OCR直接识别测试一下效果。示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/16/22 8:23 AM
# 文件 :识别带干扰线的验证码.py
# IDE :PyCharm
import tesserocr # 导入tesserocr模块
from PIL import Image # 导入图像处理模块
img =Image.open('code2.jpg') # 打开验证码图片
img = img.convert('L') # 将彩色图片转换为灰度图片
img.show() # 显示灰度图片
code = tesserocr.image_to_text(img) # 将图片中的验证码转换为文本
print('验证码为:',code)
程序运行结果如下:
验证码为: YSGN. # 多了一个.
Process finished with exit code 0
通过以上测试发现,直接通过OCR技术识别后的验证码中多了一个‘.’,遇到此类情况手写可以将彩色的验证码图片转为灰度图片在测试一下。示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/16/22 8:29 AM
# 文件 :将彩色验证码图片转为灰度图片测试.py
# IDE :PyCharm
import tesserocr # 导入tesserocr模块
from PIL import Image # 导入图像处理模块
img =Image.open('code2.jpg') # 打开验证码图片
img = img.convert('L') # 将彩色图片转换为灰度图片
img.show() # 显示灰度图片
code = tesserocr.image_to_text(img) # 将图片中的验证码转换为文本
print('验证码为:',code)
程序运行结果如下:
验证码为: YSGN. # 依然多一个‘.‘
Process finished with exit code 0

接下来需要将转为灰度的验证码图片进行二值化处理,将验证码二值化处理后再次通过OCR进行识别。示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/16/22 8:38 AM
# 文件 :将验证码图片二值化处理.py
# IDE :PyCharm
import tesserocr # 导入tesserocr模块
from PIL import Image # 导入图像处理模块
img =Image.open('code2.jpg') # 打开验证码图片
img = img.convert('L') # 将彩色图片转换为灰度图片
t = 155 # 设置阀值
table = [] # 二值化数据的列表
for i in range(256): # 循环遍历
if i <t:
table.append(0)
else:
table.append(1)
img = img.point(table,'1') # 将图片进行二值化处理
img.show() # 显示处理后图片
code = tesserocr.image_to_text(img) # 将图片中的验证码转换为文本
print('验证码为:',code) # 打印验证码
程序运行后将自动显示二值化处理后的验证码图片
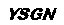
程序运行结果如下:
验证码为: YSGN
Process finished with exit code 0
说 明
在识别以上具有干扰线的验证码图片时,我们可以做一些灰度和二值化处理,这样可以提高图片的验证码的识别度,如果二值化处理后还是无法识别到精确性,可以适当的上下调节二值化操作的阙值。
2. 第三方验证码识别
针对OCR识别率和准确度不高的缺点,使用第三方验证码识别平台是一个不错的选择,不仅可以解决验证码识别率低低问题,还可以提高验证码识别的准确度。第三方平台识别验证码非常简单,平台提供了完善的API接口,根据平台对应的开发文档即可完成快速开发的需求,但每次验证码成功识别后平台会收取少量费用。
验证码识别平台一般分为两种,分别是打码平台和AI开发者平台。打码平台主要是由在线人员进行验证码的识别工作,然后在较短的时间内返回结果。AI开发者平台主要是由人工智能来进行识别。例如,百度AI。
下面以打码平台为例,演示验证码识别的具体过程。
(1)在浏览器中打开打码平台网页(http://www.chaojiying.com/),并且单击首页的“用户注册”按钮,如图所示:

(2) 然后在用户中心页面中填写注册账号的基本信息。如下图:

说 明
账号注册完成以后可以联系平台的客服人员,申请免费测试的题分。
(3) 账号注册完成以后,在网页的顶部导航栏中选择“开发文档”,然后在常用开发语言示例下载中选择“Python“语言,如下图所示:
(4) 在Python语音Demo下载页面中,查看注意事项,然后单击“点击这里下载”超链接即可下载示例代码,如图所示:

(5)平台提供的示例代码中,已经将所有需要用到的功能代码进行了封装处理,封装的代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/16/22 10:01 AM
# 文件 :平台提供识别封装代码.py
# IDE :PyCharm
import requests # 网络请求模块
from hashlib import md5 # 加密
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username # 自己注册的账号
password = password.encode('utf8') # 自己注册的密码
self.password = md5(password).hexdigest()
self.soft_id = soft_id # 软件id
self.base_params = { # 组合表单数据
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = { # 请求头信息
'Connection': 'Keep-Alive',
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
params = {
'codetype': codetype,
params.update(self.base_params) # 更新表单参数
files = {'userfile': ('code2.jpg', im)} # 上传验证码图片
# 发送网络请求
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json() # 返回响应数据
def ReportError(self, im_id):
im_id:报错题目的图片ID
'id': im_id,
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
#用户中心>>软件ID 生成一个替换 96001
chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '928939')
im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
#1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
print(chaojiying.PostPic(im, 1902))
(6)使用平台示例代码中所提供的验证码图片,运行以上示例代码,运行结果如下:
{'err_no': 0, 'err_str': 'OK', 'pic_id': '9168810337948200001', 'pic_str': '7261', 'md5': '345c80a5dba345c219cc8893f19b496c'}
Process finished with exit code 0
说 明
程序运行结果中pic_str对应的值为返回的验证码识别信息。
在发送识别验证码的网络请求时,代码中的“1902”表示验证码的类型,该平台所支持的常用验证码类型如下表:
常用验证码类型
验证码类型验证码描述1902常见4-6位英文数字1101-10201-20位英文数字2001-20071-7位纯汉字3004-30121-12位纯英文4004-41111-11位纯数字5000不定长汉字英文数字51088位英文数字(包含字符)5201拼音首字母,计算题,成语混合5211集装箱号4位字母7位数字6001计算题6003复杂计算题
说 明
表中之列出了比较常用的验证码识别类型,详细内容可查验证码平台官网
3. 滑动拼图验证码
滑动拼图验证码是在滑动验证码的基础上增加了滑动距离的校验,用户需要将图形滑块滑动至主图空缺滑块的位置,才能通过校验。下面通过案例测试,实现滑动拼图验证码的自动校验。测试网页地址:http://sck.rjkflm.com:666/spider/jgsaw/
(1) 使用浏览器打开测试页的地址,将显示如图所示的滑动拼图验证码。

(2) 打开浏览器开发者工具,单击按钮滑块,然后在HTML代码中依次获取“按钮滑块”“图形滑块”以及“空缺滑块”所对应的HTML代码标签所在的位置。
| 验证码类型 | 验证码描述 |
|---|---|
| 1902 | 常见4-6位英文数字 |
| 1101-1020 | 1-20位英文数字 |
| 2001-2007 | 1-7位纯汉字 |
| 3004-3012 | 1-12位纯英文 |
| 4004-4111 | 1-11位纯数字 |
| 5000 | 不定长汉字英文数字 |
| 5108 | 8位英文数字(包含字符) |
| 5201 | 拼音首字母,计算题,成语混合 |
| 5211 | 集装箱号4位字母7位数字 |
| 6001 | 计算题 |
| 6003 | 复杂计算题 |

(3)验证成功后的按钮滑块”“图形滑块”以及“空缺滑块”位置变化如下所示
# 图形滑块 <div class="verify" style="display: block; top: 30.2081px; background-position: -173.893px -30.2081px; left: 10px;"></div> # 按钮滑块 <span class="swiper" style="left: 0px;"></span>
(4) 通过按钮滑块的left值可以确认需要滑动的距离,接下来只需要使用selenium框架模拟滑动的工作即可。实现代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/16/22 5:19 PM
# 文件 :使用selenium框架模拟滑动图块.py
# IDE :PyCharm
from selenium import webdriver # 导入webdriver
import re # 导入正则模块
driver = webdriver.Chrome() # 谷歌浏览器
driver.get('http://sck.rjkflm.com:666/spider/jigsaw/') # 启动网页
swiper = driver.find_element_by_xpath(
'/html/body/div/div[2]/div[2]/span[1]') # 获取按钮滑块
action = webdriver.ActionChains(driver) # 创建动作
action.click_and_hold(swiper).perform() # 单击并保证不松开
# 滑动0距离,不松手,不执行该动作无法获取图形滑块left值
action.move_by_offset(0,0).perform()
# 获取图形滑块样式
verify_style = driver.find_element_by_xpath(
'/html/body/div/div[2]/div[1]/div[1]').get_attribute('style')
# 获取空缺滑块样式
verified_style = driver.find_element_by_xpath(
'/html/body/div/div[2]/div[1]/div[2]').get_attribute('style')
# 获取空缺滑块left值
verified_left =float(re.findall('left: (.*?)px;',verified_style)[0])
# 获取图形滑块left值
verify_left =float(re.findall('left: (.*?)px;',verify_style)[0])
action.move_by_offset(verified_left-verify_left,0) # 滑动指定距离
action.release().perform() # 松开鼠标
程序运行如下图显示:

总 结

到此这篇关于Python反爬机制-验证码的文章就介绍到这了,更多相关Python验证码反爬内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python+selenium破解拼图验证码的脚本
目录 实现思路 核心代码 实现思路 很多网站都有拼图验证码 1.首先要了解拼图验证码的生成原理 2.制定破解计划,考虑其可能性和成功率. 3.编写脚本 很多网站的拼图验证码都是直接借助第三方插件,也就是一类一种解法. 笔者遇到的这种拼图验证码实际上是多个小碎片经过重新组合成的一张整体,首先要在网站上抓取这种小碎片图片并下载到本地 我们先捋一捋大体思路: 获取所有碎片图片----找出他们的排列顺序逻辑-----找出他们中含有颜色深的真正位置的那个小碎块的序号-----根据每块碎片的宽度和上下和这个
-
利用Python生成随机验证码详解
目录 1.先搞环境 2.开始码代码 3. 加干扰 4. 加入更多的干扰 5. 验证码 + 随机字符 6. 验证码保存本地(选) 最近感觉被大数据定义成机器人了,随便看个网页都跳验证码. 怎么用python绕验证码是个令人头秃的事情, 我投降!那么今天手把手教大家如何写验证码,去为难别人,让他们头秃. 说错了,其实就是教大家如何通过python代码去生成验证码~~ 1.先搞环境 1.我们需要你电脑有python3.4以上的版本 2.pip安装PIL包 pip install pillow 3.默念
-
Python实现新版正方系统滑动验证码识别
目录 步骤一:点击数据分析 步骤二:滑动验证码图像分析,计算滑动距离x值 步骤三:生成提交参数 Python实现新版正方系统滑动验证码识别算法和方案 步骤一:点击数据分析 点击滑动按钮,将发送一个请求到 /zfcaptchaLogin 请求内容 "type": "verify" "rtk": "6cfab177-afb2-434e-bacf-06840c12e7af" "time": "16246
-
python+selenium行为链登录12306(滑动验证码滑块)
使用python网络爬虫登录12306,网站界面如下.因为网站的反爬是不断升级的,以下代码虽然当前可用,但早晚必将会不再能满足登录需求.但是知识的价值,是不容置疑的. from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains import time from selenium.webdriver import ChromeOptions # 去除浏览器识别 opt
-
基于Python实现原生的登录验证码详情
目录 1.概述 2.验证码实现的演进过程 2.1 路由及页面 2.2 视图函数中验证码的推导 2.2.1 图片发送到前端 2.2.2 引入动态图片 2.2.3 内存管理模块图片 2.2.4 完整图片验证码 2.3 登录验证中使用验证码 2.4 前端页面点击自动刷新 3.效果展示 4.小结 1.概述 在前面的文章中,我有分享了vue+drf+第三方滑动验证码接入的实现(文中也留了分享图片验证码功能的实现),即本文将要分享的是基于 python 实现原生的登录验证码 通常的验证码,人眼看上去更像是一
-
python通过pillow识别动态验证码的示例代码
目录 环境配置 安装 pillow(PIL)库 识别过程 生活中,我们在登录微博,邮箱的时候,常常会碰到验证码.在工作时,如果想要爬取一些数据,也会碰到验证码的阻碍.本次试验将带领大家认识验证码的一些特性,并利用 Python 中的 pillow 库完成对验证码的破解. 环境配置 Python 2.7 Pillow 模块 有个问题就是python2.7目前只能让使用到2020年,现在再利用2.7下载好多东西都会报错,也该是时候更新到python3.7了,本文还是依赖于2.7的环境. 识别验证码
-
Python反爬机制-验证码功能的具体实现过程
目录 识别验证码 1.字符验证码 1.1OCR环境 1.2下载验证码图片 1.3识别验证码 2.第三方验证码识别 3.滑动拼图验证码 识别验证码 OCR(Optical Character Recognition)即光学字符识别技术,专门用于对图片文字进行识别,并获取文本.字符验证码的特点就是验证码中包含数字.字母或者掺杂着斑点与混淆曲线的图片验证码.识别此类验证码,首先需要找到验证码验证码图片在网页HTML代码中的位置,然后将验证码下载,最后再通过OCR技术进行验证码的识别工作. 1. 字
-
Python中常见的反爬机制及其破解方法总结
一.常见反爬机制及其破解方式 封禁IP,使用cookie等前面文章已经讲过 现在主要将下面的: ~ 验证码 -> 文字验证码 -> OCR(光学文字识别)-> 接口 / easyocr 程序自己解决不了的问题就可以考虑使用三方接口(付费/免费) -> 行为验证码 -> 超级鹰 ~ 手机号+短信验证码 -> 接码平台 ~ 动态内容 -> JavaScript逆向 -> 找到提供数据的API接口 -> 手机抓接口 -&g
-
python反扒机制的5种解决方法
前言 反爬虫是网站为了维护自己的核心安全而采取的抑制爬虫的手段,反爬虫的手段有很多种,一般情况下除了百度等网站,反扒机制会常常更新以外.为了保持网站运行的高效,网站采取的反扒机制并不是太多,今天分享几个我在爬虫过程中遇到的反扒机制,并简单介绍其解决方式. 基于User-Agent反爬 简介:服务器后台对访问的User_Agent进行统计,单位时间内同一User_Agent访问的次数超过特定的阀值,则会被不同程度的封禁IP,从而造成无法进行爬虫的状况. 解决方法: 一 . 将常见的User-Age
-
Python实现简单生成验证码功能【基于random模块】
本文实例讲述了Python实现简单生成验证码功能.分享给大家供大家参考,具体如下: 验证码一般用来验证登陆.交易等行为,减少对端为机器操作的概率,python中可以使用random模块,char()内置函数来实现一个简单的验证码功能. import random def veri_code(): li = [] for i in range(6): #循环6次,生成6个字符 r = random.randrange(0, 5) #随机生成0-4之间的数字 if r == 1 or r == 4:
-
Python反爬实战掌握酷狗音乐排行榜加密规则
目录 效果展示 爬取目标 工具使用 项目思路解析 简易源码分享 效果展示 爬取目标 网址:酷我音乐 工具使用 开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests,re 项目思路解析 找到需要解析的榜单数据 随意点击一个歌曲获取到音乐的详情数据 通过抓包的方式获取到音乐播放数据 找到MP3的数据提交地址 mp3数据来自于这个url地址 提交数据的网址: https://wwwapi.kugou.com/yy/index.php?r=play/
-
python爬虫爬取笔趣网小说网站过程图解
首先:文章用到的解析库介绍 BeautifulSoup: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能. 它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序. Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码. 你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了.然后,你仅仅
-
python selenium爬取斗鱼所有直播房间信息过程详解
还是分析一下大体的流程: 首先还是Chrome浏览器抓包分析元素,这是网址:https://www.douyu.com/directory/all 发现所有房间的信息都是保存在一个无序列表中的li中,所以我们可以先获取一个装有li的element对象的列表,然后在对每个element逐一操作 分析斗鱼的翻页,有一个下一页按钮,是个li,class="dy-Pagination-item-custom" ,但是当烦到最后一页的时候,class="dy-Pagination-di
-
python超详细实现字体反爬流程
目录 查策实战场景 字体实战解码 字体反爬编码时间 查策实战场景 本次要采集的目标站点是查策,该测试站点如下所示. 目标站点网址如下 www.chacewang.com/chanye/news?newstype=sbtz 该站点的新闻资讯类信息很容易采集,通过开发者工具查看了一下,并不存在加密反爬. 但字体反爬还是存在的,案例寻找过程非常简单,只需要开发者工具切换到网络,字体视图,然后预览一下字体文件即可. 可以看到仅数字进行了顺序变换. 接下来就是实战解码的过程,可以通过 FontCreato
-
python爬虫 urllib模块反爬虫机制UA详解
方法: 使用urlencode函数 urllib.request.urlopen() import urllib.request import urllib.parse url = 'https://www.sogou.com/web?' #将get请求中url携带的参数封装至字典中 param = { 'query':'周杰伦' } #对url中的非ascii进行编码 param = urllib.parse.urlencode(param) #将编码后的数据值拼接回url中 url += p
-
Python和JS反爬之解决反爬参数 signKey
目录 实战场景 系统分析 实战场景 Python 反爬中有一大类,叫做字体反爬,核心的理论就是通过字体文件或者 CSS 偏移,实现加密逻辑 本次要采集的站点是:54yr55y855S15b2x(Base64 加密) 站点地址为:https%3A%2F%2Fmaoyan.com%2Ffilms%2F522013(URL 编码) 上述地址打开之后,用开发者工具选中某文字之后,会发现 Elements 中,无法从源码读取到数据, 如下图所示: 类似的所有场景都属于字体编码系列,简单理解就是: 服务器源