Java集合框架之Map详解
目录
- 1、Map的实现
- 2、HashMap和Hashtable的区别
- 3、介绍下对象的hashCode()和equals(),使用场景
- 4、HashMap和TreeMap应该怎么选择,使用场景
- 5、Set和Map的关系TODO
- 6、常见Map的排序规则是怎样的?
- 7、如果需要线程安全,且效率高的Map,应该怎么做?
- 8、介绍下HashMap
- 9、什么是Hash碰撞?常见的解决办法有哪些,hashmap采用哪种方法?
- 10、HashMap底层是数组+链表+红黑树,为什么要用这几类结构呢?
- 11、为什么选择红黑树而不用其他树,比如二叉查找树,为什么不一直开始就用红黑树,而是到8的长度后才变换
- 12、了解ConcurrentHashMap吗?为什么性能比hashtable高,说下原理
- 13、jdk1.7和jdk1.8里面ConcurrentHashMap实现的区别有没了解
- 总结
1、Map的实现
- HashMap
- Hashtable
- LinkedHashMap
- TreeMap
- ConcurrentHashMap
2、HashMap 和 Hashtable 的区别
- HashMap:底层是基于数组+链表实现,非线程安全的,默认容量是16、允许有空的健和值
- Hashtable:基于哈希表实现,线程安全的(加了synchronized锁),默认容量是11,不允许有空的健和值
3、介绍下对象的 hashCode()和equals(),使用场景
hashCode:
顶级类Object里面的方法,所有的类都是继承Object,返回是一个int类型的数
根据一定的hash规则(存储地址,字段,长度等),映射成一个数值,即散列值
@Override
public int hashCode() {
return Objects.hash(age,name,time);
}
equals:
顶级类Object里面的方法,所有的类都是继承Object,返回是一个boolean类型
根据自定义的匹配规则,用于匹配两个对象是否一样,一般逻辑如下:
1、判断地址是否一样
2、非空判断 和 Class类型判断
3、强转
4、对象里面的字段一一匹配
@Override
public boolean equals(Object obj) {
if (obj == this)
return true;
if (obj == null || getClass() != obj.getClass())
return false;
User user = (User) obj;
return age == user.age && Objects.equals(name, user.name) && Objects.equals(time, user.time);
}
使用场景:对象比较、或者集合容器里面排重、比较、排序
4、HashMap和TreeMap应该怎么选择,使用场景
hashMap:
- 散列桶(数组+链表),可以实现快速的存储和检索,但是确实包含无序的元素,适用于在map中插入删除和定位元素
treeMap:
- 使用存储结构是一个平衡二叉树->红黑树,可以自定义排序规则,要实现Comparator接口
- 能便捷的实现内部元素的各种排序,但是一般性能比HashMap差,适用于安装自然排序或者自定义排序规则 (写过微信支付签名工具类就用这个类)
5、Set和Map的关系 TODO
核心就是不保存重复的元素,存储一组唯一的对象
set的每一种实现都是对应Map里面的一种封装,
HashSet对应的就是HashMap,treeSet对应的就是treeMap
- set:无序,不允许存在重复的元素
- list:有序,可以存在重复元素
- set 和 list 对比: 都是Collection的子接口,Collection是集合类;
- set 检查元素效率低下,删除和插入的效率高,插入和删除不会引起元素的位置变化;
- list 和数组类似,List可以动态增长,查找元素的效率较高,插入元素和删除元素效率低,因为会引起其他元素位置发生变化
- map: Map接口不是Collection接口的继承,而是从自己的用于维护键值对关联的接口层次结构入手,按定义,该接口描述了从不重复的键到值的映射
6、常见Map的排序规则是怎样的?
按照添加顺序使用LinkedHashMap,按照自然排序使用TreeMap,自定义排序 TreeMap(Comparetor c)
7、如果需要线程安全,且效率高的Map,应该怎么做?
- 多线程环境下可以用concurrent包下的ConcurrentHashMap,或者使用Collections.synchronizedMap(),
- ConcurrentHashMap虽然是线程安全,但是他的效率比Hashtable要高很多使用
- Collections.synchronizedMap包装后返回的map是加锁的
8、介绍下 HashMap
- HashMap底层(数组+链表+红黑树 jdk8才有红黑树),在JDK1.8中,链表的长度大于8,链表会转换成红黑树
- 数组中每一项是一个链表,即数组和链表的结合体
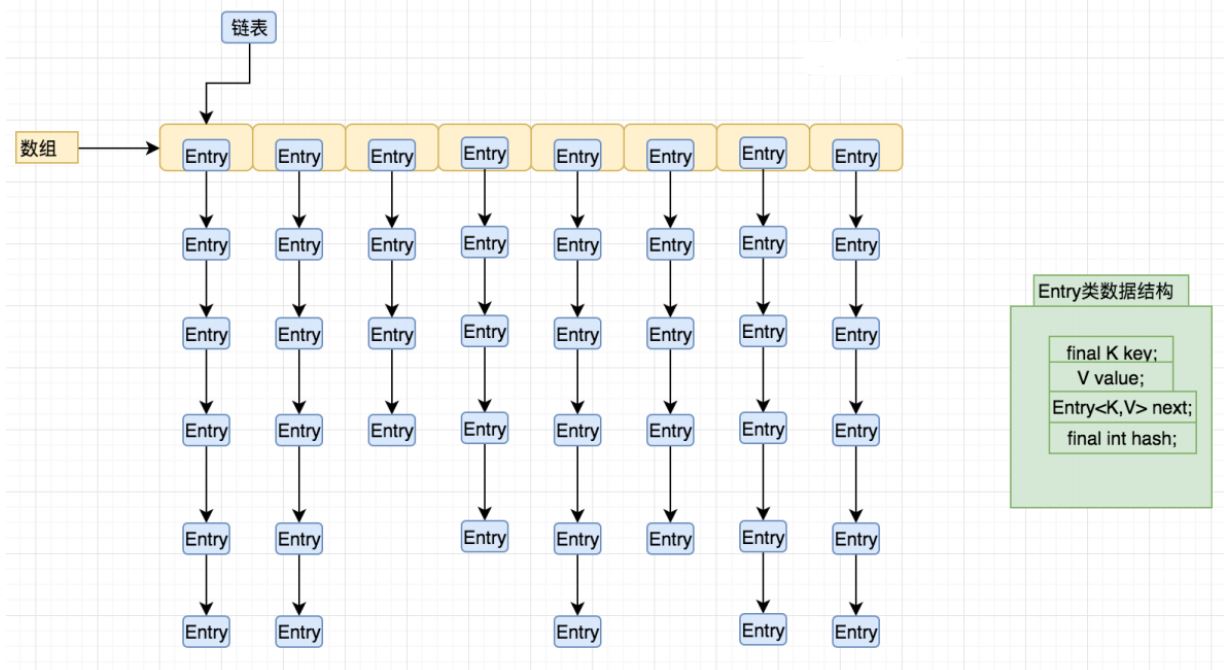
- Node<K,V>[] table
是数组,数组的元素是Entry(Node继承Entry),Entry元素是一个key-value的键值对,它持有一个指向下个Entry的引用,table数组的每个Entry元素同时也作为当前Entry链表的首节点,也指向了该链表的下个Entry元素
9、什么是Hash碰撞?常见的解决办法有哪些,hashmap采用哪种方法?
- hash碰撞的意思是不同key计算得到的Hash值相同,需要放到同个bucket中
- 常见的解决办法:链表法、开发地址法、再哈希法等
- HashMap采用的是链表法
10、HashMap底层是 数组+链表+红黑树,为什么要用这几类结构呢?
- 数组:Node<K,V>[] table ,根据对象的key的hash值确定在数组里面是哪个节点 - 链表:作用是解决hash冲突,将hash值一样的对象存在一个链表放在hash值对应的槽位
- 红黑树:JDK8使用红黑树来替代超过8个节点的链表,主要是查询性能的提升,从原来的O(n)到O(logn),
- 通过hash碰撞,让HashMap不断产生碰撞,那么相同key的位置的链表就会不断增长,
- 当对这个Hashmap的相应位置进行查询的时候,就会循环遍历这个超级大的链表,性能就会下降,所以改用红黑树
11、为什么选择红黑树而不用其他树,比如二叉查找树,为什么不一直开始就用红黑树,而是到8的长度后才变换
- 二叉查找树在特殊情况下也会变成一条线性结构,和原先的链表存在一样的深度遍历问题,查找性能就会慢,
- 使用红黑树主要是提升查找数据的速度,红黑树是平衡二叉树的一种,插入新数据后会通过左旋,右旋、变色等操作来保持平衡,解决单链表查询深度的问题
- 数据量少的时候操作数据,遍历线性表比红黑树所消耗的资源少,且前期数据少平衡二叉树保持平衡是需要消耗资源的,所以前期采用线性表,等到一定数之后变换到红黑树
12、了解ConcurrentHashMap吗?为什么性能比hashtable高,说下原理
- ConcurrentHashMap是线程安全的Map,因为hashtable类基本上所有的方法都是采用synchronized进行线程安全控制,高并发情况下效率就降低
- ConcurrentHashMap是采用了分段锁的思想提高性能,锁粒度更细化
13、jdk1.7和jdk1.8里面ConcurrentHashMap实现的区别有没了解
- JDK8之前,ConcurrentHashMap使用锁分段技术,将数据分成一段段存储,每个数据段配置一把锁,即segment类,这个类继承ReentrantLock来保证线程安全 【技术点:Segment + HashEntry】
- JKD8的版本取消Segment这个分段锁数据结构,底层也是使用Node数组+链表+红黑树,从而实现对每一段数据就行加锁,也减少了并发冲突的概率,CAS(读)+Synchronized(写)【技术点:Node + Cas + Synchronized】
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

Java集合框架之Set和Map详解
目录 Set接口 HashSet TreeSet Map接口 HashMap TreeMap Set接口 set接口等同于Collection接口,不过其方法的行为有更严谨的定义.set的add方法不允许增加重复的元素.要适当地定义set的equals方法:只要俩个set包含同样的元素就认为它们是相同的,而不要求这些元素有相同的顺序.hashCode方法的定义要保证包含相同元素的俩个set会得到相同的散列码. --Java核心技术 卷一 public interface Set<E> exte
-
Java集合框架源码分析之LinkedHashMap详解
LinkedHashMap简介 LinkedHashMap是HashMap的子类,与HashMap有着同样的存储结构,但它加入了一个双向链表的头结点,将所有put到LinkedHashmap的节点一一串成了一个双向循环链表,因此它保留了节点插入的顺序,可以使节点的输出顺序与输入顺序相同. LinkedHashMap可以用来实现LRU算法(这会在下面的源码中进行分析). LinkedHashMap同样是非线程安全的,只在单线程环境下使用. LinkedHashMap源码剖析 LinkedHashM
-
基于Java中最常用的集合类框架之HashMap(详解)
一.HashMap的概述 HashMap可以说是Java中最常用的集合类框架之一,是Java语言中非常典型的数据结构. HashMap是基于哈希表的Map接口实现的,此实现提供所有可选的映射操作.存储的是对的映射,允许多个null值和一个null键.但此类不保证映射的顺序,特别是它不保证该顺序恒久不变. 除了HashMap是非同步以及允许使用null外,HashMap 类与 Hashtable大致相同. 此实现假定哈希函数将元素适当地分布在各桶之间,可为基本操作(get 和 put)提供稳定的性
-
JAVA集合框架Map特性及实例解析
一 Map特性: 1 Map提供一种映射关系,其中的元素是以键值对(key-value)的形式存储的,能够实现根据key快速查找value: 2 Map中键值对以Entry类型的对象实例形式存在: 3 键,即key不可重复,但是value值可以: 4 每个键最多只能映射一个值: 5 Map接口提供了分别返回key值集合.value值集合以及Entry(键值对)集合的方法: 6 Map支持泛型,形式如:Map<K,V> 二 HashMap类: 1 HashMap是Map的一个重要实现类,也是最常
-
Java 集合框架掌握 Map 和 Set 的使用(内含哈希表源码解读及面试常考题)
目录 1. 搜索 1.1 场景引入 1.2 模型 2. Map 2.1 关于 Map 的介绍 2.2 关于 Map.Entry<K, V> 的介绍 2.3 Map 的常用方法说明 2.4 关于 HashMap 的介绍 2.5 关于 TreeMap 的介绍 2.6 HashMap 和 TreeMap 的区别 2.7 Map 使用示例代码 3. Set 3.1 关于 Set 的介绍 3.1 Set 的常用方法说明 3.3 关于 TreeSet 的介绍 3.4 关于 HashSet 的介绍 3.5
-
Java集合框架之Map详解
目录 1.Map的实现 2.HashMap和Hashtable的区别 3.介绍下对象的hashCode()和equals(),使用场景 4.HashMap和TreeMap应该怎么选择,使用场景 5.Set和Map的关系TODO 6.常见Map的排序规则是怎样的? 7.如果需要线程安全,且效率高的Map,应该怎么做? 8.介绍下HashMap 9.什么是Hash碰撞?常见的解决办法有哪些,hashmap采用哪种方法? 10.HashMap底层是数组+链表+红黑树,为什么要用这几类结构呢? 11.为
-
集合框架(Collections Framework)详解及代码示例
简介 集合和数组的区别: 数组存储基础数据类型,且每一个数组都只能存储一种数据类型的数据,空间不可变. 集合存储对象,一个集合中可以存储多种类型的对象.空间可变. 严格地说,集合是存储对象的引用,每个对象都称为集合的元素.根据存储时数据结构的不同,分为几类集合.但对象不管存储到什么类型的集合中,既然集合能存储任何类型的对象,这些对象在存储时都必须向上转型为Object类型,也就是说,集合中的元素都是Object类型的对象. 既然是集合,无论分为几类,它都有集合的共性,也就是说虽然存储时数据结构不
-
Java Executor 框架的实例详解
Java Executor 框架的实例详解 大多数并发都是通过任务执行的方式来实现的. 一般有两种方式执行任务:串行和并行. class SingleThreadWebServer { public static void main(String[] args) throws Exception { ServerSocket socket = new ServerSocket(80); while(true) { Socket conn = socket.accept(); handleRequ
-
java集合中的list详解
1.List接口 该接口定义的元素是有序的且可重复的.相当于数学里面的数列,有序可重复 booleanaddAll(intindex,Collection<?extendsE>c);将指定集合中所有元素,插入至本集合第index个元素之后defaultvoidreplaceAll(UnaryOperatoroperator);替换集合中每一个元素值defaultvoidsort(Comparator<?superE>c);给集合中的元素进行排序Eget(intindex);获取集合
-
Java反射框架Reflections示例详解
MAVEN 坐标 <dependency> <groupId>org.reflections</groupId> <artifactId>reflections</artifactId> <version>0.9.10</version> </dependency> Reflections 的作用 Reflections通过扫描classpath,索引元数据,并且允许在运行时查询这些元数据. 获取某个类型的所有
-
Java MyBatis框架环境搭建详解
目录 一.MyBatis简介 1.MyBatis历史 2.MyBatis特性 3.MyBatis下载 4.和其它持久化层技术对比 JDBC Hibernate 和 JPA MyBatis 二.搭建MyBatis 1.开发环境 2.创建maven工程 3.创建MyBatis的核心配置文件 4.创建mapper接口 5.创建MyBatis的映射文件 6.通过junit测试功能 7.加入log4j日志功能 一.MyBatis简介 1.MyBatis历史 MyBatis最初是Apache的一个开源项目i
-
基于Java ORM框架的使用详解
ORM框架不是一个新话题,它已经流传了很多年.它的优点在于提供了概念性的.易于理解的数据模型,将数据库中的表和内存中的对象建立了很好的映射关系.我们在这里主要关注Java中常用的两个ORM框架:Hibernate和iBatis.下面来介绍这两个框架简单的使用方法,如果将来有时间,我会深入的写一些更有意思的相关文章.HibernateHibernate是一个持久化框架和ORM框架,持久化和ORM是两个有区别的概念,持久化注重对象的存储方法是否随着程序的退出而消亡,ORM关注的是如何在数据库表和内存
-
Java集合之HashMap用法详解
本文实例讲述了Java集合之HashMap用法.分享给大家供大家参考,具体如下: HashMap是最常用的Map集合,它的键值对在存储时要根据键的哈希码来确定值放在哪里. HashMap 中作为键的对象必须重写Object的hashCode()方法和equals()方法 import java.util.Map; import java.util.HashMap; public class lzwCode { public static void main(String [] args) { M
-
Java集合Stack源码详解
概要 学完Vector了之后,接下来我们开始学习Stack.Stack很简单,它继承于Vector.学习方式还是和之前一样,先对Stack有个整体认识,然后再学习它的源码:最后再通过实例来学会使用它. 第1部分 Stack介绍 Stack简介 Stack是栈.它的特性是:先进后出(FILO, First In Last Out). java工具包中的Stack是继承于Vector(矢量队列)的,由于Vector是通过数组实现的,这就意味着,Stack也是通过数组实现的,而非链表.当然,我们也可以