使用PyTorch训练一个图像分类器实例
如下所示:
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
print("torch: %s" % torch.__version__)
print("tortorchvisionch: %s" % torchvision.__version__)
print("numpy: %s" % np.__version__)
Out:
torch: 1.0.0 tortorchvisionch: 0.2.1 numpy: 1.15.4
数据从哪儿来?
通常来说,你可以通过一些python包来把图像、文本、音频和视频数据加载为numpy array。然后将其转换为torch.*Tensor。
图像。Pillow、OpenCV是用得比较多的
音频。scipy和librosa
文本。纯Python或者Cython就可以完成数据加载,可以在NLTK和SpaCy找到数据
对于计算机视觉而言,我们有torchvision包,它可以用来加载一下常用数据集如Imagenet、CIFAR10、MINIST等等,也有一些常用的为图像准备数据转换例如torchvision.datasets和torch.utils.data.DataLoader。
这次的教程中,我们使用CIFAR10数据集,他有‘airplane', ‘automobile', ‘bird', ‘cat', ‘deer', ‘dog', ‘frog', ‘horse', ‘ship', ‘truck'这几个类别的图像。图像大小都是3x32x32的。也就是说,图像都是三通道的,每一张图的尺寸都是32x32。

训练一个图像分类器
步骤如下:
使用torchvision加载、归一化训练集和测试集
定义卷积神经网络
定义损失函数
使用训练集训练网络
使用测试集测试网络
1. 加载、归一化CIFAR10
我们可以使用torchvision很轻松的完成
torchvision的数据集是基于PILImage的,数值是[0, 1],我们需要将其转成范围为[-1, 1]的Tensor
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=4)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=True, num_workers=4)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Out:
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz Files already downloaded and verified
让我们来看看训练集的图片
# 显示一张图片
def imshow(img):
img = img / 2 + 0.5 # 逆归一化
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 任意地拿到一些图片
dataiter = iter(trainloader)
images, labels = dataiter.next()
# 显示图片
imshow(torchvision.utils.make_grid(images))
# 显示类标
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
Out:
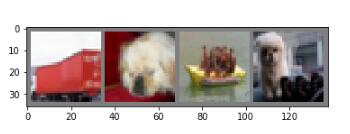
truck dog ship dog
2. 定义卷积神经网络
可以直接复制神经网络的代码,修改里面的几层即可。
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
3. 定义损失函数和优化器
使用多分类交叉熵损失函数,和带有momentum的SGD作为优化器
import torch.optim as optim criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=1e-3, momentum=0.9)
4. 训练网络
我们直接使用循环语句遍历数据集即可完成训练
nums_epoch = 2
for epoch in range(nums_epoch):
_loss = 0.0
for i, (inputs, labels) in enumerate(trainloader, 0):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_loss += loss.item()
if i % 2000 == 1999: # 每2000步打印一次损失值
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, _loss / 2000))
_loss = 0.0
print('Finished Training')
Out:
[1, 2000] loss: 1.178 [1, 4000] loss: 1.200 [1, 6000] loss: 1.168 [1, 8000] loss: 1.175 [1, 10000] loss: 1.185 [1, 12000] loss: 1.165 [2, 2000] loss: 1.073 [2, 4000] loss: 1.066 [2, 6000] loss: 1.100 [2, 8000] loss: 1.107 [2, 10000] loss: 1.083 [2, 12000] loss: 1.103 Finished Training
5. 测试网络
这个网络已经训练了两个epoch,我们现在来看看这个网络是不是学到了一些什么东西。
我们让这个神经网络预测几张图片,看看它的答案与真实答案的差别。
下面我们选取一些测试数据集中的数据,看看他们的真实标签。
# 展示测试数据集
dataiter = iter(testloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print('GraoundTruth: ', ' '.join(['%5s' % classes[labels[j]] for j in range(4)]))
Out:

GraoundTruth: ship ship deer ship
接着我们让神经网络来给出预测标签
神经网络的输出是10个信号值,信号值最高的那个神经元表示整个网络的预测值,所以我们需要拿到信号最强的那个节点的索引值
# 展示预测值
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join(['%5s' % classes[predicted[j]] for j in range(4)]))
Out:
Predicted: car ship horse ship
下面我们对整个测试集做一次评估:
# 评估测试数据集
correct, total = 0, 0
with torch.no_grad():
for images, labels in testloader:
outputs = net(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (labels == predicted).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
Out:
Accuracy of the network on the 10000 test images: 58 %
整个结果比随机猜要好得多(随机猜是10%的概率)。看来我们的神经网络还是学到了点东西。
下面我们来看看它在哪一个类别的分类上做得最好:
# 按类标评估
n_classes = len(classes)
class_correct, class_total = [0]*n_classes, [0]* n_classes
with torch.no_grad():
for images, labels in testloader:
outputs = net(images)
_, predicted = torch.max(outputs, 1)
is_correct = (labels == predicted).squeeze()
for i in range(len(labels)):
label = labels[i]
class_total[label] += 1
class_correct[label] += is_correct[i].item()
for i in range(n_classes):
print('Accuracy of %5s: %.2f %%' % (
classes[i], 100.0 * class_correct[i] / class_total[i]
))
Out:
Accuracy of plane: 67.00 % Accuracy of car: 71.50 % Accuracy of bird: 55.20 % Accuracy of cat: 45.60 % Accuracy of deer: 38.20 % Accuracy of dog: 47.00 % Accuracy of frog: 78.80 % Accuracy of horse: 55.90 % Accuracy of ship: 72.70 % Accuracy of truck: 57.50 %
在GPU上训练
就像把Tensor从CPU转移到GPU一样,神经网络也可以转移到GPU上
首先需要检查是否有可用的GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 假设我们在支持CUDA的机器上,我们可以打印出CUDA设备:
print(device)
Out:
cuda:0
我们假设device已经是CUDA设备了
下面命令将递归的将所有模块和参数、缓存转移到CUDA设备上去
net.to(device)
Out:
Net( (conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1)) (pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) (fc1): Linear(in_features=400, out_features=120, bias=True) (fc2): Linear(in_features=120, out_features=84, bias=True) (fc3): Linear(in_features=84, out_features=10, bias=True) )
注意,在训练过程中的传入输入数据时,也需要转移到GPU上
并且,需要重新实例化优化器,否则会报错
inputs, labels = inputs.to(device), labels.to(device)
练习:尝试增加神经网络的宽度。第一个nn.Conv2d的第二个参数和第二个nn.Conv2d的第一个参数的值必须一样。看看会有什么样的效果。
以上这篇使用PyTorch训练一个图像分类器实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
使用PyTorch将文件夹下的图片分为训练集和验证集实例
PyTorch提供了ImageFolder的类来加载文件结构如下的图片数据集: root/dog/xxx.png root/dog/xxy.png root/dog/xxz.png root/cat/123.png root/cat/nsdf3.png root/cat/asd932_.png 使用这个类的问题在于无法将训练集(training dataset)和验证集(validation dataset)分开.我写了两个类来完成这个工作. import os import torch fro
-
使用pytorch和torchtext进行文本分类的实例
文本分类是NLP领域的较为容易的入门问题,本文记录我自己在做文本分类任务以及复现相关论文时的基本流程,绝大部分操作都使用了torch和torchtext两个库. 1. 文本数据预处理 首先数据存储在三个csv文件中,分别是train.csv,valid.csv,test.csv,第一列存储的是文本数据,例如情感分类问题经常是用户的评论review,例如imdb或者amazon数据集.第二列是情感极性polarity,N分类问题的话就有N个值,假设值得范围是0~N-1. 下面是很常见的文本预处理流
-

详解PyTorch批训练及优化器比较
一.PyTorch批训练 1. 概述 PyTorch提供了一种将数据包装起来进行批训练的工具--DataLoader.使用的时候,只需要将我们的数据首先转换为torch的tensor形式,再转换成torch可以识别的Dataset格式,然后将Dataset放入DataLoader中就可以啦. import torch import torch.utils.data as Data torch.manual_seed(1) # 设定随机数种子 BATCH_SIZE = 5 x = torch.li
-
使用PyTorch训练一个图像分类器实例
如下所示: import torch import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as np print("torch: %s" % torch.__version__) print("tortorchvisionch: %s" % torchvision.__version__) print(&
-
Python Pytorch深度学习之图像分类器
目录 一.简介 二.数据集 三.训练一个图像分类器 1.导入package吧 2.归一化处理+贴标签吧 3.先来康康训练集中的照片吧 4.定义一个神经网络吧 5.定义一个损失函数和优化器吧 6.训练网络吧 7.在测试集上测试一下网络吧 8.分别查看一下训练效果吧 总结 一.简介 通常,当处理图像.文本.语音或视频数据时,可以使用标准Python将数据加载到numpy数组格式,然后将这个数组转换成torch.*Tensor 对于图像,可以用Pillow,OpenCV 对于语音,可以用scipy,l
-
基于PyTorch实现一个简单的CNN图像分类器
pytorch中文网:https://www.pytorchtutorial.com/ pytorch官方文档:https://pytorch.org/docs/stable/index.html 一. 加载数据 Pytorch的数据加载一般是用torch.utils.data.Dataset与torch.utils.data.Dataloader两个类联合进行.我们需要继承Dataset来定义自己的数据集类,然后在训练时用Dataloader加载自定义的数据集类. 1. 继承Dataset类并
-
基于Pytorch实现的声音分类实例代码
目录 前言 环境准备 安装libsora 安装PyAudio 安装pydub 训练分类模型 生成数据列表 训练 预测 其他 总结 前言 本章我们来介绍如何使用Pytorch训练一个区分不同音频的分类模型,例如你有这样一个需求,需要根据不同的鸟叫声识别是什么种类的鸟,这时你就可以使用这个方法来实现你的需求了. 源码地址:https://github.com/yeyupiaoling/AudioClassification-Pytorch 环境准备 主要介绍libsora,PyAudio,pydub
-
pytorch加载自己的图像数据集实例
之前学习深度学习算法,都是使用网上现成的数据集,而且都有相应的代码.到了自己开始写论文做实验,用到自己的图像数据集的时候,才发现无从下手 ,相信很多新手都会遇到这样的问题. 参考文章https://www.jb51.net/article/177613.htm 下面代码实现了从文件夹内读取所有图片,进行归一化和标准化操作并将图片转化为tensor.最后读取第一张图片并显示. # 数据处理 import os import torch from torch.utils import data fr
-
python 一个figure上显示多个图像的实例
方法一:主要是inshow()函数的使用 首先基本的画图流程为: import matplotlib.pyplot as plt #创建新的figure fig = plt.figure() #必须通过add_subplot()创建一个或多个绘图 #ax = fig.add_subplot(221) #绘制2x2两行两列共四个图,编号从1开始 ax1 = fig.add_subplot(221) ax2 = fig.add_subplot(222) ax3 = fig.add_subplot(2
-
pytorch ImageFolder的覆写实例
在为数据分类训练分类器的时候,比如猫狗分类时,我们经常会使用pytorch的ImageFolder: CLASS torchvision.datasets.ImageFolder(root, transform=None, target_transform=None, loader=<function default_loader>, is_valid_file=None) 使用可见pytorch torchvision.ImageFolder的用法介绍 这里想实现的是如果想要覆写该函数,即能
-
Pytorch之保存读取模型实例
pytorch保存数据 pytorch保存数据的格式为.t7文件或者.pth文件,t7文件是沿用torch7中读取模型权重的方式.而pth文件是python中存储文件的常用格式.而在keras中则是使用.h5文件. # 保存模型示例代码 print('===> Saving models...') state = { 'state': model.state_dict(), 'epoch': epoch # 将epoch一并保存 } if not os.path.isdir('checkpoin
-
pytorch中的transforms模块实例详解
pytorch中的transforms模块中包含了很多种对图像数据进行变换的函数,这些都是在我们进行图像数据读入步骤中必不可少的,下面我们讲解几种最常用的函数,详细的内容还请参考pytorch官方文档(放在文末). data_transforms = transforms.Compose([ transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms
-
pytorch 模拟关系拟合——回归实例
本次用 pytroch 来实现一个简单的回归分析,也借此机会来熟悉 pytorch 的一些基本操作. 1. 建立数据集 import torch from torch.autograd import Variable import matplotlib.pyplot as plt # torch.linspace(-1,1,100)表示返回一个一维张量,包含在区间 -1到1 上均匀间隔的100个点: # torch.unsqueeze(input,dim=1)表示转换维度 x = torch.u