python中DataFrame数据合并merge()和concat()方法详解
目录
- merge()
- 1.常规合并
- ①方法1
- ②方法2
- 重要参数
- 合并方式 left right outer inner
- 2.多对一合并
- 3.多对多合并
- concat()
- 1.相同字段的表首位相连
- 2.横向表合并(行对齐)
- 3.交叉合并
- 总结
merge()
1.常规合并
①方法1
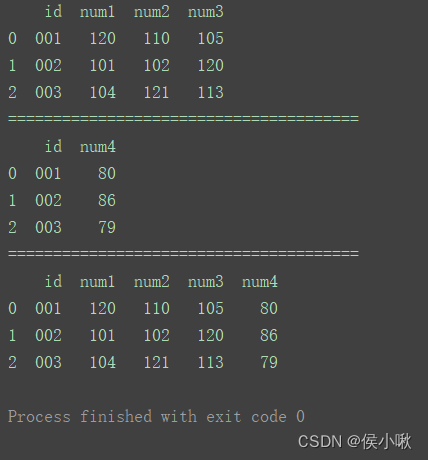
指定一个参照列,以该列为准,合并其他列。
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '002', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
df_merge = pd.merge(df1, df2, on='id')
print(df_merge)
②方法2
要实现该合并,也可以通过索引来合并,即以index列为基准。将left_index 和 right_index 都设置为True
即可。(left_index 和 right_index 都默认为False,left_index表示左表以左表数据的index为基准, right_index表示右表以右表数据的index为基准。)
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '002', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
df_merge = pd.merge(df1, df2, left_index=True, right_index=True)
print(df_merge)

相比方法①,区别在于,如图,方法②合并出的数据中有重复列。
重要参数
pd.merge(right,how=‘inner’, on=“None”, left_on=“None”, right_on=“None”, left_index=False, right_index=False )
| 参数 | 描述 |
|---|---|
| left | 左表,合并对象,DataFrame或Series |
| right | 右表,合并对象,DataFrame或Series |
| how | 合并方式,可以是left(左合并), right(右合并), outer(外合并), inner(内合并) |
| on | 基准列 的列名 |
| left_on | 左表基准列列名 |
| right_on | 右表基准列列名 |
| left_index | 左列是否以index为基准,默认False,否 |
| right_index | 右列是否以index为基准,默认False,否 |
其中,left_index与right_index 不能与 on 同时指定。
合并方式 left right outer inner
准备数据‘
新准备一组数据:
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '004', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")

inner(默认)
使用来自两个数据集的键的交集
df_merge = pd.merge(df1, df2, on='id') print(df_merge)

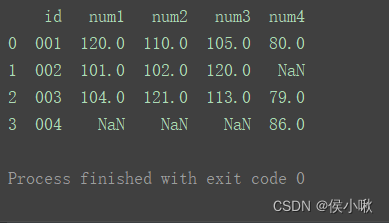
outer
使用来自两个数据集的键的并集
df_merge = pd.merge(df1, df2, on='id', how="outer") print(df_merge)
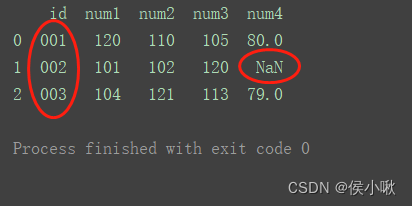
left
使用来自左数据集的键
df_merge = pd.merge(df1, df2, on='id', how='left') print(df_merge)
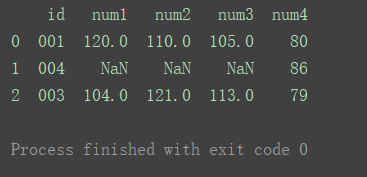
right
使用来自右数据集的键
df_merge = pd.merge(df1, df2, on='id', how='right') print(df_merge)
2.多对一合并
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '001', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
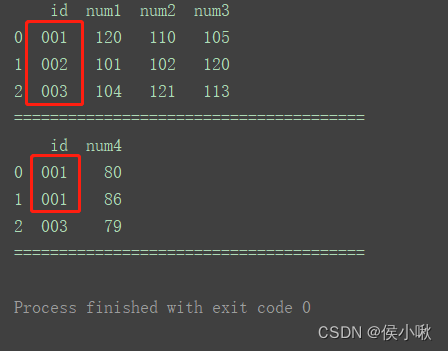
如图,df2中有重复id1的数据。
合并
df_merge = pd.merge(df1, df2, on='id') print(df_merge)
合并结果如图所示:

依然按照默认的Inner方式,使用来自两个数据集的键的交集。且重复的键的行会在合并结果中体现为多行。
3.多对多合并
如图表1和表2中都存在多行id重复的。
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '002', '002', '003'],
'num1': [120, 101, 104, 114, 123],
'num2': [110, 102, 121, 113, 126],
'num3': [105, 120, 113, 124, 128]})
df2 = pd.DataFrame({'id': ['001', '001', '002', '003', '001'],
'num4': [80, 86, 79, 88, 93]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")

df_merge = pd.merge(df1, df2, on='id') print(df_merge)

concat()
pd.concat(objs, axis=0, join=‘outer’, ignore_index:bool=False,keys=None,levels=None,names=None, verify_integrity:bool=False,sort:bool=False,copy:bool=True)
| 参数 | 描述 |
|---|---|
| objs | Series,DataFrame或Panel对象的序列或映射 |
| axis | 默认为0,表示列。如果为1则表示行。 |
| join | 默认为"outer",也可以为"inner" |
| ignore_index | 默认为False,表示保留索引(不忽略)。设为True则表示忽略索引。 |
其他重要参数通过实例说明。
1.相同字段的表首位相连
首先准备三组DataFrame数据:
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 114, 123],
'num2': [110, 102, 121],
'num3': [113, 124, 128]})
df2 = pd.DataFrame({'id': ['004', '005'],
'num1': [120, 101],
'num2': [113, 126],
'num3': [105, 128]})
df3 = pd.DataFrame({'id': ['007', '008', '009'],
'num1': [120, 101, 125],
'num2': [113, 126, 163],
'num3': [105, 128, 114]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
print(df3)

合并
dfs = [df1, df2, df3] result = pd.concat(dfs) print(result)

如果想要在合并后,标记一下数据都来自于哪张表或者数据的某类别,则也可以给concat加上 参数keys 。
result = pd.concat(dfs, keys=['table1', 'table2', 'table3']) print(result)

此时,添加的keys与原来的index组成元组,共同成为新的index。
print(result.index)

2.横向表合并(行对齐)
准备两组DataFrame数据:
import pandas as pd
df1 = pd.DataFrame({'num1': [120, 114, 123],
'num2': [110, 102, 121],
'num3': [113, 124, 128]}, index=['001', '002', '003'])
df2 = pd.DataFrame({'num3': [117, 120, 101, 126],
'num5': [113, 125, 126, 133],
'num6': [105, 130, 128, 128]}, index=['002', '003', '004', '005'])
print(df1)
print("=======================================")
print(df2)

当axis为默认值0时:
result = pd.concat([df1, df2]) print(result)

横向合并需要将axis设置为1 :
result = pd.concat([df1, df2], axis=1) print(result)

对比以上输出差异。
- axis=0时,即默认纵向合并时,如果出现重复的行,则会同时体现在结果中
- axis=1时,即横向合并时,如果出现重复的列,则会同时体现在结果中。
3.交叉合并
result = pd.concat([df1, df2], axis=1, join='inner') print(result)

总结
到此这篇关于python中DataFrame数据合并merge()和concat()方法的文章就介绍到这了,更多相关python数据合并merge()和concat()方法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python数据合并的concat函数与merge函数详解
目录 一.concat函数 1)横向堆叠与外连接 2) 纵向堆叠与内链接 二.merge()函数 1)根据行索引合并数据 2)合并重叠数据 一.concat函数 1.concat()函数可以沿着一条轴将多个对象进行堆叠,其使用方式类似数据库中的数据表合并pandas.concat(objs, axis=0, join=’outer’, join_axes=None, ignore_index=False, keys=None, levels=None, verify_integrity=Fals
-
python merge、concat合并数据集的实例讲解
数据规整化:合并.清理.过滤 pandas和python标准库提供了一整套高级.灵活的.高效的核心函数和算法将数据规整化为你想要的形式! 本篇博客主要介绍: 合并数据集:.merge()..concat()等方法,类似于SQL或其他关系型数据库的连接操作. 合并数据集 1) merge 函数参数 参数 说明 left 参与合并的左侧DataFrame right 参与合并的右侧DataFrame how 连接方式:'inner'(默认):还有,'outer'.'left'.'right' on
-
python中DataFrame数据合并merge()和concat()方法详解
目录 merge() 1.常规合并 ①方法1 ②方法2 重要参数 合并方式 left right outer inner 2.多对一合并 3.多对多合并 concat() 1.相同字段的表首位相连 2.横向表合并(行对齐) 3.交叉合并 总结 merge() 1.常规合并 ①方法1 指定一个参照列,以该列为准,合并其他列. import pandas as pd df1 = pd.DataFrame({'id': ['001', '002', '003'], 'num1': [120, 101,
-
pandas数据合并之pd.concat()用法详解
目录 一.简介 二 .代码 例1:上下堆叠拼接 例2:axis=1 左右拼接 一.简介 pd.concat()函数可以沿着指定的轴将多个dataframe或者series拼接到一起. 基本语法: pd.concat( objs, axis=0, join=‘outer’, join_axes=None,ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=Tr
-
在python中按照特定顺序访问字典的方法详解
最近使用python写一些东西,在参考资料的时候发现字典是没有顺序的,那么怎么样按照一定顺序访问字典呐,我找到了一个小方法: 假设一个字典是: D = {'a': '1', 'b': '2', 'c': '3'} 如果我们要按照a, b, c的顺序访问字典,可以借助一个列表,比如说: L = list(D.keys()) L.sort() for key in L: print(key, 'is' D[key]) 输出为: a is 1 b is 2 c is 3 需要倒序的话只需使用倒序函数排
-
Python中提取人脸特征的三种方法详解
目录 1.直接使用dlib 2.使用深度学习方法查找人脸,dlib提取特征 3.使用insightface提取人脸特征 安装InsightFace 提取特征 1.直接使用dlib 安装dlib方法: Win10安装dlib GPU过程详解 思路: 1.使用dlib.get_frontal_face_detector()方法检测人脸的位置. 2.使用 dlib.shape_predictor()方法得到人脸的关键点. 3.使用dlib.face_recognition_model_v1()方法提取
-
Python中import导入不同目录的模块方法详解
测试的目录如下: root ├── module_root.py ├── package_a │ ├── child │ │ ├── __init__.py │ │ └── child_a.py │ ├── module.py │ └── module_a.py └── package_b └── module_b.py 每个文件中的内容如下(__init__.py文件可以为空): print(__name
-
利用Python代码实现数据可视化的5种方法详解
前言 数据科学家并不逊色于艺术家.他们用数据可视化的方式绘画,试图展现数据内隐藏的模式或表达对数据的见解.更有趣的是,一旦接触到任何可视化的内容.数据时,人类会有更强烈的知觉.认知和交流. 数据可视化是数据科学家工作中的重要组成部分.在项目的早期阶段,你通常会进行探索性数据分析(Exploratory Data Analysis,EDA)以获取对数据的一些理解.创建可视化方法确实有助于使事情变得更加清晰易懂,特别是对于大型.高维数据集.在项目结束时,以清晰.简洁和引人注目的方式展现最终结果是非常
-
Struts2中validate数据校验的两种方法详解附Struts2常用校验器
1.Action中的validate()方法 Struts2提供了一个Validateable接口,这个接口中只存在validate()方法,实现这个接口的类可直接被Struts2调用,ActionSupport类就实现了Vadidateable接口,但他的validate()方法是一个空方法,需要我们来重写. validate()方法会在execute()方法执行前执行,仅当数据校验正确,才执行execute()方法, 如错误则将错误添加到fieldErrors域中,如果定义的Action中
-
python中对列表的删除和添加方法详解
目录 删除 1.pop(index) 2.remove(item) 3.dellist[index] 4.clear() 添加 1.append(obj) 2.extend(obj) 3.insert(index,obj) 总结 删除 1.pop(index) 删除列表中指定索引处的元素,默认删除列表中最后一个元素,返回删除值. list1 = [1, 2, 3, 5, 8, '3'] print(list1.pop(3)) print(list1) print(list1.pop()) pri
-
pandas中DataFrame数据合并连接(merge、join、concat)
pandas作者Wes McKinney 在[PYTHON FOR DATA ANALYSIS]中对pandas的方方面面都有了一个权威简明的入门级的介绍,但在实际使用过程中,我发现书中的内容还只是冰山一角.谈到pandas数据的行更新.表合并等操作,一般用到的方法有concat.join.merge.但这三种方法对于很多新手来说,都不太好分清使用的场合与用途.今天就pandas官网中关于数据合并和重述的章节做个使用方法的总结. 文中代码块主要有pandas官网教程提供. 1 concat co
-
在Pandas中DataFrame数据合并,连接(concat,merge,join)的实例
最近在工作中,遇到了数据合并.连接的问题,故整理如下,供需要者参考~ 一.concat:沿着一条轴,将多个对象堆叠到一起 concat方法相当于数据库中的全连接(union all),它不仅可以指定连接的方式(outer join或inner join)还可以指定按照某个轴进行连接.与数据库不同的是,它不会去重,但是可以使用drop_duplicates方法达到去重的效果. concat(objs, axis=0, join='outer', join_axes=None, ignore_ind