YOLOv5目标检测之anchor设定
目录
- 前言
- anchor的检测过程
- anchor产生过程
- 总结
前言
yolo算法作为one-stage领域的佼佼者,采用anchor-based的方法进行目标检测,使用不同尺度的anchor直接回归目标框并一次性输出目标框的位置和类别置信度。
为什么使用anchor进行检测?
最初的YOLOv1的初始训练过程很不稳定,在YOLOv2的设计过程中,作者观察了大量图片的ground truth,发现相同类别的目标实例具有相似的gt长宽比:比如车,gt都是矮胖的长方形;比如行人,gt都是瘦高的长方形。所以作者受此启发,从数据集中预先准备几个几率比较大的bounding box,再以它们为基准进行预测。
anchor的检测过程
首先,yolov5中使用的coco数据集输入图片的尺寸为640x640,但是训练过程的输入尺寸并不唯一,因为v5可以采用masaic增强技术把4张图片的部分组成了一张尺寸一定的输入图片。但是如果需要使用预训练权重,最好将输入图片尺寸调整到与作者相同的尺寸,而且输入图片尺寸必须是32的倍数,这与下面anchor检测的阶段有关。
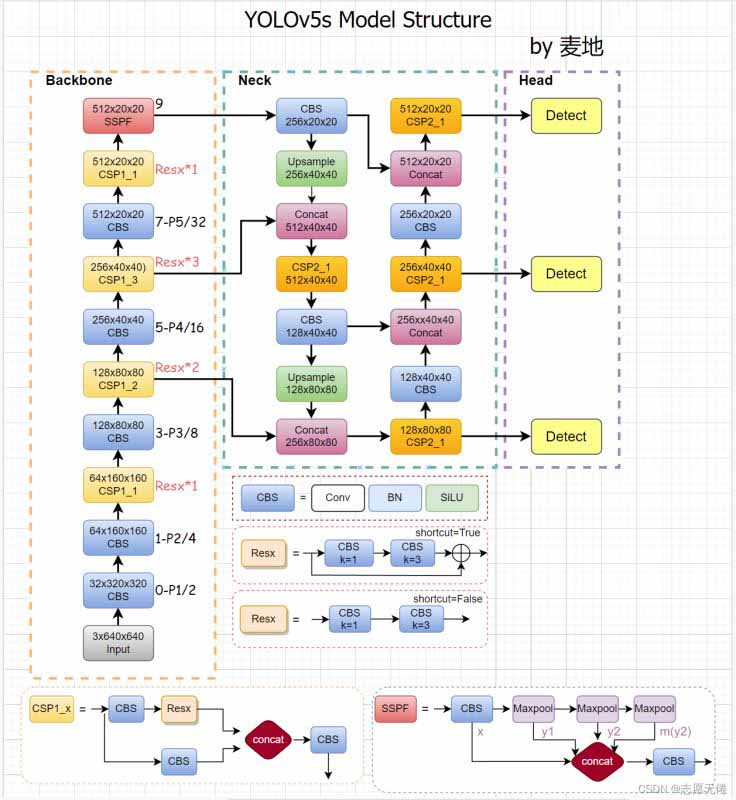
上图是我自己绘制的v5 v6.0的网络结构图。当我们的输入尺寸为640*640时,会得到3个不同尺度的输出:80x80(640/8)、40x40(640/16)、20x20(640/32),即上图中的CSP2_3模块的输出。
anchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32
其中,80x80代表浅层的特征图(P3),包含较多的低层级信息,适合用于检测小目标,所以这一特征图所用的anchor尺度较小;同理,20x20代表深层的特征图(P5),包含更多高层级的信息,如轮廓、结构等信息,适合用于大目标的检测,所以这一特征图所用的anchor尺度较大。另外的40x40特征图(P4)上就用介于这两个尺度之间的anchor用来检测中等大小的目标。yolov5之所以能高效快速地检测跨尺度目标,这种对不同特征图使用不同尺度的anchor的思想功不可没。
以上就是yolov5中的anchors的具体解释。
anchor产生过程
对于大部分图片而言,由于其尺寸与我们预设的输入尺寸不符,所以在输入阶段就做了resize,导致预先标注的bounding box大小也发生变化。而anchor是根据我们输入网络中的bounding box大小计算得到的,所以在这个resize过程中就存在anchor重新聚类的过程。在yolov5/utils/autoanchor.py文件下,有一个函数kmeans_anchor,通过kmeans的方法计算得到anchor。具体如下:
def kmean_anchors(dataset='./data/coco128.yaml', n=9, img_size=640, thr=4.0, gen=1000, verbose=True):
""" Creates kmeans-evolved anchors from training dataset
Arguments:
dataset: path to data.yaml, or a loaded dataset
n: number of anchors
img_size: image size used for training
thr: anchor-label wh ratio threshold hyperparameter hyp['anchor_t'] used for training, default=4.0
gen: generations to evolve anchors using genetic algorithm
verbose: print all results
Return:
k: kmeans evolved anchors
Usage:
from utils.autoanchor import *; _ = kmean_anchors()
"""
from scipy.cluster.vq import kmeans
thr = 1. / thr
prefix = colorstr('autoanchor: ')
def metric(k, wh): # compute metrics
r = wh[:, None] / k[None]
x = torch.min(r, 1. / r).min(2)[0] # ratio metric
# x = wh_iou(wh, torch.tensor(k)) # iou metric
return x, x.max(1)[0] # x, best_x
def anchor_fitness(k): # mutation fitness
_, best = metric(torch.tensor(k, dtype=torch.float32), wh)
return (best * (best > thr).float()).mean() # fitness
def print_results(k):
k = k[np.argsort(k.prod(1))] # sort small to large
x, best = metric(k, wh0)
bpr, aat = (best > thr).float().mean(), (x > thr).float().mean() * n # best possible recall, anch > thr
print(f'{prefix}thr={thr:.2f}: {bpr:.4f} best possible recall, {aat:.2f} anchors past thr')
print(f'{prefix}n={n}, img_size={img_size}, metric_all={x.mean():.3f}/{best.mean():.3f}-mean/best, '
f'past_thr={x[x > thr].mean():.3f}-mean: ', end='')
for i, x in enumerate(k):
print('%i,%i' % (round(x[0]), round(x[1])), end=', ' if i < len(k) - 1 else '\n') # use in *.cfg
return k
if isinstance(dataset, str): # *.yaml file
with open(dataset, errors='ignore') as f:
data_dict = yaml.safe_load(f) # model dict
from datasets import LoadImagesAndLabels
dataset = LoadImagesAndLabels(data_dict['train'], augment=True, rect=True)
# Get label wh
shapes = img_size * dataset.shapes / dataset.shapes.max(1, keepdims=True)
wh0 = np.concatenate([l[:, 3:5] * s for s, l in zip(shapes, dataset.labels)]) # wh
# Filter
i = (wh0 < 3.0).any(1).sum()
if i:
print(f'{prefix}WARNING: Extremely small objects found. {i} of {len(wh0)} labels are < 3 pixels in size.')
wh = wh0[(wh0 >= 2.0).any(1)] # filter > 2 pixels
# wh = wh * (np.random.rand(wh.shape[0], 1) * 0.9 + 0.1) # multiply by random scale 0-1
# Kmeans calculation
print(f'{prefix}Running kmeans for {n} anchors on {len(wh)} points...')
s = wh.std(0) # sigmas for whitening
k, dist = kmeans(wh / s, n, iter=30) # points, mean distance
assert len(k) == n, f'{prefix}ERROR: scipy.cluster.vq.kmeans requested {n} points but returned only {len(k)}'
k *= s
wh = torch.tensor(wh, dtype=torch.float32) # filtered
wh0 = torch.tensor(wh0, dtype=torch.float32) # unfiltered
k = print_results(k)
# Plot
# k, d = [None] * 20, [None] * 20
# for i in tqdm(range(1, 21)):
# k[i-1], d[i-1] = kmeans(wh / s, i) # points, mean distance
# fig, ax = plt.subplots(1, 2, figsize=(14, 7), tight_layout=True)
# ax = ax.ravel()
# ax[0].plot(np.arange(1, 21), np.array(d) ** 2, marker='.')
# fig, ax = plt.subplots(1, 2, figsize=(14, 7)) # plot wh
# ax[0].hist(wh[wh[:, 0]<100, 0],400)
# ax[1].hist(wh[wh[:, 1]<100, 1],400)
# fig.savefig('wh.png', dpi=200)
# Evolve
npr = np.random
f, sh, mp, s = anchor_fitness(k), k.shape, 0.9, 0.1 # fitness, generations, mutation prob, sigma
pbar = tqdm(range(gen), desc=f'{prefix}Evolving anchors with Genetic Algorithm:') # progress bar
for _ in pbar:
v = np.ones(sh)
while (v == 1).all(): # mutate until a change occurs (prevent duplicates)
v = ((npr.random(sh) < mp) * random.random() * npr.randn(*sh) * s + 1).clip(0.3, 3.0)
kg = (k.copy() * v).clip(min=2.0)
fg = anchor_fitness(kg)
if fg > f:
f, k = fg, kg.copy()
pbar.desc = f'{prefix}Evolving anchors with Genetic Algorithm: fitness = {f:.4f}'
if verbose:
print_results(k)
return print_results(k)
代码的注释部分其实已经对参数及调用方法解释的很清楚了,这里我只简单说一下:
Arguments:
dataset: 数据的yaml路径
n: 类簇的个数
img_size: 训练过程中的图片尺寸(32的倍数)
thr: anchor的长宽比阈值,将长宽比限制在此阈值之内
gen: k-means算法最大迭代次数(不理解的可以去看k-means算法)
verbose: 打印参数
Usage:
from utils.autoanchor import *; _ = kmean_anchors()
总结
到此这篇关于YOLOv5目标检测之anchor设定的文章就介绍到这了,更多相关YOLOv5 anchor设定内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

YOLOv5目标检测之anchor设定
目录 前言 anchor的检测过程 anchor产生过程 总结 前言 yolo算法作为one-stage领域的佼佼者,采用anchor-based的方法进行目标检测,使用不同尺度的anchor直接回归目标框并一次性输出目标框的位置和类别置信度. 为什么使用anchor进行检测? 最初的YOLOv1的初始训练过程很不稳定,在YOLOv2的设计过程中,作者观察了大量图片的ground truth,发现相同类别的目标实例具有相似的gt长宽比:比如车,gt都是矮胖的长方形:比如行人,gt都是瘦高的长方形
-
Pytorch搭建YoloV5目标检测平台实现过程
目录 学习前言 源码下载 YoloV5改进的部分(不完全) YoloV5实现思路 一.整体结构解析 二.网络结构解析 2.构建FPN特征金字塔进行加强特征提取 三.预测结果的解码 1.获得预测框与得分 2.得分筛选与非极大抑制 四.训练部分 1.计算loss所需内容 2.正样本的匹配过程 a.匹配先验框 b.匹配特征点 3.计算Loss 训练自己的YoloV5模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 学习前言 这个很久都没有学,最终还是决定看看,复现的是Yol
-
教你用YOLOv5实现多路摄像头实时目标检测功能
目录 前言 一.YOLOV5的强大之处 二.YOLOV5部署多路摄像头的web应用 1.多路摄像头读取 2.模型封装 3.Flask后端处理 4.前端展示 总结 前言 YOLOV5模型从发布到现在都是炙手可热的目标检测模型,被广泛运用于各大场景之中.因此,我们不光要知道如何进行yolov5模型的训练,而且还要知道怎么进行部署应用.在本篇博客中,我将利用yolov5模型简单的实现从摄像头端到web端的部署应用demo,为读者提供一些部署思路. 一.YOLOV5的强大之处 你与目标检测高手之差一个Y
-
如何使用yolov5输出检测到的目标坐标信息
找到detect.py,在大概113行,找到plot_one_box # Write results for *xyxy, conf, cls in reversed(det): if save_txt: # Write to file xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn)
-
YOLOv5改进系列之增加小目标检测层
目录 1.YOLOv5算法简介 2.原始YOLOv5模型 3.增加小目标检测层 总结 小目标检测一直以来是CV领域的难点之一,那么,YOLOv5该如何增加小目标检测层呢? YOLOv5代码修改————针对微小目标检测 1.YOLOv5算法简介 YOLOv5主要由输入端.Backone.Neck以及Prediction四部分组成.其中: (1) Backbone:在不同图像细粒度上聚合并形成图像特征的卷积神经网络. (2) Neck:一系列混合和组合图像特征的网络层,并将图像特征传递到预测层. (
-
Pytorch搭建YoloV4目标检测平台实现源码
目录 什么是YOLOV4 YOLOV4结构解析 1.主干特征提取网络Backbone 2.特征金字塔 3.YoloHead利用获得到的特征进行预测 4.预测结果的解码 5.在原图上进行绘制 YOLOV4的训练 1.YOLOV4的改进训练技巧 a).Mosaic数据增强 b).Label Smoothing平滑 c).CIOU d).学习率余弦退火衰减 2.loss组成 a).计算loss所需参数 b).y_pre是什么 c).y_true是什么. d).loss的计算过程 训练自己的YoloV4
-
Pytorch搭建yolo3目标检测平台实现源码
目录 yolo3实现思路 一.预测部分 1.主题网络darknet53介绍 2.从特征获取预测结果 3.预测结果的解码 4.在原图上进行绘制 二.训练部分 1.计算loss所需参数 2.pred是什么 3.target是什么. 4.loss的计算过程 训练自己的YoloV3模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 yolo3实现思路 一起来看看yolo3的Pytorch实现吧,顺便训练一下自己的数据. 源码下载 一.预测部分 1.主题网络darknet53介绍
-
python目标检测实现黑花屏分类任务示例
目录 背景 核心技术与架构图 技术实现 1.数据的标注 2.训练过程 3.损失的计算 4.对输出内容的处理 效果展示 总结 背景 视频帧的黑.花屏的检测是视频质量检测中比较重要的一部分,传统做法是由测试人员通过肉眼来判断视频中是否有黑.花屏的现象,这种方式不仅耗费人力且效率较低. 为了进一步节省人力.提高效率,一种自动的检测方法是大家所期待的.目前,通过分类网络模型对视频帧进行分类来自动检测是否有黑.花屏是比较可行且高效的. 然而,在项目过程中,视频帧数据的收集比较困难,数据量较少,部分花屏和正
-
10 行Python 代码实现 AI 目标检测技术【推荐】
只需10行Python代码,我们就能实现计算机视觉中目标检测. from imageai.Detection import ObjectDetection import os execution_path = os.getcwd() detector = ObjectDetection() detector.setModelTypeAsRetinaNet() detector.setModelPath( os.path.join(execution_path , "resnet50_coco_b
-
python opencv根据颜色进行目标检测的方法示例
颜色目标检测就是根据物体的颜色快速进行目标定位.使用cv2.inRange函数设定合适的阈值,即可以选出合适的目标. 建立项目colordetect.py,代码如下: #! /usr/bin/env python # -*- coding: utf-8 -*- import numpy as np import cv2 def colorDetect(): image = cv2.imread('./1.png') # 使用RGB颜色空间检测红 蓝 黄 灰,设置合适的阈值 boundaries