C#并行编程之PLINQ(并行LINQ)
用于对内存中的数据做并行运算,也就是说其只支持 LINQ to Object 的并行运算
一、AsParallel(并行化)
就是在集合后加个AsParallel()。
例如:
var numbers = Enumerable.Range(0, 100); var result = numbers.AsParallel().AsOrdered().Where(i => i % 2 == 0); foreach (var i in result) Console.WriteLine(i);
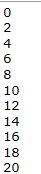
下面我们模拟给ConcurrentDictionary灌入1500w条记录,看看串行和并行效率上的差异,注意我的老爷机是2个硬件线程。
static void Main(string[] args)
{
var dic = LoadData();
Stopwatch watch = new Stopwatch();
watch.Start();
//串行执行
var query1 = (from n in dic.Values
where n.Age > 20 && n.Age < 25
select n).ToList();
watch.Stop();
Console.WriteLine("串行计算耗费时间:{0}", watch.ElapsedMilliseconds);
watch.Restart();
var query2 = (from n in dic.Values.AsParallel()
where n.Age > 20 && n.Age < 25
select n).ToList();
watch.Stop();
Console.WriteLine("并行计算耗费时间:{0}", watch.ElapsedMilliseconds);
Console.Read();
}
public static ConcurrentDictionary<int, Student> LoadData()
{
ConcurrentDictionary<int, Student> dic = new ConcurrentDictionary<int, Student>();
//预加载1500w条记录
Parallel.For(0, 15000000, (i) =>
{
var single = new Student()
{
ID = i,
Name = "hxc" + i,
Age = i % 151,
CreateTime = DateTime.Now.AddSeconds(i)
};
dic.TryAdd(i, single);
});
return dic;
}
public class Student
{
public int ID { get; set; }
public string Name { get; set; }
public int Age { get; set; }
public DateTime CreateTime { get; set; }
}
orderby,sum(),average()等等这些聚合函数都是实现了并行化。
二、指定并行度
这个我在前面文章也说过,为了不让并行计算占用全部的硬件线程,或许可能要留一个线程做其他事情。
var query2 = (from n in dic.Values.AsParallel().WithDegreeOfParallelism(Environment.ProcessorCount - 1)
where n.Age > 20 && n.Age < 25
orderby n.CreateTime descending
select n).ToList();
三、了解ParallelEnumerable类
首先这个类是Enumerable的并行版本,提供了很多用于查询实现的一组方法,下图为ParallelEnumerable类的方法,记住他们都是并行的。

ConcurrentBag<int> bag = new ConcurrentBag<int>();
var list = ParallelEnumerable.Range
(0, 10000);
list.ForAll((i) =>
{
bag.Add(i);
});
Console.WriteLine("bag集合中元素个数有:{0}", bag.Count);
Console.WriteLine("list集合中元素个数总和为:{0}", list.Sum());
Console.WriteLine("list集合中元素最大值为:{0}", list.Max());
Console.WriteLine("list集合中元素第一个元素为:{0}", list.FirstOrDefault());
四、plinq实现MapReduce算法
mapReduce是一个非常流行的编程模型,用于大规模数据集的并行计算,非常的牛X啊,记得mongodb中就用到了这个玩意。
- map: 也就是“映射”操作,可以为每一个数据项建立一个键值对,映射完后会形成一个键值对的集合。
- reduce:“化简”操作,我们对这些巨大的“键值对集合“进行分组,统计等等。
下面我举个例子,用Mapreduce来实现一个对age的分组统计。
static void Main(string[] args)
{
List<Student> list = new List<Student>()
{
new Student(){ ID=1, Name="jack", Age=20},
new Student(){ ID=1, Name="mary", Age=25},
new Student(){ ID=1, Name="joe", Age=29},
new Student(){ ID=1, Name="Aaron", Age=25},
};
//这里我们会对age建立一组键值对
var map = list.AsParallel().ToLookup(i => i.Age, count => 1);
//化简统计
var reduce = from IGrouping<int, int> singleMap
in map.AsParallel()
select new
{
Age = singleMap.Key,
Count = singleMap.Count()
};
///最后遍历
reduce.ForAll(i =>
{
Console.WriteLine("当前Age={0}的人数有:{1}人", i.Age, i.Count);
});
}
public class Student
{
public int ID { get; set; }
public string Name { get; set; }
public int Age { get; set; }
public DateTime CreateTime { get; set; }
}

考虑一个简单的例子,现有一个容量为1000000的单词集,需要我们以降序列出其中出现次数超过100000的单词(和其次数)。Map过程,使用PLINQ将集合按单词分组,这里使用了Lookup容器接口,它与Dictionary类似,但是提供的是键-值集映射;Reduce过程,使用PLINQ归约查询即可。
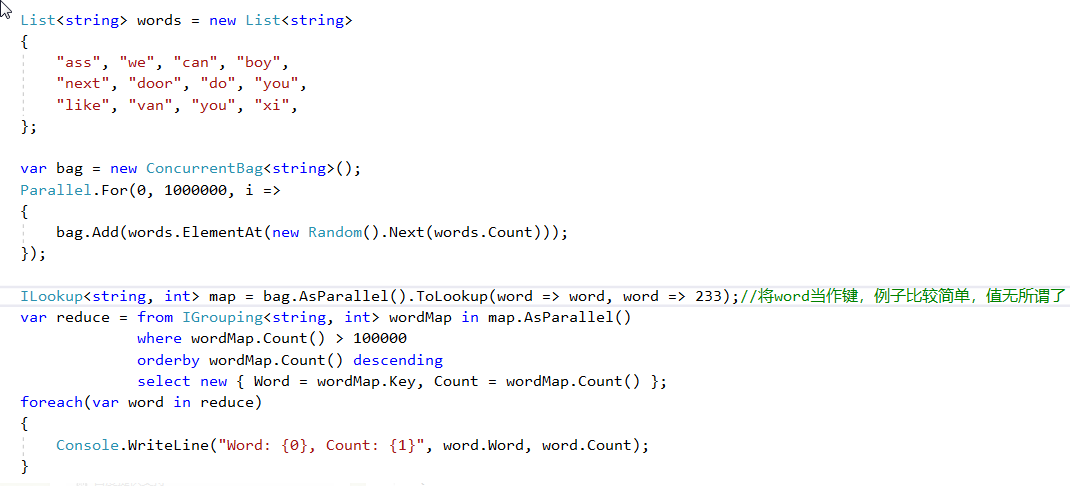
某一次运行结果如下:
Word: you, Count: 142416
Word: van, Count: 115816
Word: next, Count: 110228
到此这篇关于C#并行编程之PLINQ(并行LINQ)的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
详解c# PLINQ中的分区
最近因为比较忙,好久没有写博客了,这篇主要给大家分享一下PLINQ中的分区.上一篇介绍了并行编程,这边详细介绍一下并行编程中的分区和自定义分区. 先做个假设,假设我们有一个200Mb的文本文件需要读取,怎么样才能做到最优的速度呢?对,很显然就是拆分,把文本文件拆分成很多个小文件,充分利用我们计算机中的多核cpu的优势,让每个cpu都充分的利用,达到效率的最大化.然而在PLINQ中也是,我们有一个数据源,如果想进行最大的并行化操作,那么就需要把其拆分为可以多个线程同时访问的多个部分,这就是PLIN
-
C# PLINQ 内存列表查询优化历程
产品中(基于ASP.NET MVC开发)需要经常对药品名称及名称拼音码进行下拉匹配及结果查询.为了加快查询的速度,所以我最开始就将其加入内存中(大约有六万五千条数据). 下面附实体类. public class drugInfo { public int drug_nameid { get; set; } public string drug_name { get; set; } public string drug_search_code { get; set; } } 第一次做法: Stop
-

C# 并行和多线程编程——并行集合和PLinq
在上一篇博客,我们学习了Parallel的用法.并行编程,本质上是多线程的编程,那么当多个线程同时处理一个任务的时候,必然会出现资源访问问题,及所谓的线程安全.就像现实中,我们开发项目,就是一个并行的例子,把不同的模块分给不同的人,同时进行,才能在短的时间内做出大的项目.如果大家都只管自己写自己的代码,写完后发现合并不到一起,那么这种并行就没有了意义. 并行算法的出现,随之而产生的也就有了并行集合,及线程安全集合:微软向的也算周到,没有忘记linq,也推出了linq的并行版本,plinq - P
-
C#并行编程之PLINQ(并行LINQ)
用于对内存中的数据做并行运算,也就是说其只支持 LINQ to Object 的并行运算 一.AsParallel(并行化) 就是在集合后加个AsParallel(). 例如: var numbers = Enumerable.Range(0, 100); var result = numbers.AsParallel().AsOrdered().Where(i => i % 2 == 0); foreach (var i in result) Console.WriteLine(i); 下面我
-
C#并行编程之Task任务
任务,基于线程池.其使我们对并行编程变得更简单,且不用关心底层是怎么实现的.System.Threading.Tasks.Task类是Task Programming Library(TPL)中最核心的一个类. 一.任务与线程 1:任务是架构在线程之上的,也就是说任务最终还是要抛给线程去执行. 2:任务跟线程不是一对一的关系,比如开10个任务并不是说会开10个线程,这一点任务有点类似线程池,但是任务相比线程池有很小的开销和精确的控制. 我们用VS里面的“并行任务”看一看,快捷键Ctrl+D,K,
-
C#并行编程之Task同步机制
目录 一.隔离执行:不共享数据,让每个task都有一份自己的数据拷贝. 1.传统方式 2.ThreadLocal类 二.同步类型:通过调整task的执行,有序的执行task. 1.Lock锁 2.Interlocked 联锁 3.Mutex互斥体 三.申明性同步 四.并发集合 五.Barrier(屏障同步) 在并行计算中,不可避免的会碰到多个任务共享变量,实例,集合.虽然task自带了两个方法:task.ContinueWith()和Task.Factory.ContinueWhenAll()来
-
深入学习C#网络编程之HTTP应用编程(下)
第三篇来的好晚啊,上一篇说了如何向服务器推送信息,这一篇我们看看如何"快好准"的从服务器下拉信息. 网络上有很多大资源文件,比如供人下载的zip包,电影(你懂的),那么我们如何快速的进行下载,大家第一反应肯定就是多线程下载, 那么这些东西是如何做的呢?首先我们可以从"QQ的中转站里面拉一个rar下来". 然后用fiddler监视一下,我们会发现一个有趣的现象: 第一:7.62*1024*1024≈7990914 千真万确是此文件 第二:我明明是一个http链接,t
-
c++11多线程编程之std::async的介绍与实例
本节讨论下在C++11中怎样使用std::async来执行异步task. C++11中引入了std::async 什么是std::async std::async()是一个接受回调(函数或函数对象)作为参数的函数模板,并有可能异步执行它们. template<class Fn, class... Args> future<typename result_of<Fn(Args...)>::type> async(launch policy, Fn&& fn
-
Python网络编程之ZeroMQ知识总结
一.ZeroMQ概述 ZeroMQ(又名ØMQ,MQ,或zmq)像一个可嵌入的网络库,但其作用就像一个并发框架. ZeroMQ类似于标准Berkeley套接字,其提供了各种传输工具,如进程内.进程间.TCP和组播中进行原子消息传送的套接字 可以使用各种模式实现N对N的套接字连接,这些模式包括:发布-订阅.任务分配.请求-应答. ZeroMQ的速度足够快,因此可充当集群产品的结构. ZeroMQ的异步I/O模型提供了可扩展的多核应用程序,用异步消息来处理任务 ZeroMQ核心由C语言编写,支持C.
-
Java并发编程之Executors类详解
一.Executors的理解 Executors类属于java.util.concurrent包: 线程池的创建分为两种方式:ThreadPoolExecutor 和 Executors: Executors(静态Executor工厂)用于创建线程池: 工厂和工具方法Executor , ExecutorService , ScheduledExecutorService , ThreadFactory和Callable在此包中定义的类: jdk1.8API中的解释如下: 二.Executors
-
分析并发编程之LongAdder原理
目录 一.前言 二.LongAdder类的使用 三.LongAdder原理的直观理解 四.源码分析 五.与AtomicInteger的比较 六.思想的抽象 一.前言 ConcurrentHashMap的源码采用了一种比较独特的方式对map中的元素数量进行统计,自然是要好好研究一下其原理思想,同时也能更好地理解ConcurrentHashMap本身. 本文主要思路分为以下5个部分: 1.计数的使用效果 2.原理的直观图解 3.源码的细节分析 4.与AtomicInteger的比较 5.思想的抽象
-
c# 网络编程之tcp
一.概述 UDP和TCP是网络通讯常用的两个传输协议,C#一般可以通过Socket来实现UDP和TCP通讯,由于.NET框架通过UdpClient.TcpListener .TcpClient这几个类对Socket进行了封装,使其使用更加方便, 本文就通过这几个封装过的类讲解一下相关应用. 二.基本应用:连接.发送.接收 服务端建立侦听并等待连接: TcpListener tcpListener = new TcpListener(IPAddress.Parse("127.0.0.1"