带你了解Java数据结构和算法之链表
目录
- 1、链表(Linked List)
- 2、单向链表(Single-Linked List)
- ①、单向链表的具体实现
- ②、用单向链表实现栈
- 4、双端链表
- ①、双端链表的具体实现
- ②、用双端链表实现队列
- 5、抽象数据类型(ADT)
- 6、有序链表
- 7、有序链表和无序数组组合排序
- 8、双向链表
- 9、总结
前面博客我们在讲解数组中,知道数组作为数据存储结构有一定的缺陷。在无序数组中,搜索性能差,在有序数组中,插入效率又很低,而且这两种数组的删除效率都很低,并且数组在创建后,其大小是固定了,设置的过大会造成内存的浪费,过小又不能满足数据量的存储。
本篇博客我们将讲解一种新型的数据结构——链表。我们知道数组是一种通用的数据结构,能用来实现栈、队列等很多数据结构。而链表也是一种使用广泛的通用数据结构,它也可以用来作为实现栈、队列等数据结构的基础,基本上除非需要频繁的通过下标来随机访问各个数据,否则很多使用数组的地方都可以用链表来代替。
但是我们需要说明的是,链表是不能解决数据存储的所有问题的,它也有它的优点和缺点。本篇博客我们介绍几种常见的链表,分别是单向链表、双端链表、有序链表、双向链表以及有迭代器的链表。并且会讲解一下抽象数据类型(ADT)的思想,如何用 ADT 描述栈和队列,如何用链表代替数组来实现栈和队列。
1、链表(Linked List)
链表通常由一连串节点组成,每个节点包含任意的实例数据(data fields)和一或两个用来指向上一个/或下一个节点的位置的链接("links")
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer)。
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
2、单向链表(Single-Linked List)
单链表是链表中结构最简单的。一个单链表的节点(Node)分为两个部分,第一个部分(data)保存或者显示关于节点的信息,另一个部分存储下一个节点的地址。最后一个节点存储地址的部分指向空值。
单向链表只可向一个方向遍历,一般查找一个节点的时候需要从第一个节点开始每次访问下一个节点,一直访问到需要的位置。而插入一个节点,对于单向链表,我们只提供在链表头插入,只需要将当前插入的节点设置为头节点,next指向原头节点即可。删除一个节点,我们将该节点的上一个节点的next指向该节点的下一个节点。
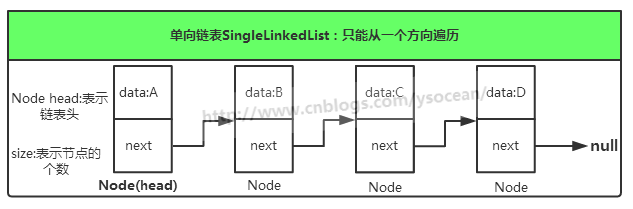
在表头增加节点:
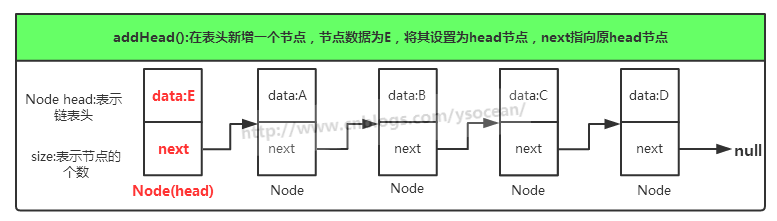
删除节点:
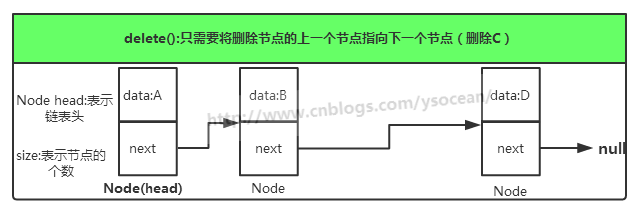
①、单向链表的具体实现
package com.ys.datastructure;
public class SingleLinkedList {
private int size;//链表节点的个数
private Node head;//头节点
public SingleLinkedList(){
size = 0;
head = null;
}
//链表的每个节点类
private class Node{
private Object data;//每个节点的数据
private Node next;//每个节点指向下一个节点的连接
public Node(Object data){
this.data = data;
}
}
//在链表头添加元素
public Object addHead(Object obj){
Node newHead = new Node(obj);
if(size == 0){
head = newHead;
}else{
newHead.next = head;
head = newHead;
}
size++;
return obj;
}
//在链表头删除元素
public Object deleteHead(){
Object obj = head.data;
head = head.next;
size--;
return obj;
}
//查找指定元素,找到了返回节点Node,找不到返回null
public Node find(Object obj){
Node current = head;
int tempSize = size;
while(tempSize > 0){
if(obj.equals(current.data)){
return current;
}else{
current = current.next;
}
tempSize--;
}
return null;
}
//删除指定的元素,删除成功返回true
public boolean delete(Object value){
if(size == 0){
return false;
}
Node current = head;
Node previous = head;
while(current.data != value){
if(current.next == null){
return false;
}else{
previous = current;
current = current.next;
}
}
//如果删除的节点是第一个节点
if(current == head){
head = current.next;
size--;
}else{//删除的节点不是第一个节点
previous.next = current.next;
size--;
}
return true;
}
//判断链表是否为空
public boolean isEmpty(){
return (size == 0);
}
//显示节点信息
public void display(){
if(size >0){
Node node = head;
int tempSize = size;
if(tempSize == 1){//当前链表只有一个节点
System.out.println("["+node.data+"]");
return;
}
while(tempSize>0){
if(node.equals(head)){
System.out.print("["+node.data+"->");
}else if(node.next == null){
System.out.print(node.data+"]");
}else{
System.out.print(node.data+"->");
}
node = node.next;
tempSize--;
}
System.out.println();
}else{//如果链表一个节点都没有,直接打印[]
System.out.println("[]");
}
}
}
测试:
@Test
public void testSingleLinkedList(){
SingleLinkedList singleList = new SingleLinkedList();
singleList.addHead("A");
singleList.addHead("B");
singleList.addHead("C");
singleList.addHead("D");
//打印当前链表信息
singleList.display();
//删除C
singleList.delete("C");
singleList.display();
//查找B
System.out.println(singleList.find("B"));
}
打印结果:
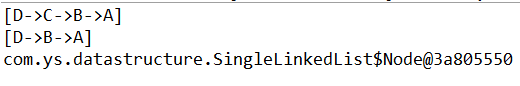
②、用单向链表实现栈
栈的pop()方法和push()方法,对应于链表的在头部删除元素deleteHead()以及在头部增加元素addHead()。
package com.ys.datastructure;
public class StackSingleLink {
private SingleLinkedList link;
public StackSingleLink(){
link = new SingleLinkedList();
}
//添加元素
public void push(Object obj){
link.addHead(obj);
}
//移除栈顶元素
public Object pop(){
Object obj = link.deleteHead();
return obj;
}
//判断是否为空
public boolean isEmpty(){
return link.isEmpty();
}
//打印栈内元素信息
public void display(){
link.display();
}
}
4、双端链表
对于单项链表,我们如果想在尾部添加一个节点,那么必须从头部一直遍历到尾部,找到尾节点,然后在尾节点后面插入一个节点。这样操作很麻烦,如果我们在设计链表的时候多个对尾节点的引用,那么会简单很多。
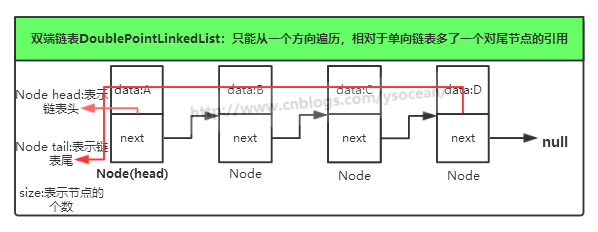
注意和后面将的双向链表的区别!!!
①、双端链表的具体实现
package com.ys.link;
public class DoublePointLinkedList {
private Node head;//头节点
private Node tail;//尾节点
private int size;//节点的个数
private class Node{
private Object data;
private Node next;
public Node(Object data){
this.data = data;
}
}
public DoublePointLinkedList(){
size = 0;
head = null;
tail = null;
}
//链表头新增节点
public void addHead(Object data){
Node node = new Node(data);
if(size == 0){//如果链表为空,那么头节点和尾节点都是该新增节点
head = node;
tail = node;
size++;
}else{
node.next = head;
head = node;
size++;
}
}
//链表尾新增节点
public void addTail(Object data){
Node node = new Node(data);
if(size == 0){//如果链表为空,那么头节点和尾节点都是该新增节点
head = node;
tail = node;
size++;
}else{
tail.next = node;
tail = node;
size++;
}
}
//删除头部节点,成功返回true,失败返回false
public boolean deleteHead(){
if(size == 0){//当前链表节点数为0
return false;
}
if(head.next == null){//当前链表节点数为1
head = null;
tail = null;
}else{
head = head.next;
}
size--;
return true;
}
//判断是否为空
public boolean isEmpty(){
return (size ==0);
}
//获得链表的节点个数
public int getSize(){
return size;
}
//显示节点信息
public void display(){
if(size >0){
Node node = head;
int tempSize = size;
if(tempSize == 1){//当前链表只有一个节点
System.out.println("["+node.data+"]");
return;
}
while(tempSize>0){
if(node.equals(head)){
System.out.print("["+node.data+"->");
}else if(node.next == null){
System.out.print(node.data+"]");
}else{
System.out.print(node.data+"->");
}
node = node.next;
tempSize--;
}
System.out.println();
}else{//如果链表一个节点都没有,直接打印[]
System.out.println("[]");
}
}
}
②、用双端链表实现队列
package com.ys.link;
public class QueueLinkedList {
private DoublePointLinkedList dp;
public QueueLinkedList(){
dp = new DoublePointLinkedList();
}
public void insert(Object data){
dp.addTail(data);
}
public void delete(){
dp.deleteHead();
}
public boolean isEmpty(){
return dp.isEmpty();
}
public int getSize(){
return dp.getSize();
}
public void display(){
dp.display();
}
}
5、抽象数据类型(ADT)
在介绍抽象数据类型的时候,我们先看看什么是数据类型,听到这个词,在Java中我们可能首先会想到像 int,double这样的词,这是Java中的基本数据类型,一个数据类型会涉及到两件事:
- ①、拥有特定特征的数据项
- ②、在数据上允许的操作
比如Java中的int数据类型,它表示整数,取值范围为:-2147483648~2147483647,还能使用各种操作符,+、-、*、/ 等对其操作。数据类型允许的操作是它本身不可分离的部分,理解类型包括理解什么样的操作可以应用在该类型上。
那么当年设计计算机语言的人,为什么会考虑到数据类型?
我们先看这样一个例子,比如,大家都需要住房子,也都希望房子越大越好。但显然,没有钱,考虑房子没有意义。于是就出现了各种各样的商品房,有别墅的、复式的、错层的、单间的……甚至只有两平米的胶囊房间。这样做的意义是满足不同人的需要。
同样,在计算机中,也存在相同的问题。计算1+1这样的表达式不需要开辟很大的存储空间,不需要适合小数甚至字符运算的内存空间。于是计算机的研究者们就考虑,要对数据进行分类,分出来多种数据类型。比如int,比如float。
虽然不同的计算机有不同的硬件系统,但实际上高级语言编写者才不管程序运行在什么计算机上,他们的目的就是为了实现整形数字的运算,比如a+b等。他们才不关心整数在计算机内部是如何表示的,也不管CPU是如何计算的。于是我们就考虑,无论什么计算机、什么语言都会面临类似的整数运算,我们可以考虑将其抽象出来。抽象是抽取出事物具有的普遍性本质,是对事物的一个概括,是一种思考问题的方式。
抽象数据类型(ADT)是指一个数学模型及定义在该模型上的一组操作。它仅取决于其逻辑特征,而与计算机内部如何表示和实现无关。比如刚才说得整型,各个计算机,不管大型机、小型机、PC、平板电脑甚至智能手机,都有“整型”类型,也需要整形运算,那么整型其实就是一个抽象数据类型。
更广泛一点的,比如我们刚讲解的栈和队列这两种数据结构,我们分别使用了数组和链表来实现,比如栈,对于使用者只需要知道pop()和push()方法或其它方法的存在以及如何使用即可,使用者不需要知道我们是使用的数组或是链表来实现的。
ADT的思想可以作为我们设计工具的理念,比如我们需要存储数据,那么就从考虑需要在数据上实现的操作开始,需要存取最后一个数据项吗?还是第一个?还是特定值的项?还是特定位置的项?回答这些问题会引出ADT的定义,只有完整的定义了ADT后,才应该考虑实现的细节。
这在我们Java语言中的接口设计理念是想通的。
6、有序链表
前面的链表实现插入数据都是无序的,在有些应用中需要链表中的数据有序,这称为有序链表。
在有序链表中,数据是按照关键值有序排列的。一般在大多数需要使用有序数组的场合也可以使用有序链表。有序链表优于有序数组的地方是插入的速度(因为元素不需要移动),另外链表可以扩展到全部有效的使用内存,而数组只能局限于一个固定的大小中。
package com.ys.datastructure;
public class OrderLinkedList {
private Node head;
private class Node{
private int data;
private Node next;
public Node(int data){
this.data = data;
}
}
public OrderLinkedList(){
head = null;
}
//插入节点,并按照从小打到的顺序排列
public void insert(int value){
Node node = new Node(value);
Node pre = null;
Node current = head;
while(current != null && value > current.data){
pre = current;
current = current.next;
}
if(pre == null){
head = node;
head.next = current;
}else{
pre.next = node;
node.next = current;
}
}
//删除头节点
public void deleteHead(){
head = head.next;
}
public void display(){
Node current = head;
while(current != null){
System.out.print(current.data+" ");
current = current.next;
}
System.out.println("");
}
}
在有序链表中插入和删除某一项最多需要O(N)次比较,平均需要O(N/2)次,因为必须沿着链表上一步一步走才能找到正确的插入位置,然而可以最快速度删除最值,因为只需要删除表头即可,如果一个应用需要频繁的存取最小值,且不需要快速的插入,那么有序链表是一个比较好的选择方案。比如优先级队列可以使用有序链表来实现。
7、有序链表和无序数组组合排序
比如有一个无序数组需要排序,前面我们在讲解冒泡排序、选择排序、插入排序这三种简单的排序时,需要的时间级别都是O(N2)。
现在我们讲解了有序链表之后,对于一个无序数组,我们先将数组元素取出,一个一个的插入到有序链表中,然后将他们从有序链表中一个一个删除,重新放入数组,那么数组就会排好序了。和插入排序一样,如果插入了N个新数据,那么进行大概N2/4次比较。但是相对于插入排序,每个元素只进行了两次排序,一次从数组到链表,一次从链表到数组,大概需要2*N次移动,而插入排序则需要N2次移动,
效率肯定是比前面讲的简单排序要高,但是缺点就是需要开辟差不多两倍的空间,而且数组和链表必须在内存中同时存在,如果有现成的链表可以用,那么这种方法还是挺好的。
8、双向链表
我们知道单向链表只能从一个方向遍历,那么双向链表它可以从两个方向遍历。
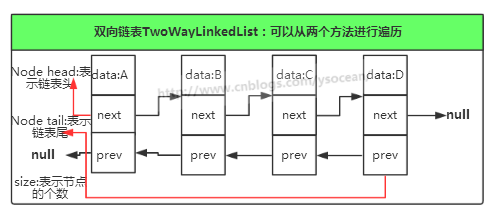
具体代码实现:
package com.ys.datastructure;
public class TwoWayLinkedList {
private Node head;//表示链表头
private Node tail;//表示链表尾
private int size;//表示链表的节点个数
private class Node{
private Object data;
private Node next;
private Node prev;
public Node(Object data){
this.data = data;
}
}
public TwoWayLinkedList(){
size = 0;
head = null;
tail = null;
}
//在链表头增加节点
public void addHead(Object value){
Node newNode = new Node(value);
if(size == 0){
head = newNode;
tail = newNode;
size++;
}else{
head.prev = newNode;
newNode.next = head;
head = newNode;
size++;
}
}
//在链表尾增加节点
public void addTail(Object value){
Node newNode = new Node(value);
if(size == 0){
head = newNode;
tail = newNode;
size++;
}else{
newNode.prev = tail;
tail.next = newNode;
tail = newNode;
size++;
}
}
//删除链表头
public Node deleteHead(){
Node temp = head;
if(size != 0){
head = head.next;
head.prev = null;
size--;
}
return temp;
}
//删除链表尾
public Node deleteTail(){
Node temp = tail;
if(size != 0){
tail = tail.prev;
tail.next = null;
size--;
}
return temp;
}
//获得链表的节点个数
public int getSize(){
return size;
}
//判断链表是否为空
public boolean isEmpty(){
return (size == 0);
}
//显示节点信息
public void display(){
if(size >0){
Node node = head;
int tempSize = size;
if(tempSize == 1){//当前链表只有一个节点
System.out.println("["+node.data+"]");
return;
}
while(tempSize>0){
if(node.equals(head)){
System.out.print("["+node.data+"->");
}else if(node.next == null){
System.out.print(node.data+"]");
}else{
System.out.print(node.data+"->");
}
node = node.next;
tempSize--;
}
System.out.println();
}else{//如果链表一个节点都没有,直接打印[]
System.out.println("[]");
}
}
}
我们也可以用双向链表来实现双端队列,这里就不做具体代码演示了。
9、总结
上面我们讲了各种链表,每个链表都包括一个LinikedList对象和许多Node对象,LinkedList对象通常包含头和尾节点的引用,分别指向链表的第一个节点和最后一个节点。而每个节点对象通常包含数据部分data,以及对上一个节点的引用prev和下一个节点的引用next,只有下一个节点的引用称为单向链表,两个都有的称为双向链表。next值为null则说明是链表的结尾,如果想找到某个节点,我们必须从第一个节点开始遍历,不断通过next找到下一个节点,直到找到所需要的。栈和队列都是ADT,可以用数组来实现,也可以用链表实现。
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

Java数据结构与算法学习之循环链表
目录 存储结构示意图 初始化循环链表 循环链表的插入 首位置 代码实现 其他位置 代码实现(总) 循环链表的删除 1.操作的为第一个元素 2.操作元素不为第一个元素 代码实现(总) 循环链表的常见操作 存储结构示意图 优点 : 能够通过任意结点遍历整个链表结构 初始化循环链表 1.循环链表的结点 typedef struct CircularNode { ElementType date; //数据域 struct CircularNode* next; //指向下一个结点的指针域 }Ci
-
Java数据结构与算法之单链表深入理解
目录 一.单链表(Linked List)简介 二.单链表的各种操作 1.单链表的创建和遍历 2.单链表的按顺序插入节点 以及节点的修改 3.单链表节点的删除 4.以上单链表操作的代码实现 (通过一个实例应用) 三.单链表常见面试题 1.求单链表中节点的个数 2.查找单链表中的倒数第K个节点[新浪面试题] 3.单链表的反转[腾讯面试题,有点难度] 4.从尾到头打印单链表 一.单链表(Linked List)简介 二.单链表的各种操作 1.单链表的创建和遍历 2.单链表的按顺序插入节点 以及节点的
-
详解java数据结构与算法之双链表设计与实现
在单链表分析中,我们可以知道每个结点只有一个指向后继结点的next域,倘若此时已知当前结点p,需要查找其前驱结点,那么就必须从head头指针遍历至p的前驱结点,操作的效率很低,因此如果p有一个指向前驱结点的next域,那效率就高多了,对于这种一个结点中分别包含了前驱结点域pre和后继结点域next的链表,称之为双链表.本篇我们将从以下结点来分析双链表 双链表的设计与实现 双链表的主要优点是对于任意给的结点,都可以很轻易的获取其前驱结点或者后继结点,而主要缺点是每个结点需要添加额外的next域,因
-
Java数据结构与算法学习之双向链表
目录 双向链表的储存结构示意图 双向链表的初始化结构 1.双向链表的结点 2.双向链表的头结点 3.总代码 双向链表中的指定文件插入元素 1.插入的为第一个位置 2.其他位置插入 总代码 双向链表的删除 1.删除第一个元素 2.删除其他位置元素 总代码 双向链表的储存结构示意图 双向链表的初始化结构 1.双向链表的结点 代码实现 //双向链表的结点,包含一个数据域,两个指针域 typedef struct DoublyNode { ElementType date; //数据域 struct
-
Java数据结构与算法之双向链表、环形链表及约瑟夫问题深入理解
目录 一.双向链表 二.环形链表及其应用:约瑟夫问题 环形链表图示 构建一个单向的环形链表思路 遍历环形链表 约瑟夫问题 一.双向链表 使用带head头的双向链表实现 - 水浒英雄排行榜管理单向链表的缺点分析: 单向链表,查找的方向只能是一个方向,而双向链表可以向前或者向后查找. 单向链表不能自我删除,需要靠辅助节点,而双向链表,则可以自我删除,所以前面我们单链表删除节点时,总是找到temp,temp时待删除节点的前一个节点(认真体会). 分析双向链表的遍历,添加,修改,删除的操作思路 1.遍历
-
带你了解Java数据结构和算法之链表
目录 1.链表(Linked List) 2.单向链表(Single-Linked List) ①.单向链表的具体实现 ②.用单向链表实现栈 4.双端链表 ①.双端链表的具体实现 ②.用双端链表实现队列 5.抽象数据类型(ADT) 6.有序链表 7.有序链表和无序数组组合排序 8.双向链表 9.总结 前面博客我们在讲解数组中,知道数组作为数据存储结构有一定的缺陷.在无序数组中,搜索性能差,在有序数组中,插入效率又很低,而且这两种数组的删除效率都很低,并且数组在创建后,其大小是固定了,设置的过大会
-
带你了解Java数据结构和算法之栈
目录 1.栈的基本概念 2.Java模拟简单的顺序栈实现 3.增强功能版栈 4.利用栈实现字符串逆序 5.利用栈判断分隔符是否匹配 6.总结 1.栈的基本概念 栈(英语:stack)又称为堆栈或堆叠,栈作为一种数据结构,是一种只能在一端进行插入和删除操作的特殊线性表.它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来).栈具有记忆作用,对栈的插入与删除操作中,不需要改变栈底指针. 栈是允许在同一端进行插入和删除操
-
带你了解Java数据结构和算法之数组
目录 1.Java数组介绍 ①.数组的声明 ②.访问数组元素以及给数组元素赋值 ③.数组遍历 2.用类封装数组实现数据结构 3.分析数组的局限性 4.总结 1.Java数组介绍 在Java中,数组是用来存放同一种数据类型的集合,注意只能存放同一种数据类型(Object类型数组除外). ①.数组的声明 第一种方式: 数据类型 [] 数组名称 = new 数据类型[数组长度]; 这里 [] 可以放在数组名称的前面,也可以放在数组名称的后面,我们推荐放在数组名称的前面,这样看上去 数据类型 [] 表示
-
带你了解Java数据结构和算法之二叉树
目录 1.树 2.二叉树 3.查找节点 4.插入节点 5.遍历树 6.查找最大值和最小值 7.删除节点 ①.删除没有子节点的节点 ②.删除有一个子节点的节点 ③.删除有两个子节点的节点 ④.删除有必要吗? 8.二叉树的效率 9.用数组表示树 10.完整的BinaryTree代码 11.哈夫曼(Huffman)编码 ①.哈夫曼编码 ②.哈夫曼解码 12.总结 1.树 树(tree)是一种抽象数据类型(ADT),用来模拟具有树状结构性质的数据集合.它是由n(n>0)个有限节点通过连接它们的边组成一个
-
带你了解Java数据结构和算法之无权无向图
目录 1.图的定义 ①.邻接: ②.路径: ③.连通图和非连通图: ④.有向图和无向图: ⑤.有权图和无权图: 2.在程序中表示图 ①.顶点: ②.边: 3.搜索 ①.深度优先搜索(DFS) ②.广度优先搜索(BFS) ③.程序实现 4.最小生成树 5.总结 1.图的定义 我们知道,前面讨论的数据结构都有一个框架,而这个框架是由相应的算法实现的,比如二叉树搜索树,左子树上所有结点的值均小于它的根结点的值,右子树所有结点的值均大于它的根节点的值,类似这种形状使得它容易搜索数据和插入数据,树的边表示
-
带你了解Java数据结构和算法之队列
目录 1.队列的基本概念 2.Java模拟单向队列实现 3.双端队列 4.优先级队列 5.总结 1.队列的基本概念 队列(queue)是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表.进行插入操作的端称为队尾,进行删除操作的端称为队头.队列中没有元素时,称为空队列. 队列的数据元素又称为队列元素.在队列中插入一个队列元素称为入队,从队列中删除一个队列元素称为出队.因为队列只允许在一端插入,在
-
带你了解Java数据结构和算法之递归
目录 1.递归的定义 2.求一个数的阶乘:n! 3.递归的二分查找 4.分治算法 5.汉诺塔问题 6.归并排序 7.消除递归 8.递归的有趣应用 ①.求一个数的乘方 ②.背包问题 ③.组合:选择一支队伍 9.总结 1.递归的定义 递归,就是在运行的过程中调用自己. 递归必须要有三个要素: ①.边界条件 ②.递归前进段 ③.递归返回段 当边界条件不满足时,递归前进:当边界条件满足时,递归返回. 2.求一个数的阶乘:n! 规定: ①.0!=1 ②.1!=1 ③.负数没有阶乘 上面的表达式我们先用fo
-
带你了解Java数据结构和算法之哈希表
目录 1.哈希函数的引入 ①.把数字相加 ②.幂的连乘 2.冲突 3.开放地址法 ①.线性探测 ②.装填因子 ③.二次探测 ④.再哈希法 4.链地址法 5.桶 6.总结 1.哈希函数的引入 大家都用过字典,字典的优点是我们可以通过前面的目录快速定位到所要查找的单词.如果我们想把一本英文字典的每个单词,从 a 到 zyzzyva(这是牛津字典的最后一个单词),都写入计算机内存,以便快速读写,那么哈希表是个不错的选择. 这里我们将范围缩小点,比如想在内存中存储5000个英文单词.我们可能想到每个单词
-
带你了解Java数据结构和算法之高级排序
目录 1.希尔排序 ①.直接插入排序 ②.希尔排序图解 ③.排序间隔选取 ④.knuth间隔序列的希尔排序算法实现 ⑤.间隔为2h的希尔排序 2.快速排序 ①.快速排序的基本思路 ②.快速排序的算法实现 ③.快速排序图示 ④.快速排序完整代码 ⑤.优化分析 总结 1.希尔排序 希尔排序是基于直接插入排序的,它在直接插入排序中增加了一个新特性,大大的提高了插入排序的执行效率.所以在讲解希尔排序之前,我们先回顾一下直接插入排序. ①.直接插入排序 直接插入排序基本思想是每一步将一个待排序的记录,插入
-
带你了解Java数据结构和算法之前缀,中缀和后缀表达式
目录 1.人如何解析算术表达式 ①.求值 3+4-5 ②.求值 3+4*5 2.计算机如何解析算术表达式 3.后缀表达式 ①.如何将中缀表达式转换为后缀表达式? 一.先自定义一个栈 二.前缀表达式转换为后缀表达式 三.测试 四.结果 五.分析 ②.计算机如何实现后缀表达式的运算? 4.前缀表达式 ①.如何将中缀表达式转换为前缀表达式? ②.计算机如何实现前缀表达式的运算? 总结 1.人如何解析算术表达式 如何解析算术表达式?或者换种说法,遇到某个算术表达式,我们是如何计算的: ①.求值 3+4-