Python机器学习应用之基于BP神经网络的预测篇详解
目录
- 一、Introduction
- 1 BP神经网络的优点
- 2 BP神经网络的缺点
- 二、实现过程
- 1 Demo
- 2 基于BP神经网络的乳腺癌分类预测
- 三、Keys
一、Introduction
1 BP神经网络的优点
- 非线性映射能力:BP神经网络实质上实现了一个从输入到输出的映射功能,数学理论证明三层的神经网络就能够以任意精度逼近任何非线性连续函数。这使得其特别适合于求解内部机制复杂的问题,即BP神经网络具有较强的非线性映射能力。
- 自学习和自适应能力:BP神经网络在训练时,能够通过学习自动提取输入、输出数据间的“合理规则”,并自适应地将学习内容记忆于网络的权值中。即BP神经网络具有高度自学习和自适应的能力。
- 泛化能力:所谓泛化能力是指在设计模式分类器时,即要考虑网络在保证对所需分类对象进行正确分类,还要关心网络在经过训练后,能否对未见过的模式或有噪声污染的模式,进行正确的分类。也即BP神经网络具有将学习成果应用于新知识的能力。
2 BP神经网络的缺点
- 局部极小化问题:从数学角度看,传统的 BP神经网络为一种局部搜索的优化方法,它要解决的是一个复杂非线性化问题,网络的权值是通过沿局部改善的方向逐渐进行调整的,这样会使算法陷入局部极值,权值收敛到局部极小点,从而导致网络训练失败。加上BP神经网络对初始网络权重非常敏感,以不同的权重初始化网络,其往往会收敛于不同的局部极小,这也是每次训练得到不同结果的根本原因
- BP 神经网络算法的收敛速度慢:由于BP神经网络算法本质上为梯度下降法,它所要优化的目标函数是非常复杂的,因此,必然会出现“锯齿形现象”,这使得BP算法低效;又由于优化的目标函数很复杂,它必然会在神经元输出接近0或1的情况下,出现一些平坦区,在这些区域内,权值误差改变很小,使训练过程几乎停顿;BP神经网络模型中,为了使网络执行BP算法,不能使用传统的一维搜索法求每次迭代的步长,而必须把步长的更新规则预先赋予网络,这种方法也会引起算法低效。以上种种,导致了BP神经网络算法收敛速度慢的现象。
- BP 神经网络结构选择不一:BP神经网络结构的选择至今尚无一种统一而完整的理论指导,一般只能由经验选定。网络结构选择过大,训练中效率不高,可能出现过拟合现象,造成网络性能低,容错性下降,若选择过小,则又会造成网络可能不收敛。而网络的结构直接影响网络的逼近能力及推广性质。因此,应用中如何选择合适的网络结构是一个重要的问题。
二、实现过程
1 Demo
#%% 基础数组运算库导入
import numpy as np
# 画图库导入
import matplotlib.pyplot as plt
# 导入三维显示工具
from mpl_toolkits.mplot3d import Axes3D
# 导入BP模型
from sklearn.neural_network import MLPClassifier
# 导入demo数据制作方法
from sklearn.datasets import make_classification
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import warnings
from sklearn.exceptions import ConvergenceWarning
#%%模型训练
# 制作五个类别的数据,每个类别1000个样本
train_samples, train_labels = make_classification(n_samples=1000, n_features=3,
n_redundant=0,n_classes=5, n_informative=3,
n_clusters_per_class=1,class_sep=3, random_state=10)
# 将五个类别的数据进行三维显示
fig = plt.figure()
ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=20, azim=20)
ax.scatter(train_samples[:, 0], train_samples[:, 1], train_samples[:, 2], marker='o', c=train_labels)
plt.title('Demo Data Map')

#%% 建立 BP 模型, 采用sgd优化器,relu非线性映射函数
BP = MLPClassifier(solver='sgd',activation = 'relu',max_iter = 500,alpha = 1e-3,
hidden_layer_sizes = (32,32),random_state = 1)
# 进行模型训练
with warnings.catch_warnings():
warnings.filterwarnings("ignore", category=ConvergenceWarning,
module="sklearn")
BP.fit(train_samples, train_labels)
# 查看 BP 模型的参数
print(BP)
#%% 进行模型预测
predict_labels = BP.predict(train_samples)
# 显示预测的散点图
fig = plt.figure()
ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=20, azim=20)
ax.scatter(train_samples[:, 0], train_samples[:, 1], train_samples[:, 2], marker='o', c=predict_labels)
plt.title('Demo Data Predict Map with BP Model')
# 显示预测分数
print("预测准确率: {:.4f}".format(BP.score(train_samples, train_labels)))
# 可视化预测数据
print("真实类别:", train_labels[:10])
print("预测类别:", predict_labels[:10])
# 准确率等报表
print(classification_report(train_labels, predict_labels))
# 计算混淆矩阵
classes = [0, 1, 2, 3]
cofusion_mat = confusion_matrix(train_labels, predict_labels, classes)
sns.set()
figur, ax = plt.subplots()
# 画热力图
sns.heatmap(cofusion_mat, cmap="YlGnBu_r", annot=True, ax=ax)
ax.set_title('confusion matrix') # 标题
ax.set_xticklabels([''] + classes, minor=True)
ax.set_yticklabels([''] + classes, minor=True)
ax.set_xlabel('predict') # x轴
ax.set_ylabel('true') # y轴
plt.show()


#%%# 进行新的测试数据测试
test_sample = np.array([[-1, 0.1, 0.1]])
print(f"{test_sample} 类别是: ", BP.predict(test_sample))
print(f"{test_sample} 类别概率分别是: ", BP.predict_proba(test_sample))
test_sample = np.array([[-1.2, 10, -91]])
print(f"{test_sample} 类别是: ", BP.predict(test_sample))
print(f"{test_sample} 类别概率分别是: ", BP.predict_proba(test_sample))
test_sample = np.array([[-12, -0.1, -0.1]])
print(f"{test_sample} 类别是: ", BP.predict(test_sample))
print(f"{test_sample} 类别概率分别是: ", BP.predict_proba(test_sample))
test_sample = np.array([[100, -90.1, -9.1]])
print(f"{test_sample} 类别是: ", BP.predict(test_sample))
print(f"{test_sample} 类别概率分别是: ", BP.predict_proba(test_sample))

2 基于BP神经网络的乳腺癌分类预测
#%%基于BP神经网络的乳腺癌分类
#基本库导入
# 导入乳腺癌数据集
from sklearn.datasets import load_breast_cancer
# 导入BP模型
from sklearn.neural_network import MLPClassifier
# 导入训练集分割方法
from sklearn.model_selection import train_test_split
# 导入预测指标计算函数和混淆矩阵计算函数
from sklearn.metrics import classification_report, confusion_matrix
# 导入绘图包
import seaborn as sns
import matplotlib.pyplot as plt
# 导入三维显示工具
from mpl_toolkits.mplot3d import Axes3D
# 导入乳腺癌数据集
cancer = load_breast_cancer()
# 查看数据集信息
print('breast_cancer数据集的长度为:',len(cancer))
print('breast_cancer数据集的类型为:',type(cancer))
# 分割数据为训练集和测试集
cancer_data = cancer['data']
print('cancer_data数据维度为:',cancer_data.shape)
cancer_target = cancer['target']
print('cancer_target标签维度为:',cancer_target.shape)
cancer_names = cancer['feature_names']
cancer_desc = cancer['DESCR']
#分为训练集与测试集
cancer_data_train,cancer_data_test = train_test_split(cancer_data,test_size=0.2,random_state=42)#训练集
cancer_target_train,cancer_target_test = train_test_split(cancer_target,test_size=0.2,random_state=42)#测试集

#%%# 建立 BP 模型, 采用Adam优化器,relu非线性映射函数
BP = MLPClassifier(solver='adam',activation = 'relu',max_iter = 1000,alpha = 1e-3,hidden_layer_sizes = (64,32, 32),random_state = 1)
# 进行模型训练
BP.fit(cancer_data_train, cancer_target_train)
#%% 进行模型预测
predict_train_labels = BP.predict(cancer_data_train)
# 可视化真实数据
fig = plt.figure()
ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=20, azim=20)
ax.scatter(cancer_data_train[:, 0], cancer_data_train[:, 1], cancer_data_train[:, 2], marker='o', c=cancer_target_train)
plt.title('True Label Map')
plt.show()
# 可视化预测数据
fig = plt.figure()
ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=20, azim=20)
ax.scatter(cancer_data_train[:, 0], cancer_data_train[:, 1], cancer_data_train[:, 2], marker='o', c=predict_train_labels)
plt.title('Cancer with BP Model')
plt.show()
#%% 显示预测分数
print("预测准确率: {:.4f}".format(BP.score(cancer_data_test, cancer_target_test)))
# 进行测试集数据的类别预测
predict_test_labels = BP.predict(cancer_data_test)
print("测试集的真实标签:\n", cancer_target_test)
print("测试集的预测标签:\n", predict_test_labels)
#%% 进行预测结果指标统计 统计每一类别的预测准确率、召回率、F1分数
print(classification_report(cancer_target_test, predict_test_labels))

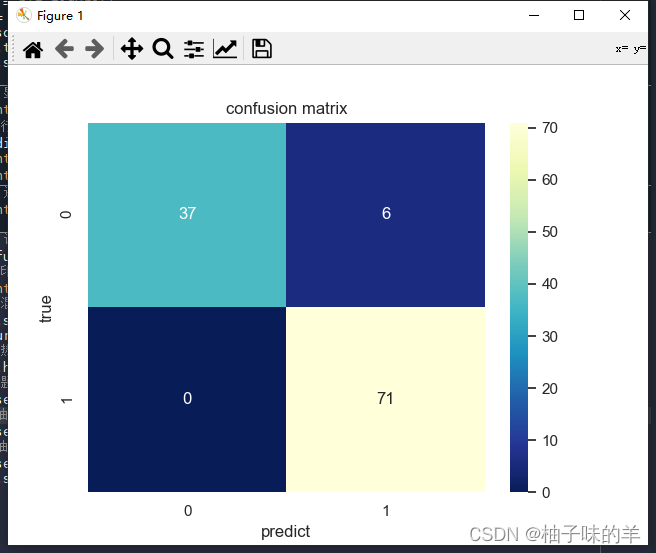
#%% 计算混淆矩阵
confusion_mat = confusion_matrix(cancer_target_test, predict_test_labels)
# 打印混淆矩阵
print(confusion_mat)
# 将混淆矩阵以热力图的方式显示
sns.set()
figure, ax = plt.subplots()
# 画热力图
sns.heatmap(confusion_mat, cmap="YlGnBu_r", annot=True, ax=ax)
# 标题
ax.set_title('confusion matrix')
# x轴为预测类别
ax.set_xlabel('predict')
# y轴实际类别
ax.set_ylabel('true')
plt.show()
注:之前还做过基于BP神经网络的人口普查数据预测,有需要的猿友私信
三、Keys
BP神经网络的要点在于前向传播和误差反向传播,来对参数进行更新,使得损失最小化。
它是一个迭代算法,基本思想是:
- 先计算每一层的状态和激活值,直到最后一层(即信号是前向传播的);
- 计算每一层的误差,误差的计算过程是从最后一层向前推进的(反向传播);
- 更新参数(目标是误差变小)。迭代前面两个步骤,直到满足停止准则(比如相邻两次迭代的误差的差别很小)。
886~~~
到此这篇关于Python机器学习应用之基于BP神经网络的预测篇详解的文章就介绍到这了,更多相关Python BP神经网络内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python机器学习之神经网络(一)
python有专门的神经网络库,但为了加深印象,我自己在numpy库的基础上,自己编写了一个简单的神经网络程序,是基于Rosenblatt感知器的,这个感知器建立在一个线性神经元之上,神经元模型的求和节点计算作用于突触输入的线性组合,同时结合外部作用的偏置,对若干个突触的输入求和后进行调节.为了便于观察,这里的数据采用二维数据. 目标函数是训练结果的误差的平方和,由于目标函数是一个二次函数,只存在一个全局极小值,所以采用梯度下降法的策略寻找目标函数的最小值. 代码如下: import numpy
-
python机器学习之神经网络(二)
由于Rosenblatt感知器的局限性,对于非线性分类的效果不理想.为了对线性分类无法区分的数据进行分类,需要构建多层感知器结构对数据进行分类,多层感知器结构如下: 该网络由输入层,隐藏层,和输出层构成,能表示种类繁多的非线性曲面,每一个隐藏层都有一个激活函数,将该单元的输入数据与权值相乘后得到的值(即诱导局部域)经过激活函数,激活函数的输出值作为该单元的输出,激活函数类似与硬限幅函数,但硬限幅函数在阈值处是不可导的,而激活函数处处可导.本次程序中使用的激活函数是tanh函数,公式如下: tan
-
python机器学习之神经网络(三)
前面两篇文章都是参考书本神经网络的原理,一步步写的代码,这篇博文里主要学习了如何使用neurolab库中的函数来实现神经网络的算法. 首先介绍一下neurolab库的配置: 选择你所需要的版本进行下载,下载完成后解压. neurolab需要采用python安装第三方软件包的方式进行安装,这里介绍一种安装方式: (1)进入cmd窗口 (2)进入解压文件所在目录下 (3)输入 setup.py install 这样,在python安装目录的Python27\Lib\site-packages下,就可
-
Python机器学习应用之基于天气数据集的XGBoost分类篇解读
目录 一.XGBoost 1 XGBoost的优点 2 XGBoost的缺点 二.实现过程 1 数据集 2 实现 三.Keys XGBoost的重要参数 一.XGBoost XGBoost并不是一种模型,而是一个可供用户轻松解决分类.回归或排序问题的软件包. 1 XGBoost的优点 简单易用.相对其他机器学习库,用户可以轻松使用XGBoost并获得相当不错的效果. 高效可扩展.在处理大规模数据集时速度快效果好,对内存等硬件资源要求不高. 鲁棒性强.相对于深度学习模型不需要精细调参便能取得接近的
-
python机器学习实现神经网络示例解析
目录 单神经元引论 参考 多神经元 单神经元引论 对于如花,大美,小明三个因素是如何影响小强这个因素的. 这里用到的是多元的线性回归,比较基础 from numpy import array,exp,dot,random 其中dot是点乘 导入关系矩阵: X= array ( [ [0,0,1],[1,1,1],[1,0,1],[0,1,1]]) y = array( [ [0,1,1,0]]).T ## T means "transposition" 为了满足0到1的可能性,我们采用
-
python机器学习之神经网络
手写数字识别算法 import pandas as pd import numpy as np from sklearn.neural_network import MLPRegressor #从sklearn的神经网络中引入多层感知器 data_tr = pd.read_csv('BPdata_tr.txt') # 训练集样本 data_te = pd.read_csv('BPdata_te.txt') # 测试集样本 X=np.array([[0.568928884039633],[0.37
-
python机器学习之神经网络实现
神经网络在机器学习中有很大的应用,甚至涉及到方方面面.本文主要是简单介绍一下神经网络的基本理论概念和推算.同时也会介绍一下神经网络在数据分类方面的应用. 首先,当我们建立一个回归和分类模型的时候,无论是用最小二乘法(OLS)还是最大似然值(MLE)都用来使得残差达到最小.因此我们在建立模型的时候,都会有一个loss function. 而在神经网络里也不例外,也有个类似的loss function. 对回归而言: 对分类而言: 然后同样方法,对于W开始求导,求导为零就可以求出极值来. 关于式子中
-
Python机器学习应用之基于LightGBM的分类预测篇解读
目录 一.Introduction 1 LightGBM的优点 2 LightGBM的缺点 二.实现过程 1 数据集介绍 2 Coding 三.Keys LightGBM的重要参数 基本参数调整 针对训练速度的参数调整 针对准确率的参数调整 针对过拟合的参数调整 一.Introduction LightGBM是扩展机器学习系统.是一款基于GBDT(梯度提升决策树)算法的分布梯度提升框架.其设计思路主要集中在减少数据对内存与计算性能的使用上,以及减少多机器并行计算时的通讯代价 1 LightGBM
-
Python机器学习应用之决策树分类实例详解
目录 一.数据集 二.实现过程 1 数据特征分析 2 利用决策树模型在二分类上进行训练和预测 3 利用决策树模型在多分类(三分类)上进行训练与预测 三.KEYS 1 构建过程 2 划分选择 3 重要参数 一.数据集 小企鹅数据集,提取码:1234 该数据集一共包含8个变量,其中7个特征变量,1个目标分类变量.共有150个样本,目标变量为 企鹅的类别 其都属于企鹅类的三个亚属,分别是(Adélie, Chinstrap and Gentoo).包含的三种种企鹅的七个特征,分别是所在岛屿,嘴巴长度,
-
Python机器学习应用之基于BP神经网络的预测篇详解
目录 一.Introduction 1 BP神经网络的优点 2 BP神经网络的缺点 二.实现过程 1 Demo 2 基于BP神经网络的乳腺癌分类预测 三.Keys 一.Introduction 1 BP神经网络的优点 非线性映射能力:BP神经网络实质上实现了一个从输入到输出的映射功能,数学理论证明三层的神经网络就能够以任意精度逼近任何非线性连续函数.这使得其特别适合于求解内部机制复杂的问题,即BP神经网络具有较强的非线性映射能力. 自学习和自适应能力:BP神经网络在训练时,能够通过学习自动提取输
-
Python机器学习pytorch模型选择及欠拟合和过拟合详解
目录 训练误差和泛化误差 模型复杂性 模型选择 验证集 K折交叉验证 欠拟合还是过拟合? 模型复杂性 数据集大小 训练误差和泛化误差 训练误差是指,我们的模型在训练数据集上计算得到的误差. 泛化误差是指,我们将模型应用在同样从原始样本的分布中抽取的无限多的数据样本时,我们模型误差的期望. 在实际中,我们只能通过将模型应用于一个独立的测试集来估计泛化误差,该测试集由随机选取的.未曾在训练集中出现的数据样本构成. 模型复杂性 在本节中将重点介绍几个倾向于影响模型泛化的因素: 可调整参数的数量.当可调
-
Python机器学习算法库scikit-learn学习之决策树实现方法详解
本文实例讲述了Python机器学习算法库scikit-learn学习之决策树实现方法.分享给大家供大家参考,具体如下: 决策树 决策树(DTs)是一种用于分类和回归的非参数监督学习方法.目标是创建一个模型,通过从数据特性中推导出简单的决策规则来预测目标变量的值. 例如,在下面的例子中,决策树通过一组if-then-else决策规则从数据中学习到近似正弦曲线的情况.树越深,决策规则越复杂,模型也越合适. 决策树的一些优势是: 便于说明和理解,树可以可视化表达: 需要很少的数据准备.其他技术通常需要
-
Python机器学习应用之基于决策树算法的分类预测篇
目录 一.决策树的特点 1.优点 2.缺点 二.决策树的适用场景 三.demo 一.决策树的特点 1.优点 具有很好的解释性,模型可以生成可以理解的规则. 可以发现特征的重要程度. 模型的计算复杂度较低. 2.缺点 模型容易过拟合,需要采用减枝技术处理. 不能很好利用连续型特征. 预测能力有限,无法达到其他强监督模型效果. 方差较高,数据分布的轻微改变很容易造成树结构完全不同. 二.决策树的适用场景 决策树模型多用于处理自变量与因变量是非线性的关系. 梯度提升树(GBDT),XGBoost以及L
-
Python机器学习应用之基于线性判别模型的分类篇详解
目录 一.Introduction 1 LDA的优点 2 LDA的缺点 3 LDA在模式识别领域与自然语言处理领域的区别 二.Demo 三.基于LDA 手写数字的分类 四.小结 一.Introduction 线性判别模型(LDA)在模式识别领域(比如人脸识别等图形图像识别领域)中有非常广泛的应用.LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的.这点和PCA不同.PCA是不考虑样本类别输出的无监督降维技术. LDA的思想可以用一句话概括,就是"投影后类内方差最小,类间方
-
Python深度学习pytorch神经网络图像卷积运算详解
目录 互相关运算 卷积层 特征映射 由于卷积神经网络的设计是用于探索图像数据,本节我们将以图像为例. 互相关运算 严格来说,卷积层是个错误的叫法,因为它所表达的运算其实是互相关运算(cross-correlation),而不是卷积运算.在卷积层中,输入张量和核张量通过互相关运算产生输出张量. 首先,我们暂时忽略通道(第三维)这一情况,看看如何处理二维图像数据和隐藏表示.下图中,输入是高度为3.宽度为3的二维张量(即形状为 3 × 3 3\times3 3×3).卷积核的高度和宽度都是2. 注意,
-
基于Python中单例模式的几种实现方式及优化详解
单例模式 单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在.当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场. 比如,某个服务器程序的配置信息存放在一个文件中,客户端通过一个 AppConfig 的类来读取配置文件的信息.如果在程序运行期间,有很多地方都需要使用配置文件的内容,也就是说,很多地方都需要创建 AppConfig 对象的实例,这就导致系统中存在多个 AppConfig 的实例对象,而这样会严重浪
-
基于Python的接口自动化unittest测试框架和ddt数据驱动详解
引言 在编写接口自动化用例时,我们一般针对一个接口建立一个.py文件,一条接口测试用例封装为一个函数(方法),但是在批量执行的过程中,如果其中一条出错,后面的用例就无法执行,还有在运行大量的接口测试用例时测试数据如何管理和加载.针对测试用例加载以及执行控制,python语言提供了unittest单元测试框架,将测试用例编写在unittest框架下,使用该框架可以单个或者批量加载互不影响的用例执行及更灵活的执行控制,对于更好的进行测试数据的管理和加载,这里我们引入数据驱动的模块:ddt,测试数据和