Java Tree结构数据中查找匹配节点方式
我就废话不多说了,大家还是直接看代码吧~
private boolean contains(List<TreeVo> children, String value) {
for (TreeVo child : children) {
if (child.getName().equals(value) || (child.getChildren().size() > 0 && contains(child.getChildren(), value))) {
return true;
}
}
return false;
}
补充知识:java树形结构根据父级节点获取其下面的所有最底层的根节点数据
因工作中需要根据任意父级节点查找到树形节点下的根节点信息,所以写了下面一个demo方便自己需要时的查看以及需要的人参考
一共两个类
TreeNode 使用了lombok插件
TreeNodeTest
主要的逻辑都在TreeNodeTest中 如果有错误的地方,还望留言评论,感谢
TreeNode
@Data
@AllArgsConstructor
public class TreeNode {
/**
* 节点ID
**/
private String id;
/**
* 父级ID
**/
private String parentId;
/**
* 节点名称
**/
private String name;
}
TreeNodeTest
/**
* 测试类
* 此方法建议数据量少的情况使用 或者 此数据很少变动并且加入到缓存中
*/
public class TreeNodeTest {
public static void main(String[] args) {
/**
* 0
* / \
* 123 130
* / \ / \
* 124 125 131 132
* / \ / \ / \ / \
* 126 127 128 129 133 134 135 136
* 只支持 节点路径长度必须一致的情况下才可以
* 此Demo可以实现 根据0 获取到[126 127 128 129 133 134 135 136]
* 根据123 获取到[126 127 128 129]
* 注:比如 126 127节点没有 此时获取到的0根节点 就会出现 [124 128 129 133 134 135 136]
*/
TreeNode treeNode = new TreeNode("123","0","北京");
TreeNode treeNode1 = new TreeNode("124","123","丰台区");
TreeNode treeNode2 = new TreeNode("125","123","海淀区");
TreeNode treeNode3 = new TreeNode("126","124","丰台区丰台科技园");
TreeNode treeNode4 = new TreeNode("127","124","丰台区丰台南路");
TreeNode treeNode5 = new TreeNode("128","125","海淀区中关村");
TreeNode treeNode6 = new TreeNode("129","125","海淀区海淀公园");
TreeNode treeNode7 = new TreeNode("130","0","上海");
TreeNode treeNode8 = new TreeNode("131","130","徐汇区");
TreeNode treeNode9 = new TreeNode("132","130","虹口区");
TreeNode treeNode10 = new TreeNode("133","131","徐汇区龙华寺");
TreeNode treeNode11 = new TreeNode("134","131","徐汇区天主教堂");
TreeNode treeNode12 = new TreeNode("135","132","虹口区虹口足球场");
TreeNode treeNode13 = new TreeNode("136","132","虹口区鲁迅公园");
List<TreeNode> treeNodes = new LinkedList<>();
treeNodes.add(treeNode);
treeNodes.add(treeNode1);
treeNodes.add(treeNode2);
treeNodes.add(treeNode3);
treeNodes.add(treeNode4);
treeNodes.add(treeNode5);
treeNodes.add(treeNode6);
treeNodes.add(treeNode7);
treeNodes.add(treeNode8);
treeNodes.add(treeNode9);
treeNodes.add(treeNode10);
treeNodes.add(treeNode11);
treeNodes.add(treeNode12);
treeNodes.add(treeNode13);
// 按照父级ID分组
Map<String,List<TreeNode>> groupByParentIdMap = treeNodes.stream()
.collect(Collectors.groupingBy(TreeNode::getParentId));
// 存放 0:对应的所有根节点ID数据
Set<String> topToLowerChildIdSet = new HashSet<>();
// 取出顶级数据(也就是父级ID为0的数据 当然顶层的父级ID也可以自定义 这里只是演示 所以给了0)
List<TreeNode> topTreeNodes = groupByParentIdMap.get("0");
for(TreeNode node : topTreeNodes){
getMinimumChildIdArray(groupByParentIdMap,node.getId(),topToLowerChildIdSet);
}
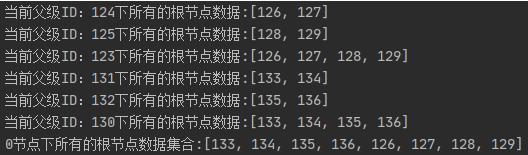
System.out.println("0节点下所有的根节点数据集合:" + topToLowerChildIdSet.toString());
}
/**
* 根据父级节点获取最低层次 那一级的节点数据
* 1
* / \
* 2 3
* / \ / \
* 4 5 6 7
* 上面的树形结构调用此方法 根据1 可以获取到 [4 5 6 7]
* 根据3 可以获得到 [6 7]
* @param groupByParentIdMap 所有的元素集合(根据父级ID进行了分组) 分组方法可以使用lambda 如下:
* Map<String, List<Person>> peopleByCity = personStream.collect(Collectors.groupingBy(Person::getCity));
* @param pid 父级ID
* @param topToLowerChildIdSet 存储最深根节点的数据集合
*/
public static Set<String> getMinimumChildIdArray(Map<String,List<TreeNode>> groupByParentIdMap,
String pid, Set<String> topToLowerChildIdSet){
// 存放当前pid对应的所有根节点ID数据
Set<String> currentPidLowerChildIdSet = new HashSet<>();
// 获取当前pid下所有的子节点
List<TreeNode> childTreeNodes = groupByParentIdMap.get(pid);
if(CollUtil.isEmpty(childTreeNodes)){
return null;
}
for(TreeNode treeNode : childTreeNodes){
Set<String> lowerChildIdSet = getMinimumChildIdArray(groupByParentIdMap,treeNode.getId(),currentPidLowerChildIdSet);
if(CollUtil.isEmpty(lowerChildIdSet)){
// 如果返回null 表示当前遍历的treeNode节点为最底层的节点
currentPidLowerChildIdSet.add(treeNode.getId());
}
}
System.out.println("当前父级ID:"+ pid + "下所有的根节点数据:" + currentPidLowerChildIdSet.toString());
// 把当前获取到的根节点数据 一并保存到上一个节点父级ID集合中
topToLowerChildIdSet.addAll(currentPidLowerChildIdSet);
return currentPidLowerChildIdSet;
}
}
运行后的结果:
以上这篇Java Tree结构数据中查找匹配节点方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Java二分法查找_动力节点Java学院整理
算法 假如有一组数为3,12,24,36,55,68,75,88要查给定的值24.可设三个变量front,mid,end分别指向数据的上界,中间和下界,mid=(front+end)/2. 开始令front=0(指向3),end=7(指向88),则mid=3(指向36).因为mid>x,故应在前半段中查找. 令新的end=mid-1=2,而front=0不变,则新的mid=1.此时x>mid,故确定应在后半段中查找. 令新的front=mid+1=2,而end=2不变,则新的mid=2,此时a
-
Java实现双链表互相交换任意两个节点的方法示例
本文实例讲述了Java实现双链表互相交换任意两个节点的方法.分享给大家供大家参考,具体如下: 概述: 双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱.所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点.一般我们都构造双向循环链表. 思路: 1.确定两个节点的先后顺序 2.next.prev互相交换顺序以及将换向前方的节点与之前的节点对接.(1.prev.next = 2) 3.判断是否相邻 实现代码: 链表类: publi
-
Java list如何根据id获取子节点
工作中因业务需求,将数据库中的树状结构的数据根据父节点获取所有的子节点 实现思路 1.获取整个数据的list集合数据 2.将数据分组,java8 list有groupby分组,java8之前的自己遍历整理 3.分组后递归获取子节点,有子节点的添加,没有的设置子节点并删除分组的数据,知道分组数据删完 Tree.java @Data public class Tree { private Integer id; private Integer pId; private String key; pri
-
JavaApi实现更新删除及读取节点
1.更新 同步方式: /** * 三个参数 * the path of the node * the data to set * the expected matching version */ Stat stat = zooKeeper.setData("/set/node1", "NODE1".getBytes(), 1); 返回值Stat中封装了set命令中的返回值,可以通过Stat的各种get方法去获取. 异步方式: zooKeeper.setData(&q
-
Java通过XPath获取XML文件中符合特定条件的节点
在Java解析XML文件的过程中,有时需要获取符合某些特定条件的节点,以下是实现代码. import javax.xml.xpath.XPath; import javax.xml.xpath.XPathConstants; import javax.xml.xpath.XPathExpressionException; import javax.xml.xpath.XPathFactory; import org.eclipse.swt.widgets.Shell; import org.ec
-
Java输出链表倒数第k个节点
问题描述 输入一个链表,输出该链表中倒数第k个结点.(尾结点是倒数第一个) 结点定义如下: public class ListNode { int val; ListNode next = null; ListNode(int val) { this.val = val; } } 思路1: 先遍历链表,计算其长度length; 然后计算出倒数第k个结点就是正数第length - k + 1. 最后再遍历链表,找到所求结点 时间复杂度O(2n),需要遍历两次链表 代码如下: public List
-
Java Tree结构数据中查找匹配节点方式
我就废话不多说了,大家还是直接看代码吧~ private boolean contains(List<TreeVo> children, String value) { for (TreeVo child : children) { if (child.getName().equals(value) || (child.getChildren().size() > 0 && contains(child.getChildren(), value))) { return t
-
list转tree和list中查找某节点下的所有数据操作
类的实例化顺序 父类静态变量. 父类静态代码块. 子类静态变量. 子类静态代码块. 父类非静态变量(父类实例成员变量). 父类构造函数. 子类非静态变量(子类实例成员变量). 子类构造函数. 已知组织类Org{String id,String name,String parentId},现在一List<Org>中存放无序的Org数据,求一个组织id下的所有组织. public static List<Org> childList=new ArrayList<>(); p
-

Java基于正则表达式实现查找匹配的文本功能【经典实例】
本文实例讲述了Java基于正则表达式实现查找匹配的文本功能.分享给大家供大家参考,具体如下: REMatch.java: package reMatch; import java.util.regex.Matcher; import java.util.regex.Pattern; /** * Created by Frank */ public class REMatch { public static void main(String[] args) { String patt = "Q[^
-
Java下3中XML解析 DOM方式、SAX方式和StAX方式
先简单说下前三种方式: DOM方式:个人理解类似.net的XmlDocument,解析的时候效率不高,占用内存,不适合大XML的解析:SAX方式:基于事件的解析,当解析到xml的某个部分的时候,会触发特定事件,可以在自定义的解析类中定义当事件触发时要做得事情:个人感觉一种很另类的方式,不知道.Net体系下是否有没有类似的方式?StAX方式:个人理解类似.net的XmlReader方式,效率高,占用内存少,适用大XML的解析:不过SAX方式之前也用过,本文主要介绍JAXB,这里只贴下主要代码: 复
-
Java Pattern和Matcher字符匹配方式
目录 Pattern类定义 因此,典型的调用顺序是: Pattern类方法详解 Pattern类使用示例: Matcher类定义 Matcher类方法详解 1.Matcher类提供了三个匹配操作方法 2.返回匹配器的显示状态 3.int start(),int end(),int group()均有一个重载方法 4.Matcher类同时提供了四个将匹配子串替换成指定字符串的方法: 5.其他一些方法: 应用实例 Pattern类定义 public final class Pattern exten
-
Java/Js下使用正则表达式匹配嵌套Html标签
通用 HTML 标签区配正则 最近看网站日志,发现有人在博客上转了我不知道几年前写的一个匹配 HTML 标签的正则,刚好最近也在做一些相关的事情,顿时来了兴趣.就拿回来改改,成了下面这样,可能会有一些 case 遗漏,欢迎修改,已知在内嵌 <script> 复杂内容的处理能力较弱,不过对纯 HTML 来说已经够用,拿来做一些分析工具还是不错滴. 复制代码 代码如下: <script type="text/javascript"> var str = "
-
Java concurrency集合之ConcurrentSkipListMap_动力节点Java学院整理
ConcurrentSkipListMap介绍 ConcurrentSkipListMap是线程安全的有序的哈希表,适用于高并发的场景. ConcurrentSkipListMap和TreeMap,它们虽然都是有序的哈希表.但是,第一,它们的线程安全机制不同,TreeMap是非线程安全的,而ConcurrentSkipListMap是线程安全的.第二,ConcurrentSkipListMap是通过跳表实现的,而TreeMap是通过红黑树实现的. 关于跳表(Skip List),它是平衡树的一种
-
Java中map内部存储方式解析
Map,即映射,也称为 键值对,有一个 Key, 一个 Value . 比如 Groovy 语言中, def map = ['name' : 'liudehua', 'age' : 50 ] ,则 map[ 'name' ] 的值是 'liudehua'. 那么 Map 内部存储是怎么实现的呢? 下面慢慢讲解. 一. 使用 拉链式存储 这个以 Java 中的 HashMap 为例进行讲解. HashMap 的内部有个数组 Entry[] table, 这个数组就是存放数据的. E
-
java编程中拷贝数组的方式及相关问题分析
JAVA数组的复制是引用传递,而并不是其他语言的值传递. 这里介绍java数组复制的4种方式极其问题: 第一种方式利用for循环: int[] a={1,2,4,6}; int length=a.length; int[] b=new int[length]; for (int i = 0; i < length; i++) { b[i]=a[i]; } 第二种方式直接赋值: int[] array1={1,2,4,6}; int[] array2=a; 这里把array1数组的值复制给arra
-
java理论基础Stream元素的匹配与查找
目录 一.对比一下有多简单 二.其他匹配规则函数介绍 三.元素查找与Optional 在我们对数组或者集合类进行操作的时候,经常会遇到这样的需求,比如: 是否包含某一个“匹配规则”的元素 是否所有的元素都符合某一个“匹配规则” 是否所有元素都不符合某一个“匹配规则” 查找第一个符合“匹配规则”的元素 查找任意一个符合“匹配规则”的元素 这些需求如果用for循环去写的话,还是比较麻烦的,需要使用到for循环和break!本节就介绍一个如何用Stream API来实现“查找与匹配”. 一.对比一下有