Python如何爬取51cto数据并存入MySQL
实验环境
1.安装Python 3.7
2.安装requests, bs4,pymysql 模块
实验步骤1.安装环境及模块
可参考https://www.jb51.net/article/194104.htm
2.编写代码
# 51cto 博客页面数据插入mysql数据库
# 导入模块
import re
import bs4
import pymysql
import requests
# 连接数据库账号密码
db = pymysql.connect(host='172.171.13.229',
user='root', passwd='abc123',
db='test', port=3306,
charset='utf8')
# 获取游标
cursor = db.cursor()
def open_url(url):
# 连接模拟网页访问
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/57.0.2987.98 Safari/537.36'}
res = requests.get(url, headers=headers)
return res
# 爬取网页内容
def find_text(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
# 博客名
titles = []
targets = soup.find_all("a", class_="tit")
for each in targets:
each = each.text.strip()
if "置顶" in each:
each = each.split(' ')[0]
titles.append(each)
# 阅读量
reads = []
read1 = soup.find_all("p", class_="read fl on")
read2 = soup.find_all("p", class_="read fl")
for each in read1:
reads.append(each.text)
for each in read2:
reads.append(each.text)
# 评论数
comment = []
targets = soup.find_all("p", class_='comment fl')
for each in targets:
comment.append(each.text)
# 收藏
collects = []
targets = soup.find_all("p", class_='collect fl')
for each in targets:
collects.append(each.text)
# 发布时间
dates=[]
targets = soup.find_all("a", class_='time fl')
for each in targets:
each = each.text.split(':')[1]
dates.append(each)
# 插入sql 语句
sql = """insert into blog (blog_title,read_number,comment_number, collect, dates)
values( '%s', '%s', '%s', '%s', '%s');"""
# 替换页面 \xa0
for titles, reads, comment, collects, dates in zip(titles, reads, comment, collects, dates):
reads = re.sub('\s', '', reads)
comment = re.sub('\s', '', comment)
collects = re.sub('\s', '', collects)
cursor.execute(sql % (titles, reads, comment, collects,dates))
db.commit()
pass
# 统计总页数
def find_depth(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
depth = soup.find('li', class_='next').previous_sibling.previous_sibling.text
return int(depth)
# 主函数
def main():
host = "https://blog.51cto.com/13760351"
res = open_url(host) # 打开首页链接
depth = find_depth(res) # 获取总页数
# 爬取其他页面信息
for i in range(1, depth + 1):
url = host + '/p' + str(i) # 完整链接
res = open_url(url) # 打开其他链接
find_text(res) # 爬取数据
# 关闭游标
cursor.close()
# 关闭数据库连接
db.close()
if __name__ == '__main__':
main()
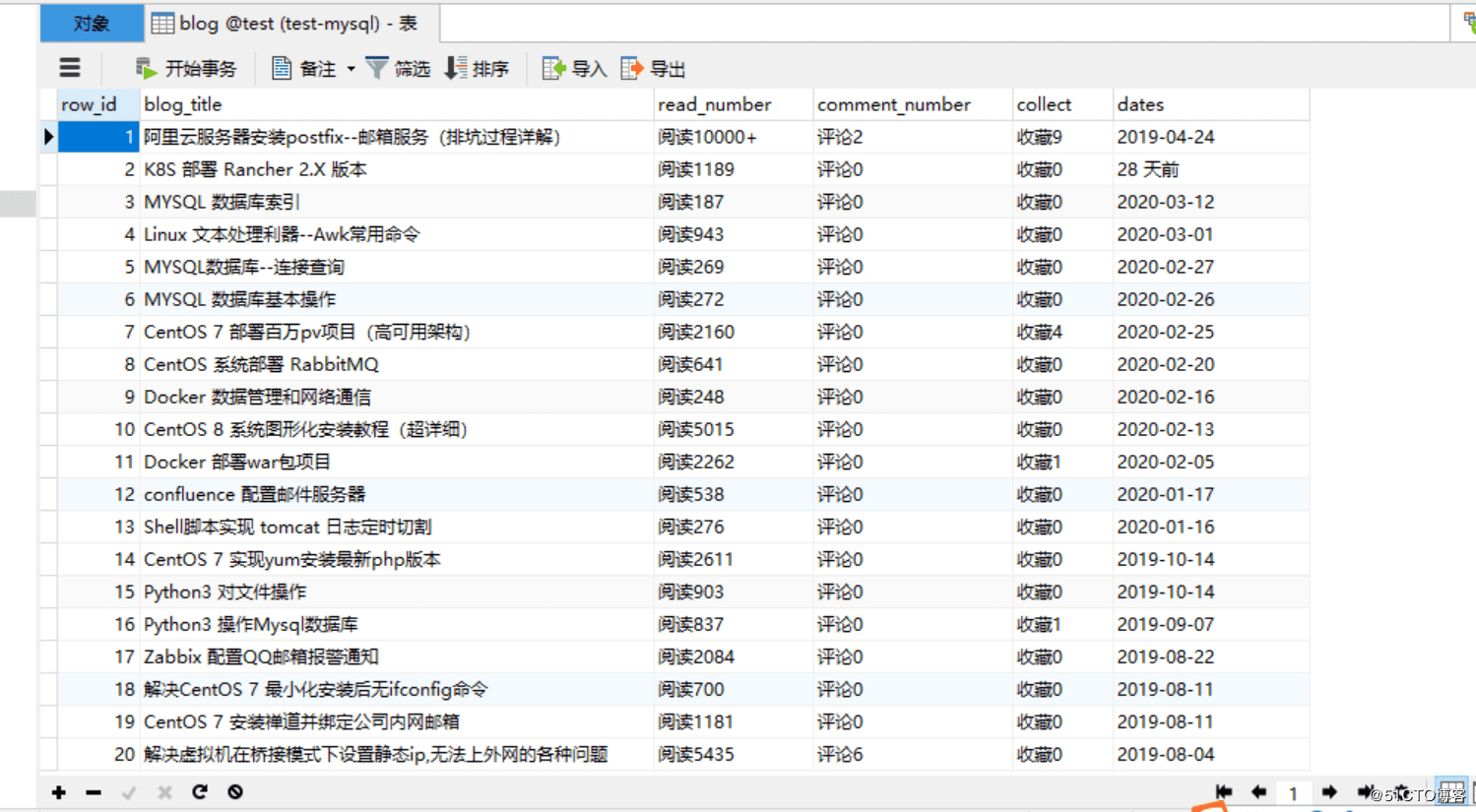
3..MySQL创建对应的表
CREATE TABLE `blog` ( `row_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `blog_title` varchar(52) DEFAULT NULL COMMENT '博客标题', `read_number` varchar(26) DEFAULT NULL COMMENT '阅读数量', `comment_number` varchar(16) DEFAULT NULL COMMENT '评论数量', `collect` varchar(16) DEFAULT NULL COMMENT '收藏数量', `dates` varchar(16) DEFAULT NULL COMMENT '发布日期', PRIMARY KEY (`row_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;

4.运行代码,查看效果:
改进版:
改进内容:
1.数据库里面的某些字段只保留数字即可
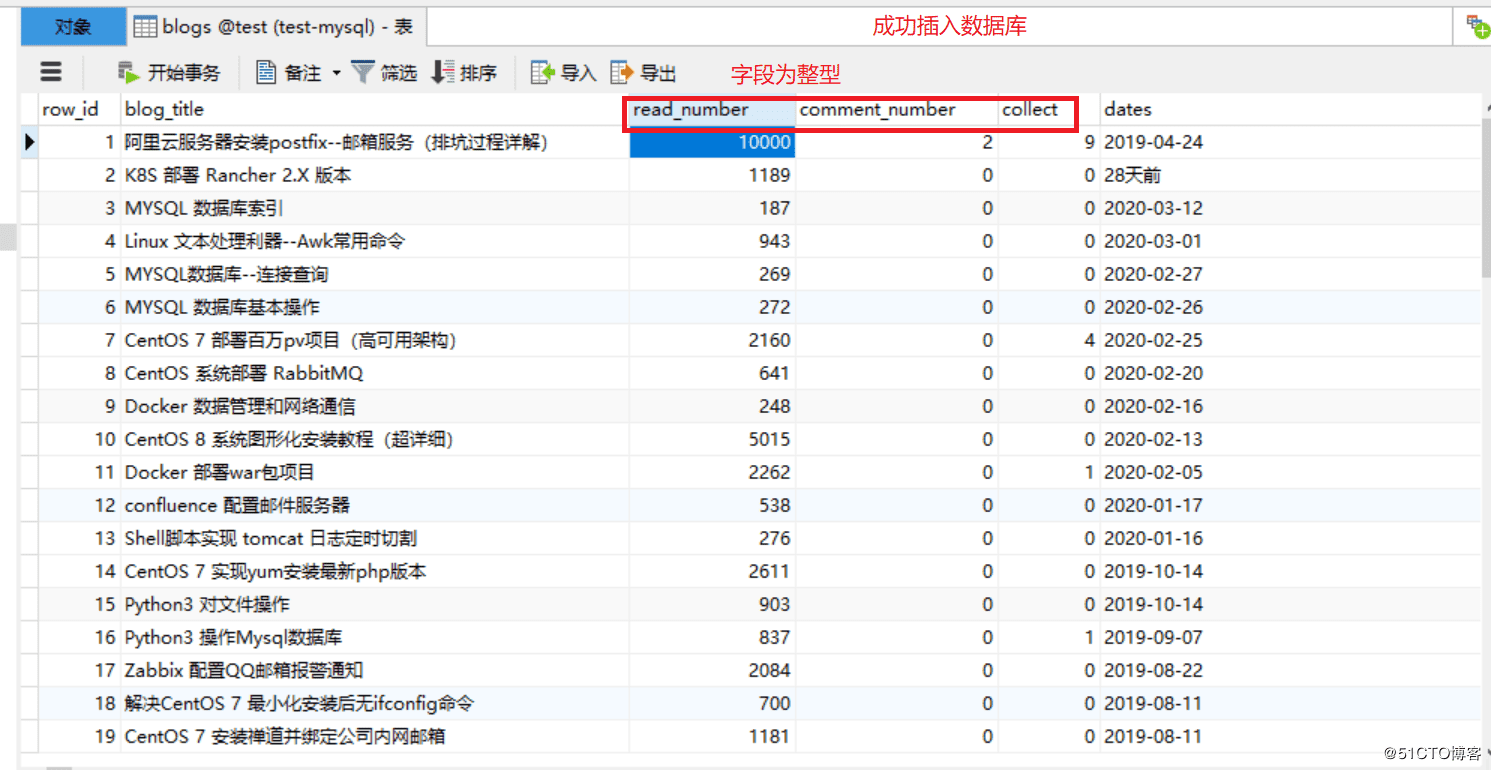
2.默认爬取的内容都是字符串,存放数据库的某些字段,最好改为整型,方便后面数据库操作
1.代码如下:
import re
import bs4
import pymysql
import requests
# 连接数据库
db = pymysql.connect(host='172.171.13.229',
user='root', passwd='abc123',
db='test', port=3306,
charset='utf8')
# 获取游标
cursor = db.cursor()
def open_url(url):
# 连接模拟网页访问
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/57.0.2987.98 Safari/537.36'}
res = requests.get(url, headers=headers)
return res
# 爬取网页内容
def find_text(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
# 博客标题
titles = []
targets = soup.find_all("a", class_="tit")
for each in targets:
each = each.text.strip()
if "置顶" in each:
each = each.split(' ')[0]
titles.append(each)
# 阅读量
reads = []
read1 = soup.find_all("p", class_="read fl on")
read2 = soup.find_all("p", class_="read fl")
for each in read1:
reads.append(each.text)
for each in read2:
reads.append(each.text)
# 评论数
comment = []
targets = soup.find_all("p", class_='comment fl')
for each in targets:
comment.append(each.text)
# 收藏
collects = []
targets = soup.find_all("p", class_='collect fl')
for each in targets:
collects.append(each.text)
# 发布时间
dates=[]
targets = soup.find_all("a", class_='time fl')
for each in targets:
each = each.text.split(':')[1]
dates.append(each)
# 插入sql 语句
sql = """insert into blogs (blog_title,read_number,comment_number, collect, dates)
values( '%s', '%s', '%s', '%s', '%s');"""
# 替换页面 \xa0
for titles, reads, comment, collects, dates in zip(titles, reads, comment, collects, dates):
reads = re.sub('\s', '', reads)
reads=int(re.sub('\D', "", reads)) #匹配数字,转换为整型
comment = re.sub('\s', '', comment)
comment = int(re.sub('\D', "", comment)) #匹配数字,转换为整型
collects = re.sub('\s', '', collects)
collects = int(re.sub('\D', "", collects)) #匹配数字,转换为整型
dates = re.sub('\s', '', dates)
cursor.execute(sql % (titles, reads, comment, collects,dates))
db.commit()
pass
# 统计总页数
def find_depth(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
depth = soup.find('li', class_='next').previous_sibling.previous_sibling.text
return int(depth)
# 主函数
def main():
host = "https://blog.51cto.com/13760351"
res = open_url(host) # 打开首页链接
depth = find_depth(res) # 获取总页数
# 爬取其他页面信息
for i in range(1, depth + 1):
url = host + '/p' + str(i) # 完整链接
res = open_url(url) # 打开其他链接
find_text(res) # 爬取数据
# 关闭游标
cursor.close()
# 关闭数据库连接
db.close()
#主程序入口
if __name__ == '__main__':
main()
2.创建对应表
CREATE TABLE `blogs` ( `row_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `blog_title` varchar(52) DEFAULT NULL COMMENT '博客标题', `read_number` int(26) DEFAULT NULL COMMENT '阅读数量', `comment_number` int(16) DEFAULT NULL COMMENT '评论数量', `collect` int(16) DEFAULT NULL COMMENT '收藏数量', `dates` varchar(16) DEFAULT NULL COMMENT '发布日期', PRIMARY KEY (`row_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
3.运行代码,验证
升级版
为了能让小白就可以使用这个程序,可以把这个项目打包成exe格式的文件,让其他人,使用电脑就可以运行代码,这样非常方便!
1.改进代码:
#末尾修改为:
if __name__ == '__main__':
main()
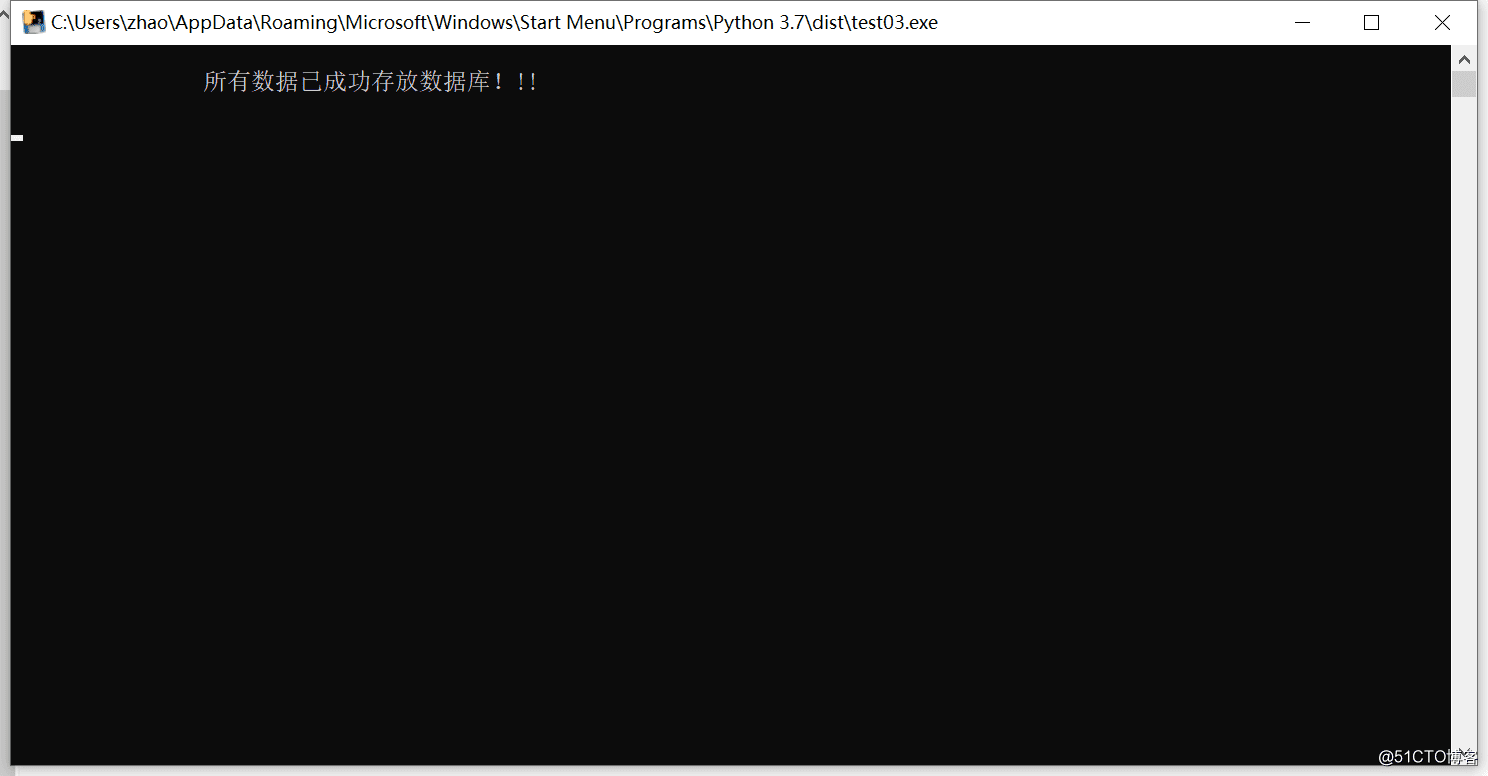
print("\n\t\t所有数据已成功存放数据库!!! \n")
time.sleep(5)
2.安装打包模块pyinstaller(cmd安装)
pip install pyinstaller -i https://pypi.tuna.tsinghua.edu.cn/simple/
3.Python代码打包
1.切换到需要打包代码的路径下面
2.在cmd窗口运行 pyinstaller -F test03.py (test03为项目名称)
4.查看exe包
在打包后会出现dist目录,打好包就在这个目录里面

5.运行exe包,查看效果
检查数据库
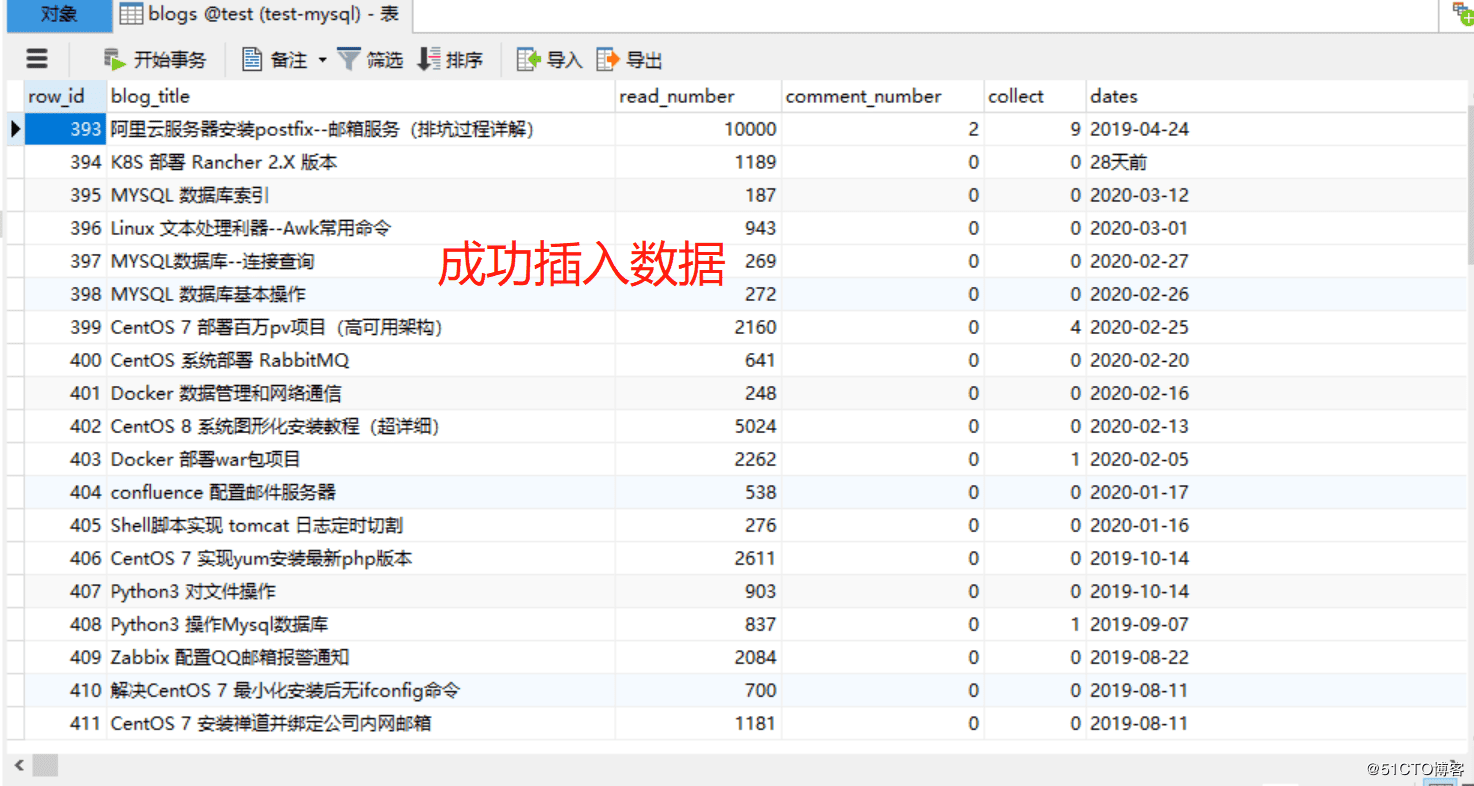
总结:
1.这一篇博客,是在上一篇的基础上改进的,步骤是先爬取首页的信息,再爬取其他页面信息,最后在改进细节,打包exe文件
2.我们爬取网页数据大多数还是存放到数据库的,所以这种方法很实用。
3.其实在此博客的基础上还是可以改进的,重要的是掌握方法即可。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python+PyQt5+MySQL实现天气管理系统
在本篇博客中,我利用Python语言其编写界面库PyQt5,然后通过连接MySQL数据库,实现了一个简单的天气管理小系统,该系统包含简单的增删查改四个主要功能.本文旨在解析实现的程序,能够让读者快速了解PyQt5图形界面库,然后可以初步实现这样一个小的系统程序. PyQt5简介 PyQt5本身来自C++的界面库Qt,经过一系列的封装移植到Python里面,作为Python的一个图像界面库,它继承了Python语言简单易实现的特点,可以实现基本的界面效果.里面有许多类实现了我们想要的窗体.表格.文
-
Python连接mysql数据库及简单增删改查操作示例代码
1.安装pymysql 进入cmd,输入 pip install pymysql: 2.数据库建表 在数据库中,建立一个简单的表,如图: 3.简单操作 3.1查询操作 #coding=utf-8 #连接数据库测试 import pymysql #打开数据库 db = pymysql.connect(host="localhost",user="root",password="root",db="test") #使用cursor
-
python mysql中in参数化说明
第一种:拼接字符串,可以解决问题,但是为了避免sql注入,不建议这样写 还是看看第二种:使用.format()函数,很多时候我都是使用这个函数来对sql参数化的 举个例子: select * from XX where id in (1,2,3) 参数化in里面的值: select * from XX where id in ({}).format('1,2,3') 你可以打印下看看,和你原来的sql是一模一样的 补充知识:python与mysql交互/读取本地配置文件/交互报错 如果自己写my
-
Python连接Mysql进行增删改查的示例代码
Python连接Mysql 1.安装对应的库 使用Python连接Mysql数据库需要安装相应的库 以管理员身份运行cmd,输入命令 pip install mysql.connector 安装完成后建立 test.py 写入 import mysql.connector 保存后运行 python test.py 用以测试模块库是否安装完成,如果不报错,说明安装完成 2.进行连接测试 编写connectTest.py文件 文件内容: import mysql.connector connect
-
Python定时从Mysql提取数据存入Redis的实现
设计思路: 1.程序一旦run起来,python会把mysql中最近一段时间的数据全部提取出来 2.然后实例化redis类,将数据简单解析后逐条传入redis队列 3.定时器设计每天凌晨12点开始跑 ps:redis是个内存数据库,做后台消息队列的缓存时有很大的用处,有兴趣的小伙伴可以去查看相关的文档. # -*- coding:utf-8 -*- import MySQLdb import schedule import time import datetime import random i
-
python pymysql链接数据库查询结果转为Dataframe实例
我就废话不多说了,大家还是直接看代码吧! import pymysql import pandas as pd def con_sql(db,sql): # 创建连接 db = pymysql.connect(host='127.0.0.1', port=3308, user='name', passwd='password', db=db, charset='utf8') # 创建游标 cursor = db.cursor() cursor.execute(sql) result = curs
-
利用python对mysql表做全局模糊搜索并分页实例
在写django项目的时候,有的数据没有使用模型管理(数据表是动态添加的),所以要直接使用mysql.前端请求数据的时候可能会指定这几个参数:要请求的页号,页大小,以及检索条件. """ tableName: 表名 pageNum: 请求的页的编号 pageSize: 每一页的大小 searchInfo: 需要全局查询的信息 """ def getMysqlData(tableName, pageNum, pageSize, searchInfo
-
python 解决mysql where in 对列表(list,,array)问题
例如有这么一个查询语句: select * from server where ip in (....) 同时一个存放ip 的列表 :['1.1.1.1','2.2.2.2','2.2.2.2'] 我们希望在查询语句的in中放入这个Ip列表,这里我们首先会想到的是用join来对这个列表处理成一个字符串,如下: >>> a=['1.1.1.1','2.2.2.2','2.2.2.2'] >>> ','.join(a) '1.1.1.1,2.2.2.2,2.2.2.2' 可
-
Python操作MySQL数据库的示例代码
1. MySQL Connector 1.1 创建连接 import mysql.connector config={ "host":"localhost","port":"3306", "user":"root","password":"password", "database":"demo" } con=
-
Python如何爬取51cto数据并存入MySQL
实验环境 1.安装Python 3.7 2.安装requests, bs4,pymysql 模块 实验步骤1.安装环境及模块 可参考https://www.jb51.net/article/194104.htm 2.编写代码 # 51cto 博客页面数据插入mysql数据库 # 导入模块 import re import bs4 import pymysql import requests # 连接数据库账号密码 db = pymysql.connect(host='172.171.13.229
-

python+selenium爬取微博热搜存入Mysql的实现方法
最终的效果 废话不多少,直接上图 这里可以清楚的看到,数据库里包含了日期,内容,和网站link 下面我们来分析怎么实现 使用的库 import requests from selenium.webdriver import Chrome, ChromeOptions import time from sqlalchemy import create_engine import pandas as pd 目标分析 这是微博热搜的link:点我可以到目标网页 首先我们使用selenium对目标网页进
-
python爬虫爬取网页数据并解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序. 只要浏览器能够做的事情,原则上,爬虫都能够做到. 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些朋友将某些网站上的图片全部爬取下来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以自动爬取一些金融信息,并进行投资分析等. 有时,我们比较喜欢的新闻网站可能有几个,每次都要分别
-
Python爬虫爬取疫情数据并可视化展示
目录 知识点 开发环境 爬虫完整代码 导入模块 分析网站 发送请求 获取数据 解析数据 保存数据 数据可视化 导入模块 读取数据 死亡率与治愈率 各地区确诊人数与死亡人数情况 知识点 爬虫基本流程 json requests 爬虫当中 发送网络请求 pandas 表格处理 / 保存数据 pyecharts 可视化 开发环境 python 3.8 比较稳定版本 解释器发行版 anaconda jupyter notebook 里面写数据分析代码 专业性 pycharm 专业代码编辑器 按照年份与月
-
Python实现爬取天气数据并可视化分析
目录 核心功能设计 实现步骤 爬取数据 风向风级雷达图 温湿度相关性分析 24小时内每小时时段降水 24小时累计降雨量 今天我们分享一个小案例,获取天气数据,进行可视化分析,带你直观了解天气情况! 核心功能设计 总体来说,我们需要先对中国天气网中的天气数据进行爬取,保存为csv文件,并将这些数据进行可视化分析展示. 拆解需求,大致可以整理出我们需要分为以下几步完成: 1.通过爬虫获取中国天气网7.20-7.21的降雨数据,包括城市,风力方向,风级,降水量,相对湿度,空气质量. 2.对获取的天气数
-
利用Python爬虫爬取金融期货数据的案例分析
目录 任务简介 解决步骤 代码实现 总结 大家好 我是政胤今天教大家爬取金融期货数据 任务简介 首先,客户原需求是获取https://hq.smm.cn/copper网站上的价格数据(注:获取的是网站上的公开数据),如下图所示: 如果以该网站为目标,则需要解决的问题是“登录”用户,再将价格解析为表格进行输出即可.但是,实际上客户核心目标是获取“沪铜CU2206”的历史价格,虽然该网站也有提供数据,但是需要“会员”才可以访问,而会员需要氪金...... 数据的价值!!! 鉴于,客户需求仅仅是“沪铜
-
python如何爬取网站数据并进行数据可视化
前言 爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做进一步的分析,其余分析和展示读者可自行发挥和扩展包括各种分析和不同的存储方式等..... 一.爬取和分析相关依赖包 Python版本: Python3.6 requests: 下载网页 math: 向上取整 time: 暂停进程 pandas:数据分析并保存为csv文件 matplotlib:
-
Python selenium爬取微博数据代码实例
爬取某人的微博数据,把某人所有时间段的微博数据都爬下来. 具体思路: 创建driver-----get网页----找到并提取信息-----保存csv----翻页----get网页(开始循环)----...----没有"下一页"就结束, 用了while True,没用自我调用函数 嘟大海的微博:https://weibo.com/u/1623915527 办公室小野的微博:https://weibo.com/bgsxy 代码如下 from selenium import webdrive
-
python Selenium爬取内容并存储至MySQL数据库的实现代码
前面我通过一篇文章讲述了如何爬取CSDN的博客摘要等信息.通常,在使用Selenium爬虫爬取数据后,需要存储在TXT文本中,但是这是很难进行数据处理和数据分析的.这篇文章主要讲述通过Selenium爬取我的个人博客信息,然后存储在数据库MySQL中,以便对数据进行分析,比如分析哪个时间段发表的博客多.结合WordCloud分析文章的主题.文章阅读量排名等. 这是一篇基础性的文章,希望对您有所帮助,如果文章中出现错误或不足之处,还请海涵.下一篇文章会简单讲解数据分析的过程. 一. 爬取的结果 爬
-
Python爬虫爬取全球疫情数据并存储到mysql数据库的步骤
思路:使用Python爬虫对腾讯疫情网站世界疫情数据进行爬取,封装成一个函数返回一个 字典数据格式的对象,写另一个方法调用该函数接收返回值,和数据库取得连接后把 数据存储到mysql数据库. 一.mysql数据库建表 CREATE TABLE world( id INT(11) NOT NULL AUTO_INCREMENT, dt DATETIME NOT NULL COMMENT '日期', c_name VARCHAR(35) DEFAULT NULL COMMENT '国家'